Today I would like to address a subject that has given me a hard time. I am sure this must have been the case for quite a number of you already (so-called “the bottleneck”). Since this is a broad topic, this article will only focus on identifying incoming HTTP requests that could be causing slowness issues. I will also provide you with a small tool I have developed to help identify them.
Our software is becoming more and more complex, processing a large number of requests from different sources, be it front-end or third-party back-end applications. To ensure optimal performance, it is essential to have a logging system capable of taking a few key measurements, such as the response time, the number of global references and the number of lines of code executed for each HTTP response. As part of my work, I get involved in the development of EMR software as well as incident analysis. Since user load comes mostly from HTTP requests (REST API or CSP application), the need to have this type of measurement when generalized slowness issues occur has become obvious.
IRIS External Table is an InterSystems Community Open Source Project, that allows you to use files, stored in the local file system and cloud object storage such as AWS S3 as SQL Tables.
If you're running IRIS in a mirrored configuration for HA in AWS, the question of providing a Mirror VIP (Virtual IP) becomes relevant. Virtual IP offers a way for downstream systems to interact with IRIS using one IP address. Even when a failover happens, downstream systems can reconnect to the same IP address and continue working.
While the classic solution followed rather close the concepts and design of the ancestors Caché / IRIS allows a more modern approach to flexible/multidimensional properties
One of the reasons why I love Cache and Iris is that not only you can do anything you can imagine, also you can do it in a lot of different ways!!.
Imagine that you have an integration running with IRIS connected by ODBC you probably only run SQL queries but you can also create stored procedures and inside write the code to do everything you can imagine.
I'm going to give you some examples but the limit is your imagination!!
Over the years, I have found myself needing to create multiple HL7 messages based on a single inbound message. Usually these take the form of an order or result from a lab. Each time I have approached it, I have tried to start from scratch under the belief that the previous attempt could have been done better.
YASPE is the successor to YAPE (Yet Another pButtons Extractor). YASPE has been written from the ground up with many internal changes to allow easier maintenance and enhancements.
YASPE functions:
Parse and chart InterSystems Caché pButtons and InterSystems IRIS SystemPerformance files for quick performance analysis of Operating System and IRIS metrics.
Allow a deeper dive by creating ad-hoc charts and by creating charts combining the Operating System and IRIS metrics with the "Pretty Performance" option.
The "System Overview" option saves you from searching your SystemPerformance files for system details or common configuration options.
YASPE is written in Python and is available on GitHub as source code or for Docker containers at:
We are ridiculously good at mastering data. The data is clean, multi-sourced, related and we only publish it with resulting levels of decay that guarantee the data is current. We chose the HL7 Reference Information Model (RIM) to land the data, and enable exchange of the data through Fast Healthcare Interoperability Resources (FHIR®).
Docker 20.10.14 (released March 23, 2022) changes the Linux capabilities given to containers in a manner that is incompatible with the Linux capability checker in InterSystems IRIS 2021.1 (and up) containers.
Users running Docker 20.10.14 on Linux will find that IRIS 2021.1+ containers will fail to start and the logs will incorrectly report that required Linux capabilities are missing. For example:
We are Longevica (https://www.longevica.com/) Healthtech, a Boston-based healthy aging digital health startup. Longevica was born as a research company back in 2009; we pioneered the screening of chemicals, which would drastically extend the life span. With 1000 screened pharmaceuticals and 20 000 mice experiments, we have identified specific compounds that, if taken daily, could extend life by years. This discovery leads to two questions: how to measure the effect of aging progress in real-time and how to make this a lifelong habit. This led us to the digital health market to create a new company Longevica HealthTech.
As we all know, Caché is a great database that accomplishes lots of tasks within itself. However, what do you do when you need to access an external database? One way is to use the Caché SQL Gateway via JDBC. In this article, my goal is to answer the following questions to help you familiarize yourself with the technology and debug some common problems.
In this article, I would like to talk about the spec-first approach to REST API development.
While traditional code-first REST API development goes like this:
Writing code
REST-enabling it
Documenting it (as a REST API)
Spec-first follows the same steps but reverse. We start with a spec, also doubling as documentation, generate a boilerplate REST app from that and finally write some business logic.
This is advantageous because:
You always have relevant and useful documentation for external or frontend developers who want to use your REST API
Specification created in OAS (Swagger) can be imported into a variety of tools allowing editing, client generation, API Management, Unit Testing and automation or simplification of many other tasks
Improved API architecture. In code-first approach, API is developed method by method so a developer can easily lose track of the overall API architecture, however with the spec-first developer is forced to interact with an API from the position if API consumer which usually helps with designing cleaner API architecture
Faster development - as all boilerplate code is automatically generated you won't have to write it, all that's left is developing business logic.
Faster feedback loops - consumers can get a view of the API immediately and they can easier offer suggestions simply by modifying the spec
The InterSystems Iris Fhirserver running on a Raspberry Pi Raspberry running as a FHIRserver
Raspberry running as FHIRserver
About a year ago I wrote some articles about the installation of the HAPI FHIRserver on a Raspberry Pi. At that time, I only knew the basics of the FHIR standard, little about the technology behind FHIR-servers and not much more about the Raspberry. By trying, failing, giving up and trying again I learned a lot.
The 2021.2 release of the InterSystems IRIS Data Platform includes many exciting new features for fast, flexible and secure development of your mission-critical applications. Embedded Python definitely takes the limelight (and for good reason!), but in SQL we've also made a massive step forward towards a more adaptive engine that gathers detailed statistical information about your table data and exploits it to deliver the best query plans. In this brief series of articles, we'll take a closer at three elements that are new in 2021.2 and work together towards this goal, starting with Run Time Plan Choice.
It's hard to figure out the right order to talk about these (you can't imagine how often I've reshuffled them in writing this article!) because they fit together in such a nice way. As such, feel free to go on a limb and read these in random order .
Working in support, I usually get asked how many days I should keep journals. Should it be two days or after two backups? More? Less? Why two?
The correct answer (for most of the environments) is that you should keep the journals since the last validated Backup. I.e., until you don't check if a Backup is valid (restoring the file and checking with the Integrity utility), you can't be sure there is a good copy of your data and can't purge the journals safely.
$LIST string format and %DynamicArray and %DynamicObject classes
IRIS, and previously Cache, contain several different ways to create a sequence containing a mixture of data values. A data sequence that has been available for many years is the $LIST string. Another more recent data sequence is the %DynamicArray class, which along with the %DynamicObject class, is part of the IRIS support for JSON string representation. These two sequences involve very different tradeoffs.
During my search for a snapshot of a persistent object, I met a feature that I would like to share as it could be useful in some special situations. My trigger was to have a before- and an after-image during unit testing.
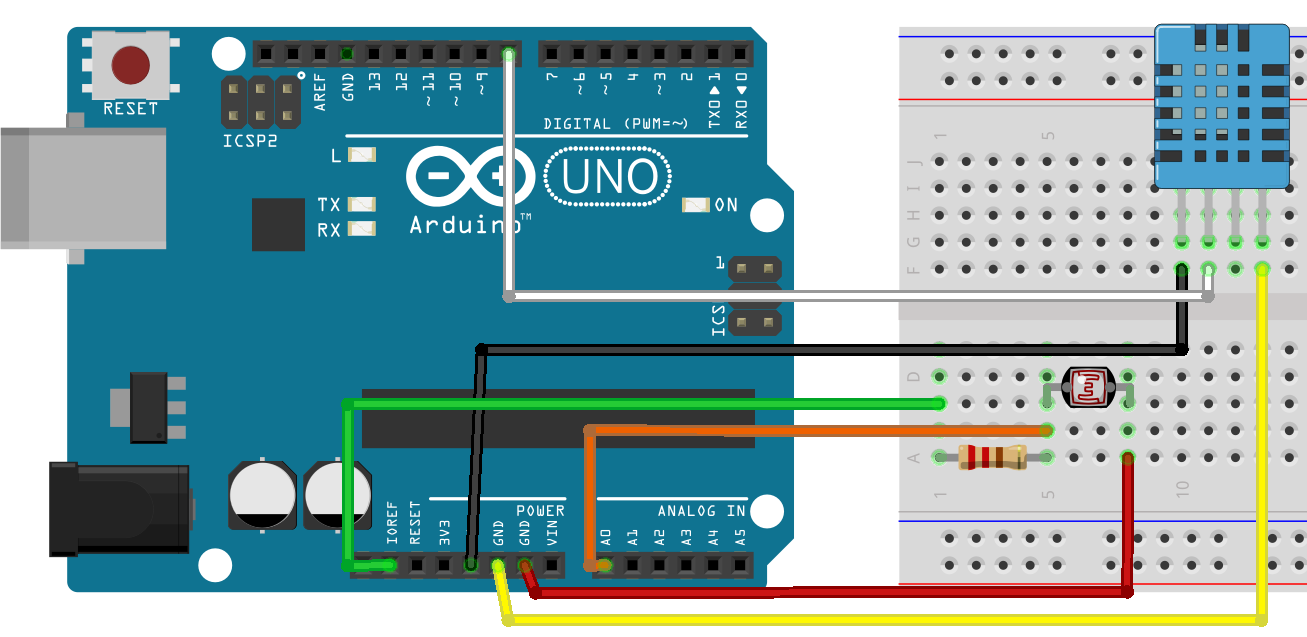
It was InterSystems hackathon time and our team, consisting of Artem Viznyuk and me had Arduino board (one) and various parts of it (in overabundance). And so like that our course of action was set - like all other Arduino beginners, we decided to build a weather station. But with data persistent storage in Caché and visualization in DeepSee!
The common requirement in many applications is logging of data changes in a database - which data has changed, who changed them and when (audit logging). There are many articles about this question and there are different approaches on how to do that in Caché.
https://www.youtube.com/embed/3KClL5zT6MY [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
https://www.youtube.com/embed/cuMLSO9NQCM [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
Extracting and plotting pButtons data including timeframes and iostat.
This was written based on a previous trial in .XLS It is far from being perfect. Rather a challenge for improvement in all directions (code, interface, ...) So anyone feel invited to make it better.
 By update
By update Open Exchange app
Open Exchange app

.png)
.jpg)
.png)

 .
.