InterSystems Caché database is a file where all the data, application scripts, and users, roles and security configurations are stored. Typically the name of the file is cache.dat.
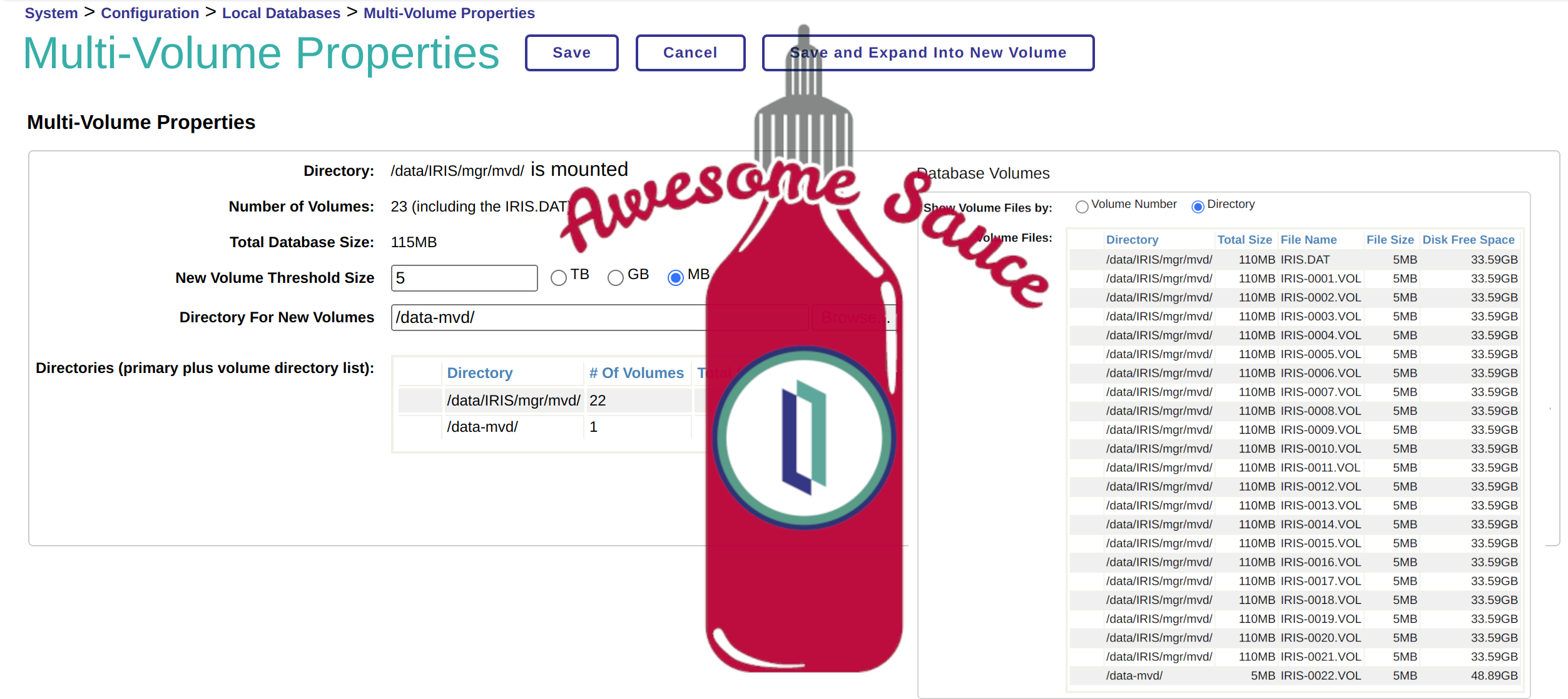
Data for InterSystems products (table row data, object instance data) is stored in global variables. The data size of each global can be obtained by clicking the properties of the global you want to view from the Management Portal > System > Configuration > Local Database > Globals page, and then clicking the Calculate Size button on the Global Attributes page that appears. To display the data sizes of globals in a namespace, you can call ^%GSIZE utility on the terminal.
Hello everyone, I’m a French student that just arrived in Prague for an academical exchange for my fifth year of engineering school and here is my participation in the interop contest.
I hadn’t much time to code since I was moving from France to Prague and I’m participating alone, so I decided to make a project that’s more like a template rather than an application.
to dismount/mount a database, use Dismount() and Mount() methods in SYS.Database class available in %SYS namespace. NB: the database ID is its Directory
You'll find some examples of how to dismount/mount and check if a database is mounted (Mounted=1) or not (Mounted=0), and quickly see all the attributes of a database (via zwrite)
I am planning to implement Business Intelligence based on the data in my instances. What is the best way to set up my databases and environment to use DeepSee?
I am talking from Brazil and we have one very important customer that requested our support to find a consultant, deeply specialized in Cache that could work with us attending this customer. It has a tons of data and its core application is based on Cache.
If you are interested send me an email with the subject title - Cache consultant opportunity - and we will make contact with you. The main request is how strong are your skills in cache and it would be considered a differentiator if you are a portuguese speaker.
Caché Monitor is a database\sql tool primarily for InterSystems Caché but can also connect to MS SQL Server, MS Access and more databases. Within Caché Monitors Server Navigator you see all available Namespaces on your Caché Servers. No need to know the name of the Namespace, no need to configure many many JDBC Connections by hand. Just click on the namespace and see all objects like tables, views, classes and more...
The following post is a guide to implement a basic architecture for DeepSee. This implementation includes a database for the DeepSee cache and a database for the DeepSee implementation and settings.
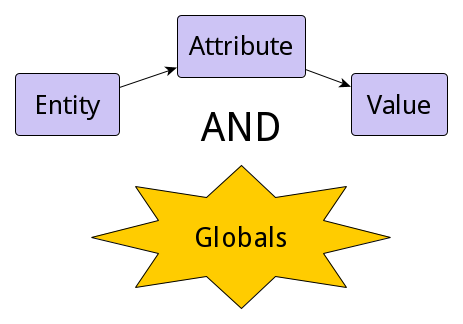
In the first article in this series, we’ll take a look at the entity–attribute–value (EAV) model in relational databases to see how it’s used and what it’s good for. Then we'll compare the EAV model concepts to globals.
Is there something in Cache that is equivalent to partitioning a table in Oracle? I'm trying to break some big tables into groups so that the most frequently accessed data is faster to retrieve.
Here is some information on this concept from Oracle.
https://www.youtube.com/embed/Eb5kPw8-l08 [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
I'm creating a new namespace by the installation manifest XML and in the "database" tag configuration I don't see attribute to configure if I what jounal globals or not to this database.
In the database wizard of the "portal administration", have this option.
In this article I'd like to share with you a phenomena that is best you avoid - something you should be aware of when designing your data model (or building your Business Processes) in Caché or in Ensemble (or older HealthShare Health Connect Ensemble-based versions).
I am accessing IRIS databases with JDBC (or ODBC) using Python. I want to fetch the data into a pandas dataframe to manipulate the data and create charts from it. I ran into a problem with string handling while using JDBC. This post is to help if anyone else has the same issues. Or, if there is an easier way to solve this, let me know in the comments!
I am using OSX, so I am unsure how unique my problem is. I am using Jupyter Notebooks, although the code would generally be the same if you used any other Python program or framework.
In the modern world, the most valuable asset for companies is their data. Everything from business processes and applications to transactions is based on data which defines the success of the organization's operations, analysis, and decisions. In this scenario, the data structures need to be ready for frequent changes, yet in a managed and governed way. Otherwise, we will inevitably lose money, time, and quality of corporate solutions.
In this GitHub we gather information from a csv, use a DataTransformation to make it into a FHIR object and then, save that information to a FHIR server all that using only Python.
The objective is to show how easy it is to manipulate data into the output we want, here a FHIR Bundle, in the IRIS full Python framework.
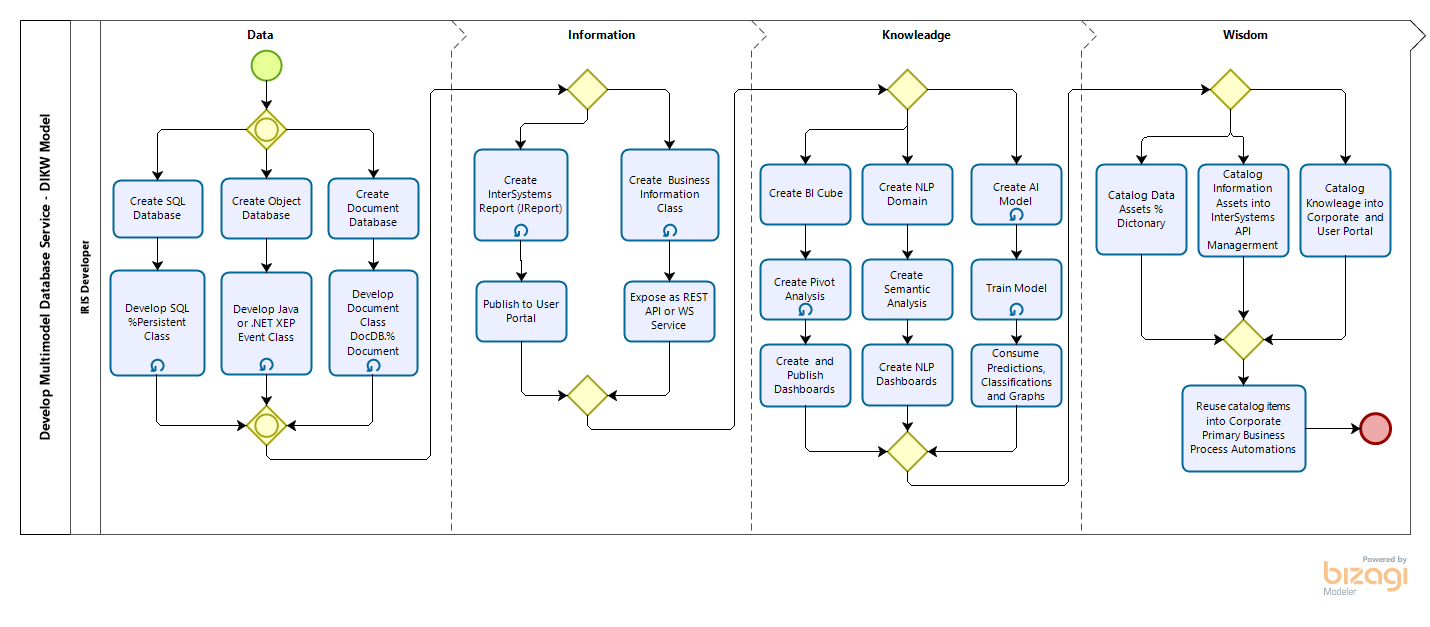
The InterSystems IRIS has functions that allows create DIWK digital services. A few products have the ability to transform data into wisdom, according to the following pyramid.
For the recent contest, I've added a new feature, the ability to generate a static picture of any Cache or IRIS database. Like below. Where unique globals have a unique color. This is how looks like inside 9.5GB database. Where 1 pixel represents one block. By link on image you will get even bigger image, with more detalization.
 By likes
By likes
 Open Exchange app
Open Exchange app