Internal Structure of Caché Database Blocks, Part 3
This is the third article (see Part 1 and Part 2) where I continue to introduce you to the internal structure of Caché databases. This time, I will tell you a few interesting things and explain how my Caché Blocks Explorer project can help make your work more productive.
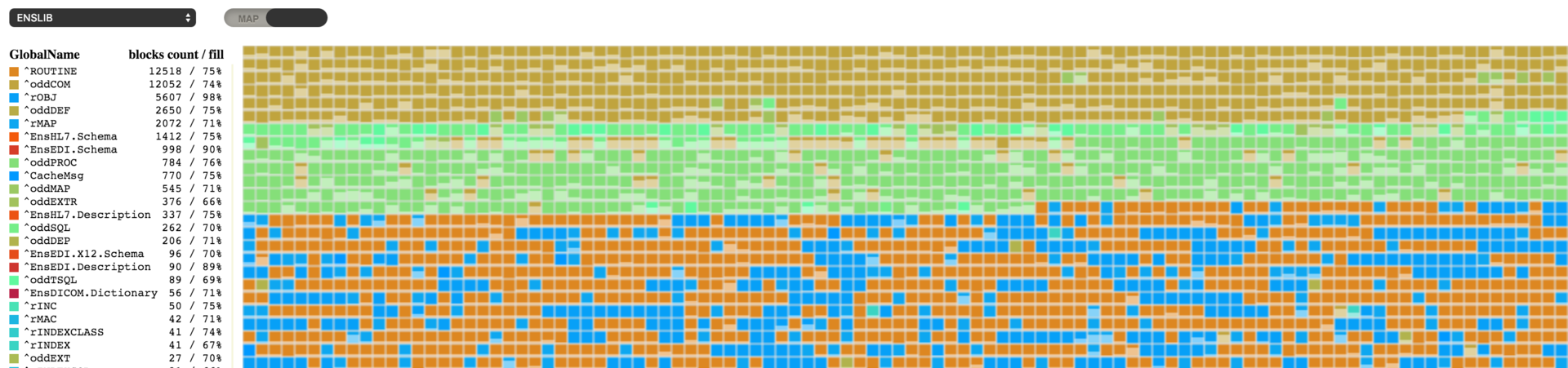
I think many of you will recognize what is shown in the picture (clickable). When I needed to visualize the fragmentation of globals, various disk defragmentation tools were first to cross my mind. And, I hope, I managed to make a product that is just as useful as they are.
This utility displays a map of blocks. Each square represents a block, and its color corresponds to a particular global listed in the legend section. The block itself also shows how full of data it is, which helps you quickly estimate the fullness of the entire database with a single glimpse at the map. The display of global- and map-level blocks is not yet implemented – like all empty blocks, they will be shown in white.
You can select a database and the map of blocks will start loading immediately. Information is not loaded sequentially, but according to the order of blocks in the block tree, so the process may look like something shown in the image below.
Let’s continue working with the database that we used in the previous article. I have removed all the globals, as we won’t need them. I have also generated new data based on the Sample class package from the SAMPLES database. To achieve this, I configured package mapping to my namespace called HABR.

Ran a data generation command.
do ##class(Sample.Utils).Generate(20000)I’ve got the following result on our map:

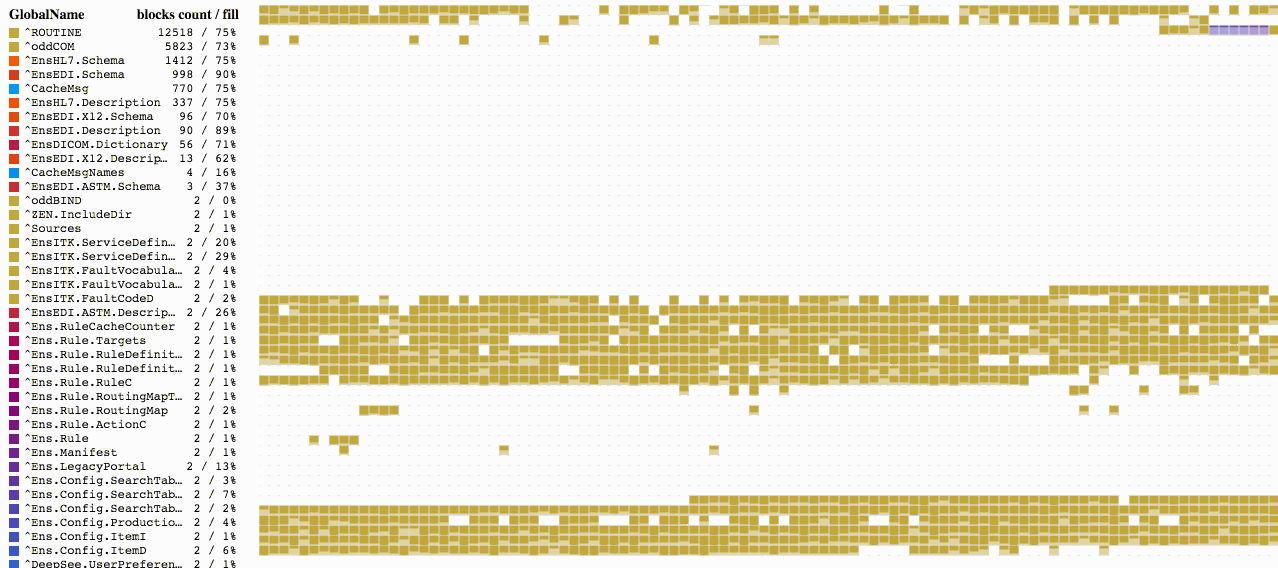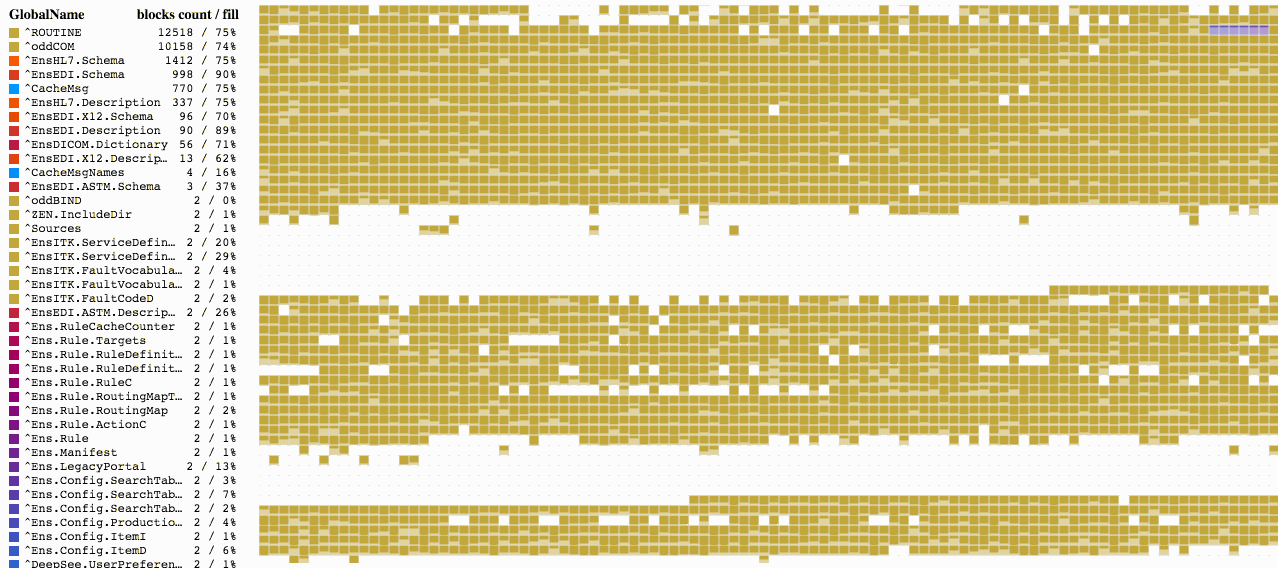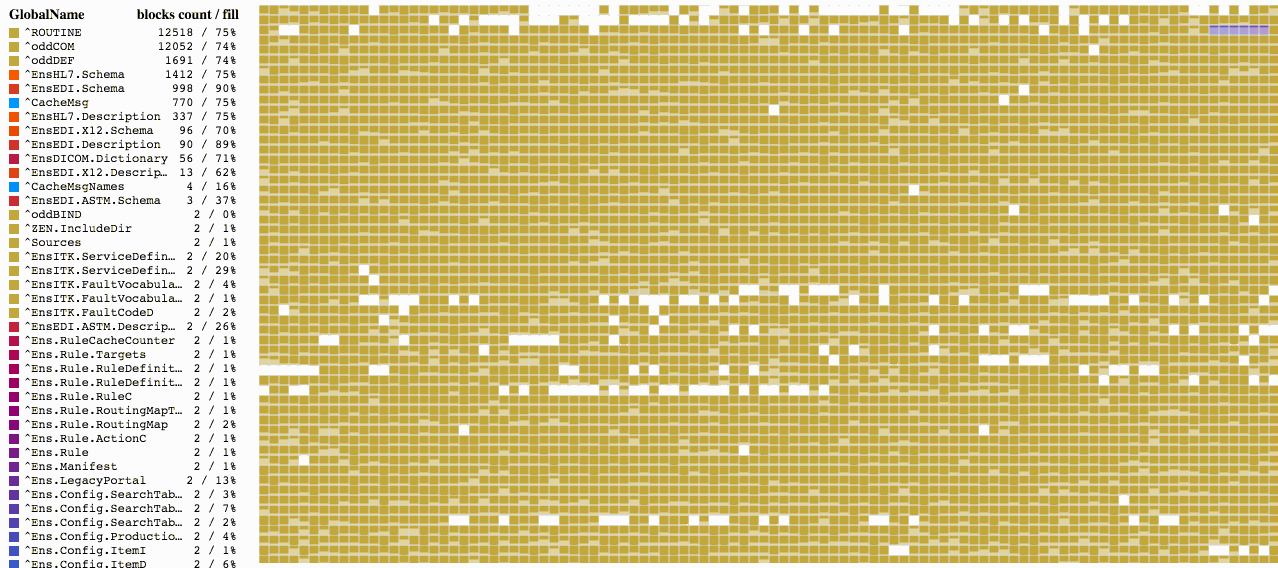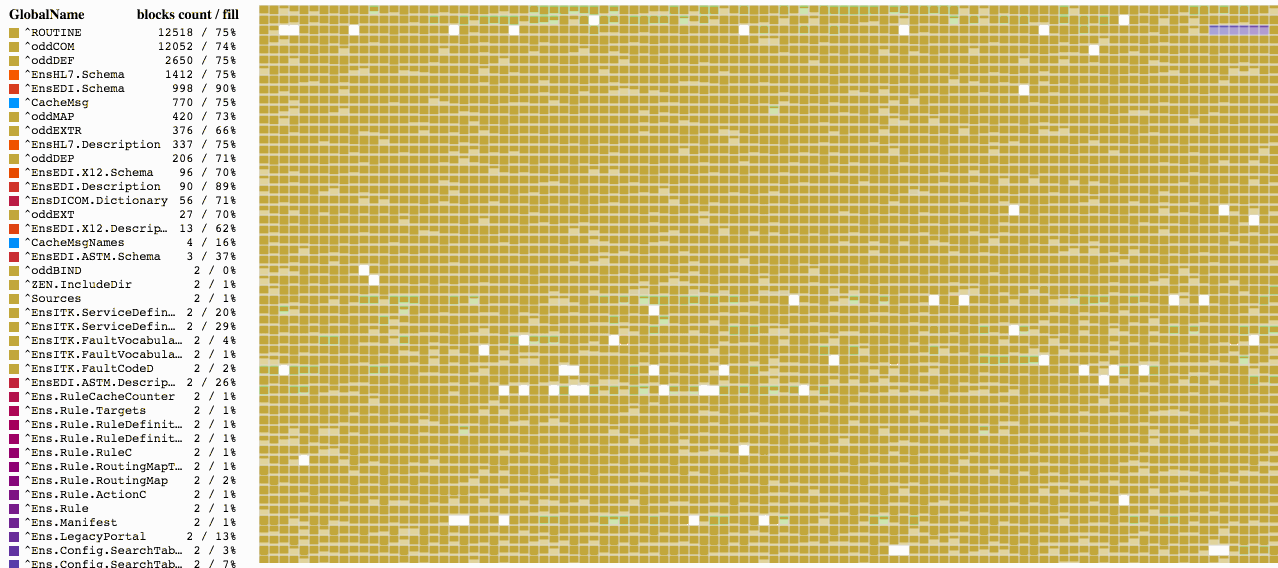
You may notice that blocks start to get filled not from the start of the file. Starting from block 16, we see top-level pointer blocks, and from block 50 – data blocks. 16 and 50 are default values, but they can be changed, if necessary. The start of the pointer block is defined in the NewGlobalPointerBlock property of the SYS.Database class; it sets the default value for new globals. For existing globals, it can be changed in the %Library.GlobalEdit class via the PointerBlock property. The block that will start the sequence of data blocks is specified in the NewGlobalGrowthBlock property of the SYS.Database class. The GrowthBlock property of the %Library.GlobalEdit class does the same for individual globals. It makes sense to change these properties only for those globals that contain no data yet since these changes have no effect on the current position of the top pointers block or data blocks.
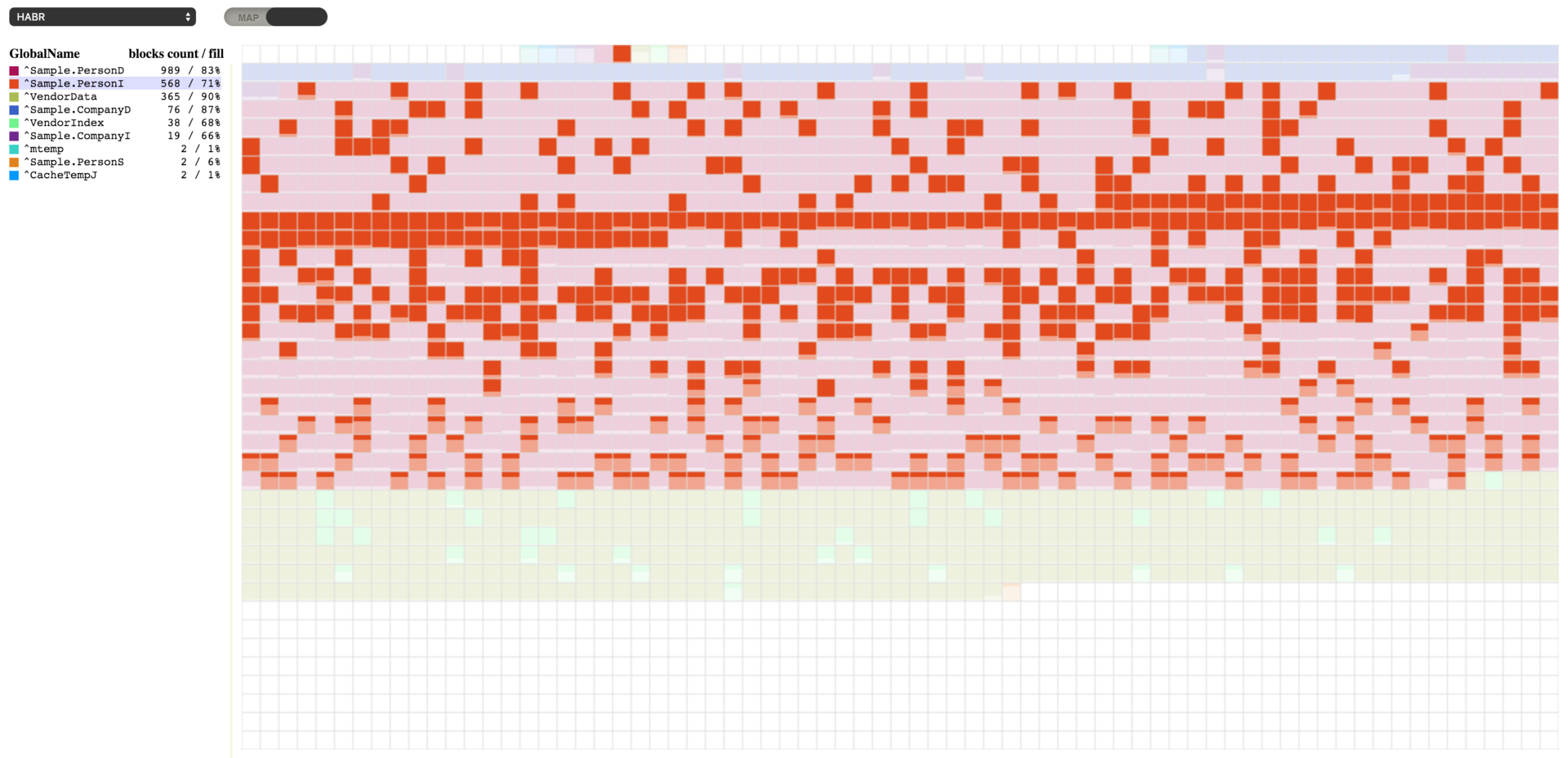
We can see here that the ^Sample.PersonD global with 989 blocks is 83% full, followed by the ^Sample.PersonI global with 573 blocks (70% full). We can pick any global to see the blocks allocated for it. And if we pick the ^Sample.PersonI global, we will see that some blocks are almost empty. We will also see that blocks belonging to these two globals are intermixed. There is a reason for it. When new objects are created, both globals are filled: one with data and the other one with indices for the Sample.Person table.
Now that we have some test data, we can take advantage of the database management capabilities offered by Caché and see the result. For starters, let’s trim our data a bit to create an illusion of activity that may add and remove data. Let’s execute some code that will remove some random data.
set id=""
set first=$order(^Sample.PersonD(""),1)
set last=$order(^Sample.PersonD(""),-1)
for id=first:$random(5)+1:last {
do ##class(Sample.Person).%DeleteId(id)
}
When you run this code, you will see the result shown below. We have some empty blocks, while other blocks are 64-67% full.

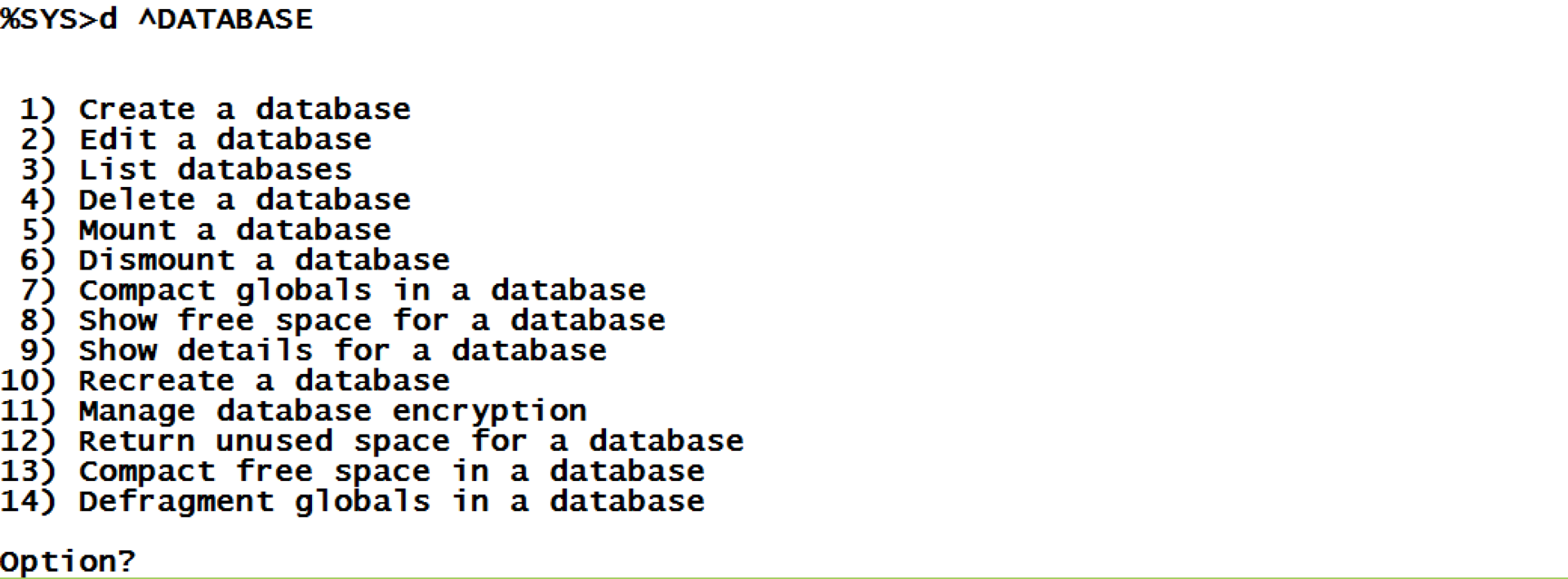
We can use the ^DATABASE tool from the %SYS namespace to work with our database. Let’s use some of its capabilities.
First of all, since we have barely filled blocks, let’s compress all the globals in the database and see how it goes.
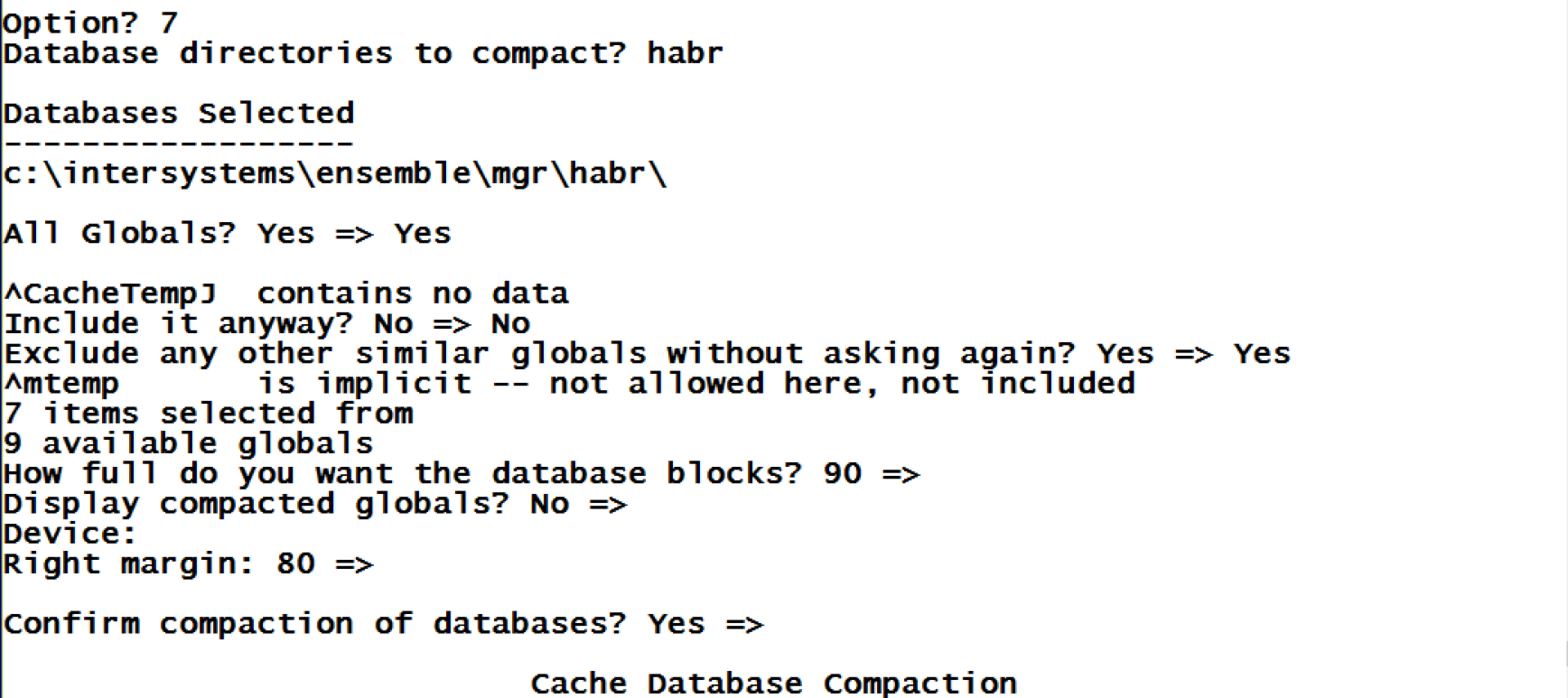

As you see, compression allowed us to get as close to the necessary 90% fill value as possible. As the result, previously empty blocks are now full of data relocated from other blocks. Database globals can be compressed using the ^DATABASE tool (item 7) or using the following command with the path to the database passed as the first parameter:
do ##class(SYS.Database).CompactDatabase("c:\intersystems\ensemble\mgr\habr\")We can also move all empty blocks to the end of the database. This may be needed, for instance, after you remove a large chunk of data and want to compact the database afterward. To demonstrate this, let’s repeat the removal of data from our test database.
set gn=$name(^Sample.PersonD)
set first=$order(@gn@(""),1)
set last=$order(@gn@(""),-1)
for i=1:1:10 {
set id=$random(last)+first
write !,id
set count=0
for {
set id=$order(@gn@(id))
quit:id=""
do ##class(Sample.Person).%DeleteId(id)
quit:$increment(count)>1000
}
}Here’s what I got after data removal.

We can see some empty blocks here. Caché allows you to move these empty blocks to the end of the database file and then compact it. To move the empty blocks, let’s use the FileCompact method from the SYS.Database class in the system namespace or resort to the ^DATABASE tool (item 13). This method accepts three parameters: path to the database, desirable amount of free space at the end of the file (0 by default), and the return parameter – resulting amount of free space.
do ##class(SYS.Database).FileCompact("c:\intersystems\ensemble\mgr\habr\",999)And here's what we got: no empty blocks. The ones at the beginning don’t count, as they are there according to the settings (where to start upper top-level pointer and data blocks).
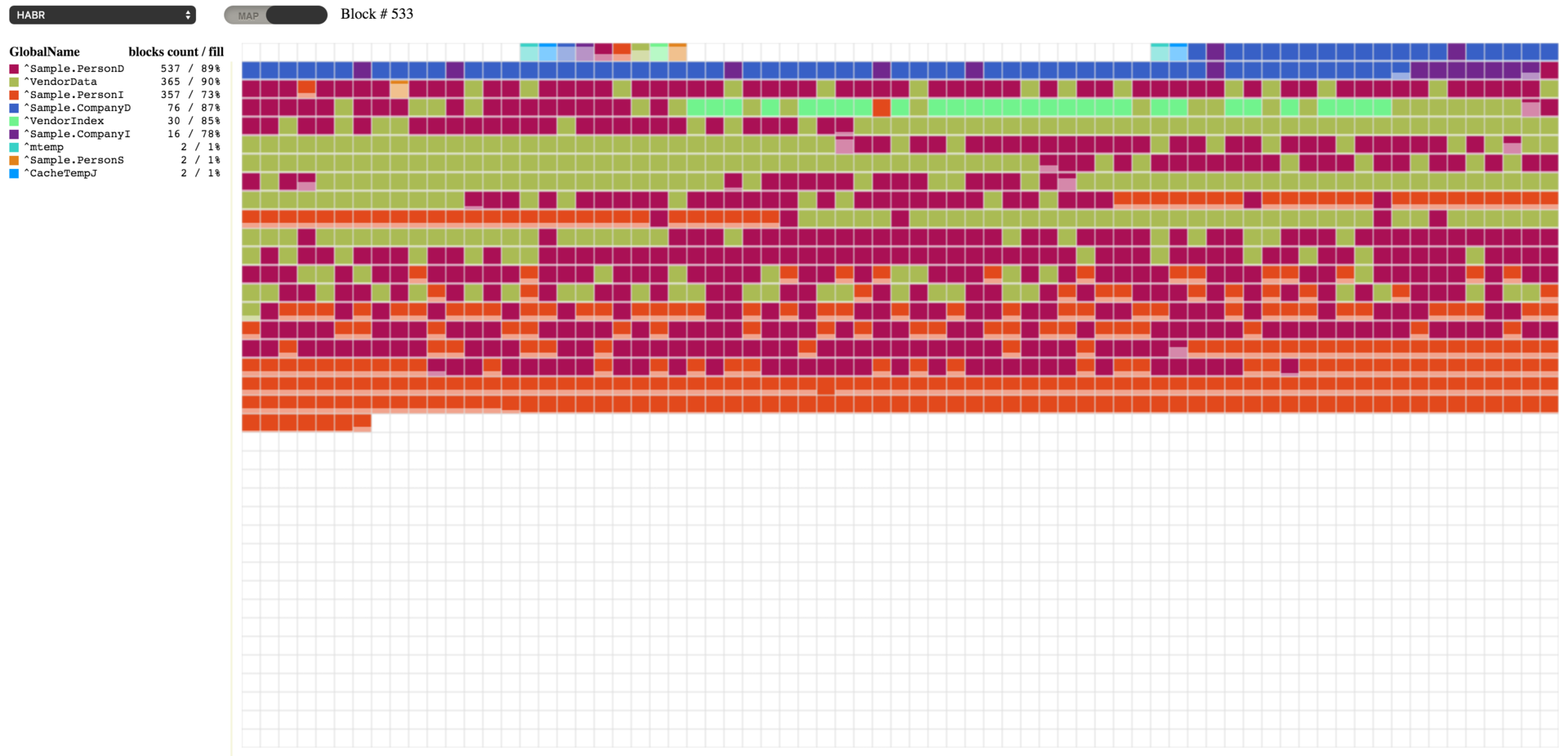
Defragmentation
We can now proceed to defragment our globals. This process will rearrange the blocks of each global in a different order. Defragmentation may require some free space at the end of the database file, so it may be added if the situation requires it. The process may be started via item 14 of the ^DATABASE tool or using the following command:
d ##class(SYS.Database).Defragment("c:\intersystems\ensemble\mgr\habr\")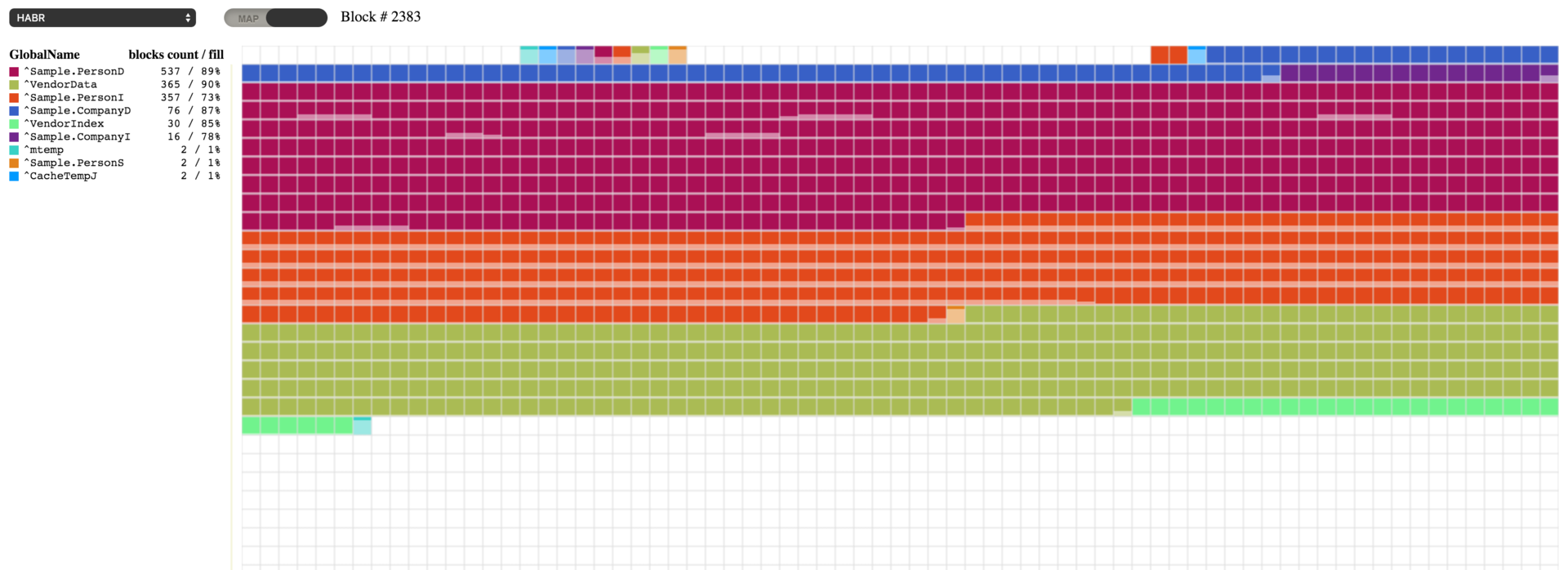
Freeing up disk space
We can now see our globals lined up. However, it looks like defragmentation used some more extra space in the database file. We can free up this space using item 12 of the ^DATABASE tool or the following command:
d ##class(SYS.Database).ReturnUnusedSpace("c:\intersystems\ensemble\mgr\habr\")
Our database occupies a lot less space now, and there is just 1 Mb of free space remaining in the database file. The possibility to defragment globals in a database and manage its free space by moving blocks and creating free ones has been introduced just recently. Before that, when you needed to defragment the database and reduce the size of the database file, you had to use the ^GBLOCKCOPY tool. It performed block-by-block copying from the source database to a newly created one and allowed the user to select specific globals to be carried over. The tool is still available.
Comments
And demo server still available here, just switch to map, at the toolbar close to combobox with a list of databases.
Question to the author and anyone else who might know, because this article got me thinking: When is it appropriate to defragment a CACHE.DAT sitting on an SSD?
The lifetime of an SSD diminishes with each write, and unlike conventional disks where one has to worry about head movement, defragging doesn't come with the same bang for the buck that it does with conventional disks. I'd imagine that there are still benefits (for example, you might have cached in memory the block you just read off the SSD, and it happens to contain the next value you need from that global, which means you can just grab it from the cache rather than going across the I/O interface), but don't know how the wins from that balance out with the number of writes by which one is shortening the life of the SSD in order to achieve those wins. Thoughts?
I haven't used SSD in production yet. I'm sure there lots of people who can say more about it. But anyway as I know, all modern SSD, and even which is special for servers, now has a very big count of rewrites. So, it means, that in most cases now you should care about it at all. And fragmentation could be a problem only when you have so many empty blocks, which should be cached, but you don't have some many RAM for it.
You have a view command in Blocks.WebSocket.ReadBlocks that looks like this:
View aBlockId
It's a good practice to always put a sanity check around view commands, something like:
if ((aBlockId>0)&&(aBlockId\1=aBlockId))
{ view aBlockId }
else
{ <error handling> }That check makes sure it's a whole number, and a positive number. If you try to pass something to VIEW that's not a whole number, you'll get an error. More problematically, if you pass a whole negative number to it you'll be writing to the database instead of reading from it. Doing that when you meant to read can cause database corruption and other integrity issues.
In this case, aBlockId is passed into the function, so all that has to happen is the caller passes in a bad value that isn't 0. You could expand the quit:aBlockId=0 0 check you have earlier in the function to achieve the same thing, but I think it's better to make a habit of always wrapping the VIEW command in this kind of check, or always using a macro that does the check - it makes it easier to review the code and make sure there's no possibility of it doing something harmful.
Thanks a lot Peter, it's a good point, I'll add this check.
Hi Dmitry,
Recommending your very cool and useful utility to someone I realized I did not find installation instructions, not here in this article, nor in the GitHub readme.
Could you please point me to them, or in case they indeed do not exist currently can you please provide them, for the benefit not only of the person I'm sharing this with, but with other Community members who will want to use this in the future.
Tx!
I wanted to finish stable release, with support for new versions Caché and IRIS, and also release docker image to use it very easy. But unfortunately, I have not found time for it, yet.
Hi Dmitry,
cool stuff indeed! (much cooler than one I made back in 2007 with plain CSP).
Quick question: would it display contents of large databases (hundreds of GBs) in a readable way too?
Dan
Large databases should not be a big issue. Should work, it will show data asynchronously, so, how depends how fast disc it should show data anyway. And it should work as fast as the Integrity, or so.
Can we leverage this application to show globals currently in Global Buffer?
Interesting task, and actually it is possible to implement.