In the good old days (tm) determining the size of the data, streams, and indices for a class/table was easy - you just ran %GSIZE and check D, S, and I globals respectively.
However, nowadays sharding, optimized global names, and indices in separate globals produce %GSIZE output looking like this:
This can be achieved by using the CSV() procedure of the %SQL.Util.Procedures class. Below is an example of usage code. (Assuming that the file test.csv is in c:\temp.)
I'm doing a query in SQL and I need to sort my data by some non-repeated field.
Unfortunately, my data is grouped in a way that I cannot guarantee that any column will not have repeated data, so one solution would be to take the row number.
Also, the Cache is not accepting Row_Number () in my querry and I would like to know if there is another solution to return line numbers or some way to add this function to the Cache.
In the vast and varied SQL database market, InterSystems IRIS stands out as a platform that goes way beyond just SQL, offering a seamless multimodel experience and supporting a rich set of development paradigms. Especially the advanced Object-Relational engine has helped organizations use the best-fit development approach for each facet of their data-intensive workloads, for example ingesting data through Objects and simultaneously querying it through SQL. Persistent Classes correspond to SQL tables, their properties to table columns and business logic is easily accessed using User-Defined Functions or Stored Procedures. In this article, we'll zoom in on a little bit of the magic just below the surface, and discuss how it may affect your development and deployment practices. This is an area of the product where we have plans to evolve and improve, so please don't hesitate to share your views and experiences using the comments section below.
The object and relational data models of the Caché database support three types of indexes, which are standard, bitmap, and bitslice. In addition to these three native types, developers can declare their own custom types of indexes and use them in any classes since version 2013.1. For example, iFind text indexes use that mechanism.
As Bill has mentioned earlier in his post, we have carefully reviewed the JSON capabilities and made some adjustments to ensure they deliver the best benefit to you. In this post, I am going to describe the modifications in more detail and provide guidance for you to understand the implication for your code base.
Thanks to @Yuri Marx we have seen a very nice example for DB migration from Postgres to IRIS. My personal problem is the use of DBeaver as a migration tool. Especially as one of the strengths of IRIS ( and also Caché) before is the availability of the SQLgateways that allow access to any external Db as long as for them an access usinig JDBC or ODBC is available. So I extended the package to demonstrate this.
Do not let the title of this article confuse you; we are not planning to take the InterSystems staff out to a fine Italian restaurant. Instead, this article will cover the principles of working with date and time data types in IRIS. When we use these data types, we should be aware of three different conversion issues:
Converting between internal and ODBC formats.
Converting between local time, UTC, and Posix time.
Converting to and from various date display formats.
The related package avoids adding %JSONAdaptor to each class but uses instead SQL functions JSON_OBJECT() to create my JSON objects. With this approach, you can add JSON to any class - even deployed ones - without any need for change or recompiling.
The trigger was the Export of M:N relationships as JSON objects or arrays.
Suppose you have an application that allows users to write posts and comment on them. (Wait... that sounds familiar...)
For a given user, you want to be able to list all of the published posts with which that user has interacted - that is, either authored or commented on. How do you make this as fast as possible?
Here's what our %Persistent class definitions might look like as a starting point (storage definitions are important, but omitted for brevity):
I'm facing a specific sort problem. There are several thousands of articles sold all over. Users expect to get a description in local language sorted by their specific collation.
This is the second piece in our series on 2021.2 SQL enhancements delivering an adaptive, high-performance SQL experience. In this article, we'll zoom in on the innovations in gathering Table Statistics, which are of course the primary input for the Run Time Plan Choice capability we described in the previous article.
This is the third article in our short series around innovations in IRIS SQL that deliver a more adaptive, high-performance experience for analysts and applications querying relational data on IRIS. It may be the last article in this series for 2021.2, but we have several more enhancements lined up in this area. In this article, we'll dig a little deeper into additional table statistics we're starting to gather in this release: Histograms
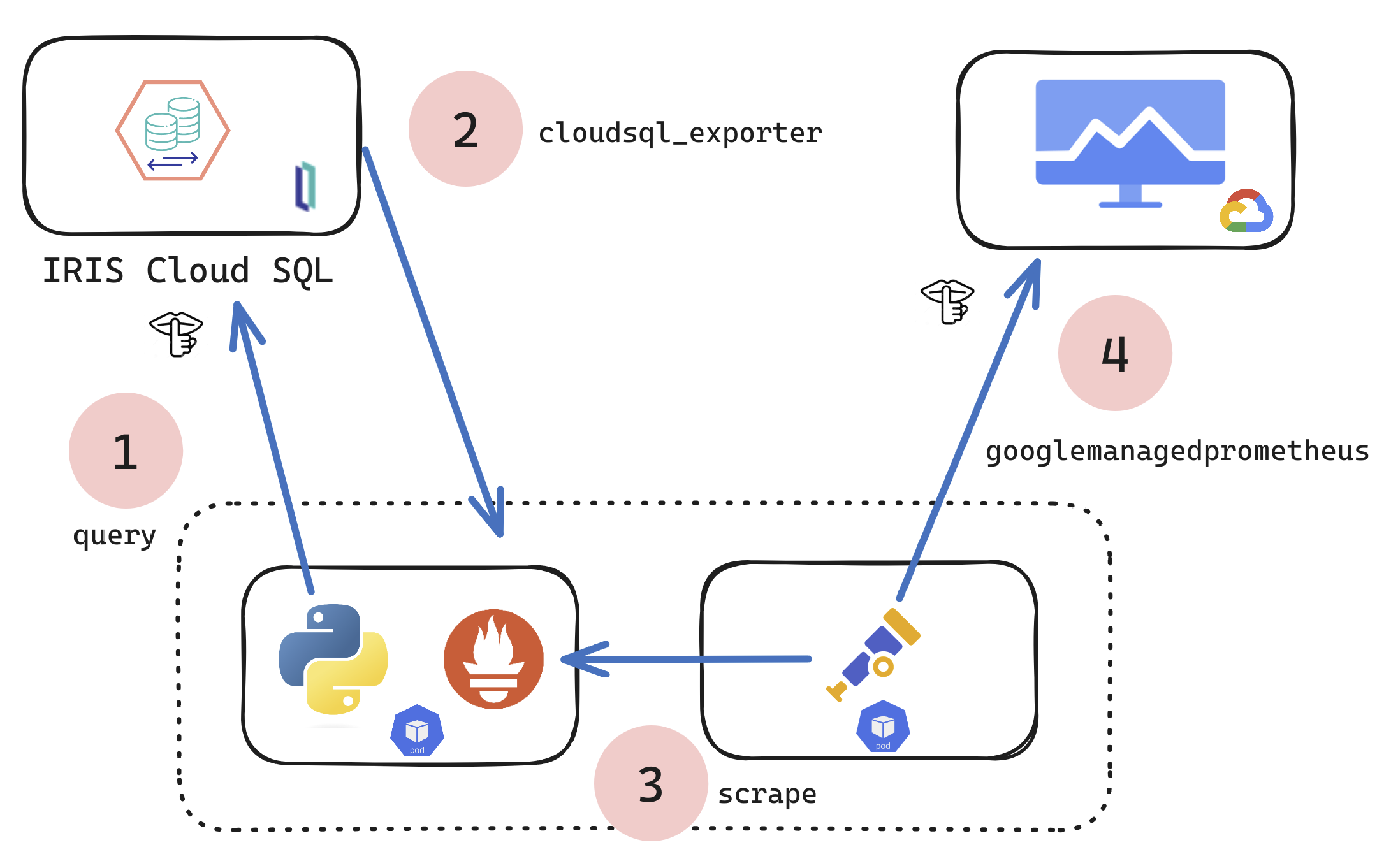
If you are a customer of the new InterSystems IRIS® Cloud SQL and InterSystems IRIS® Cloud IntegratedML® cloud offerings and want access to the metrics of your deployments and send them to your own Observability platform, here is a quick and dirty way to get it done by sending the metrics to Google Cloud Platform Monitoring (formerly StackDriver).
SQLTools is a Visual Studio Code (VS Code) Extension with over 3.5 million downloads that provides connections to many of the most used databases, including InterSystems IRIS, using drivers.
We have a yummy dataset with recipes written by multiple Reddit users, however most of the information is free text as the title or description of a post. Let's find out how we can very easily load the dataset, extract some features and analyze it using features from OpenAI large language model within Embedded Python and the Langchain framework.
In this article we are going to show the results of the comparision between IRIS and Postgress when handling Astronomy data.
Introduction
Since the earliest days of human civilization we have been fascinated by the sky at night. There are so many stars! Everybody has dreamed about them and fantasized about life in other planets.
With the release of InterSystems IRIS Cloud SQL, we're getting more frequent questions about how to establish secure connections over JDBC and other driver technologies. While we have nice summary and detailed documentation on the driver technologies themselves, our documentation does not go as far to describe individual client tools, such as our personal favourite DBeaver. In this article, we'll describe the steps to create a secure connection from DBeaver to your Cloud SQL deployment.
If you are looking to breathe new life into an old MUMPS application follow these steps to map your globals to classes and expose all that beautiful data to Objects and SQL.
This example is going to cram in 4 or 5 different things beyond what was covered in Part 1
This article describes a significant enhancement of how InterSystems IRIS deals with table statistics, a crucial element for IRIS SQL processing, in the 2025.2 release. We'll start with a brief refresher on what table statistics are, how they are used, and why we needed this enhancement. Then, we'll dive into the details of the new infrastructure for collecting and saving table statistics, after which we'll zoom in onto what the change means in practice for your applications. We'll end with a few additional notes on patterns enabled by the new model, and look forward to the follow-on phases of this initial delivery.
Nowadays so much noise around LLM, AI, and so on. Vector databases are kind of a part of it, and already many different realizations for the support in the world outside of IRIS.
Why Vector?
Similarity Search: Vectors allow for efficient similarity search, such as finding the most similar items or documents in a dataset. Traditional relational databases are designed for exact match searches, which are not suitable for tasks like image or text similarity search.
Flexibility: Vector representations are versatile and can be derived from various data types, such as text (via embeddings like Word2Vec, BERT), images (via deep learning models), and more.
Cross-Modal Searches: Vectors enable searching across different data modalities. For instance, given a vector representation of an image, one can search for similar images or related texts in a multimodal database.
And many other reasons.
So, for this pyhon contest, I decided to try to implement this support. And unfortunately I did not manage to finish it in time, below I'll explain why.
What I find really useful about IRIS when teaching my subject of Postrelational databases is the fact that it is a multi model database. Which means that I can actually go into architecture and structure and all that only once but then show the usage of different models (like object, document, hierarchy) using the same language and approach. And it is not a huge leap to go from an object oriented programming language (like C#, Java etc) to an object oriented database.
However, along with advantages (which are many) come some drawbacks when we switch from object oriented model to relational. When I say that you can get access to the same data using different models I need to also explain how it is possible to work with lists and arrays from object model in relational table. With arrays it is very simple - by default they are represented as separate tables and that's the end of it. With lists - it's harder because by default it's a string. But one still wants to do something about it without damaging the structure and making this list unreadable in the object model.
So in this article I will showcase a couple of predicates and a function that are useful when working with lists, and not just as fields.
 By likes
By likes Open Exchange app
Open Exchange app
.png)