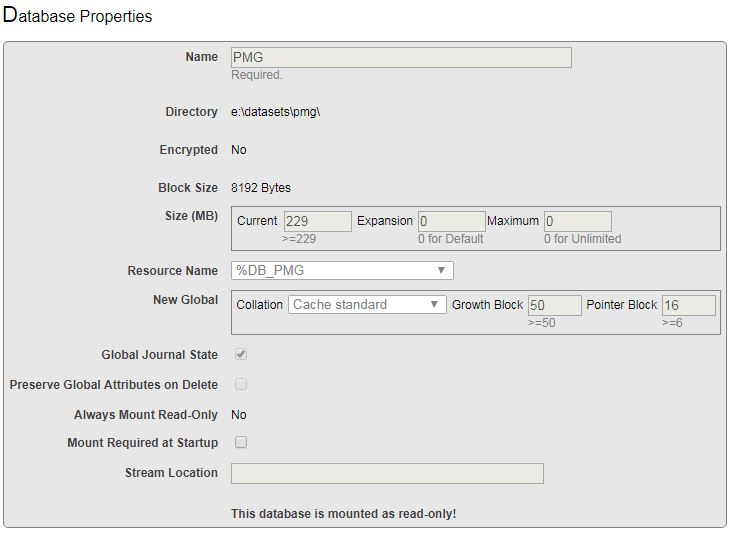
I have restored one database from backup, but when I query from some of tables, prompt error :
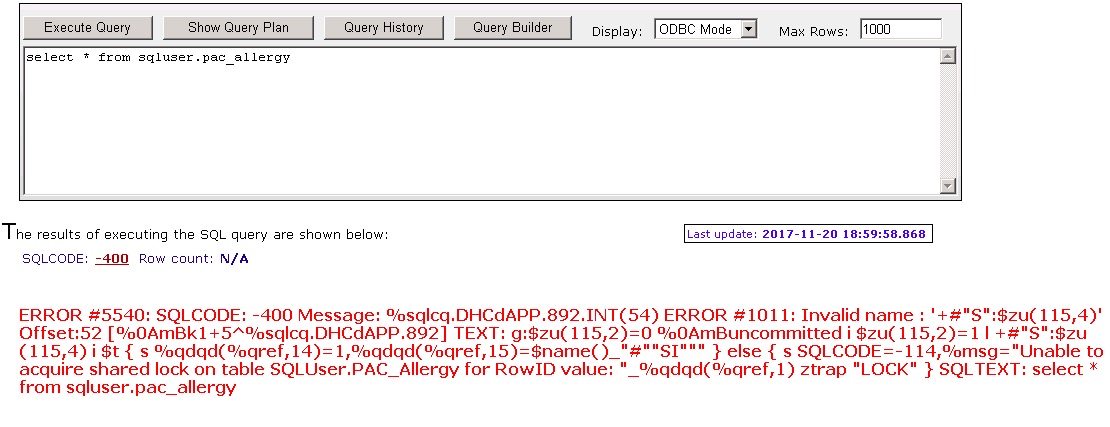 this error remain after restart Caché service
this error remain after restart Caché service
I can skip this error with %nolock in select query.
My question is:
1. why there were locks after restart service?
2. Can I release/rollback these locks by sql so I can query without %nolock?