By likes
By likes
Hi Community,
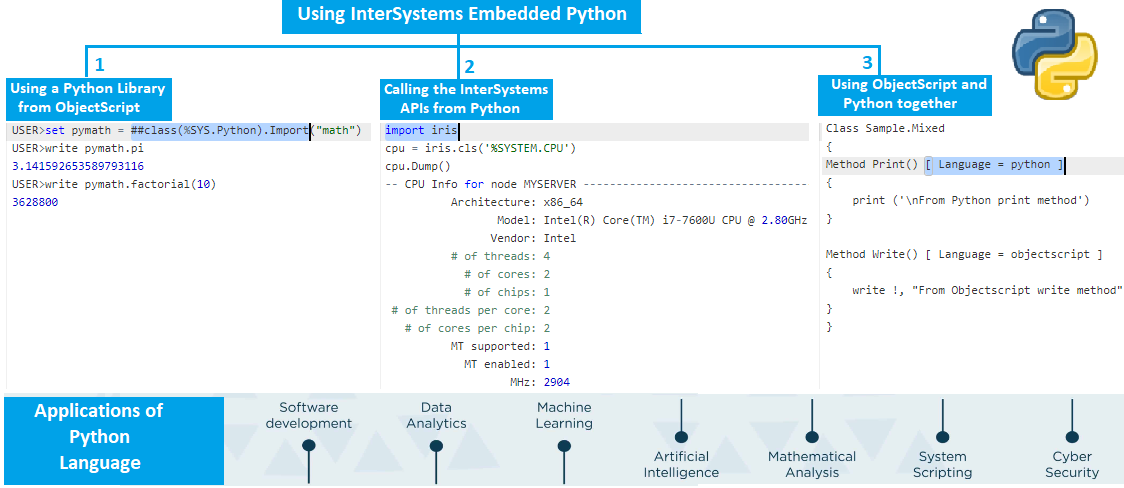
In this article I will demonstrate the usage of InterSystems Embedded Python, We will cover below topics:
.png)
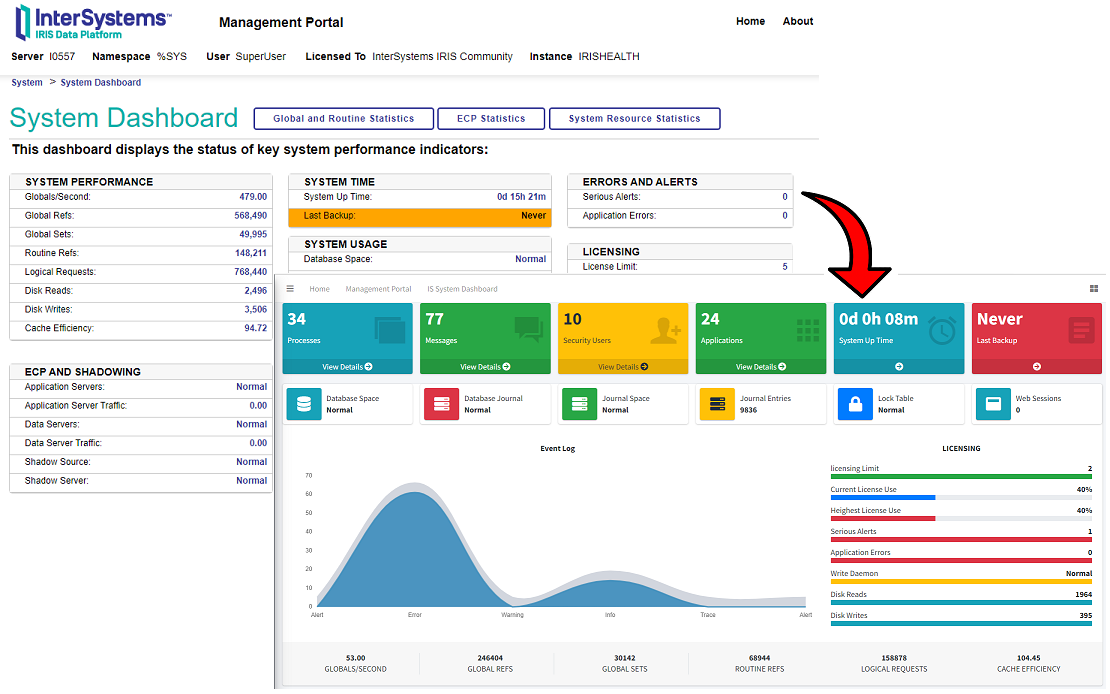
InterSystems IRIS for Health™ is the world’s first and only data platform engineered specifically for the rapid development of healthcare applications to manage the world’s most critical data. It includes powerful out-of-the-box features: transaction processing and analytics, an extensible healthcare data model, FHIR-based solution development, support for healthcare interoperability standards, and more. All enabling developers to realize value and build breakthrough applications, fast. Learn more.
 Open Exchange app
Open Exchange app