All time
All time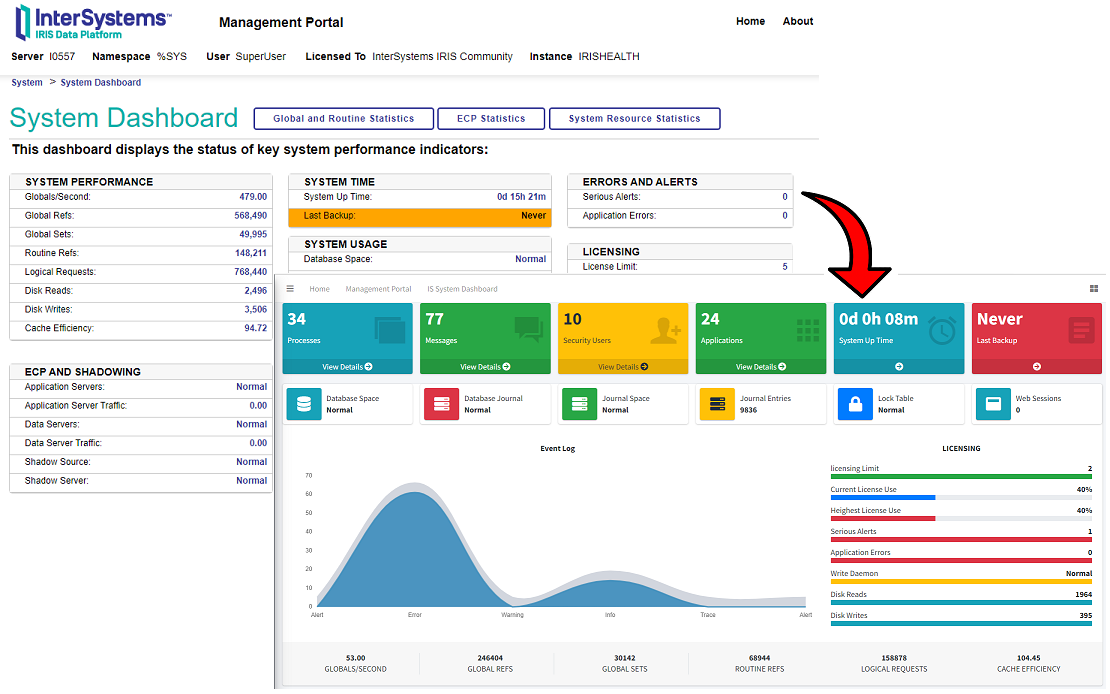
 Open Exchange app
Open Exchange appHello,
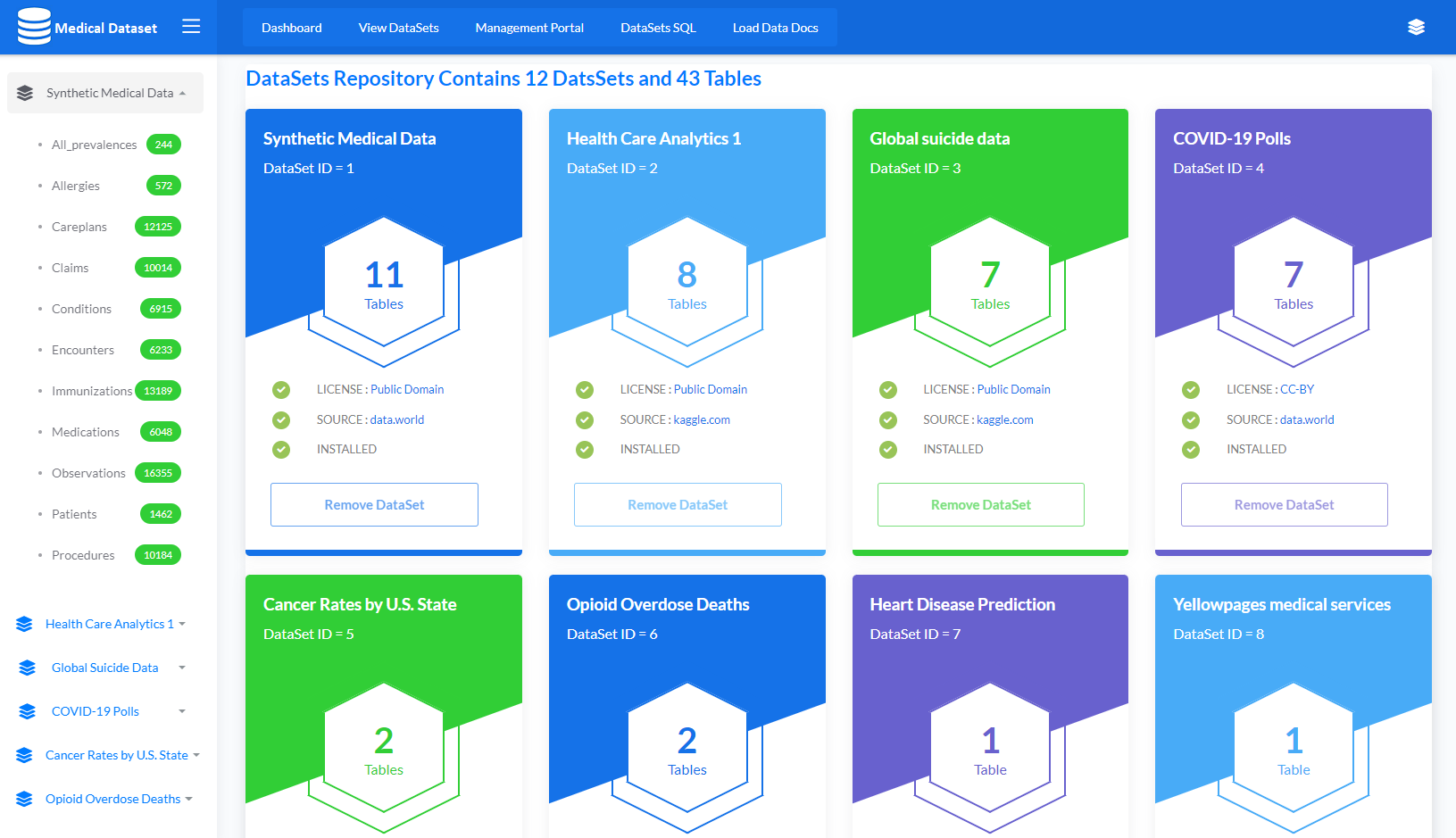
We are sometimes asked for examples of how to do 3rd party SQL database selects/updates/inserts/stored procedures from an Ensemble SQL Business Operation.
In the attached file there are 4 sample Ensemble Operations that demonstrate four different types of transactions with an external SQL DB: