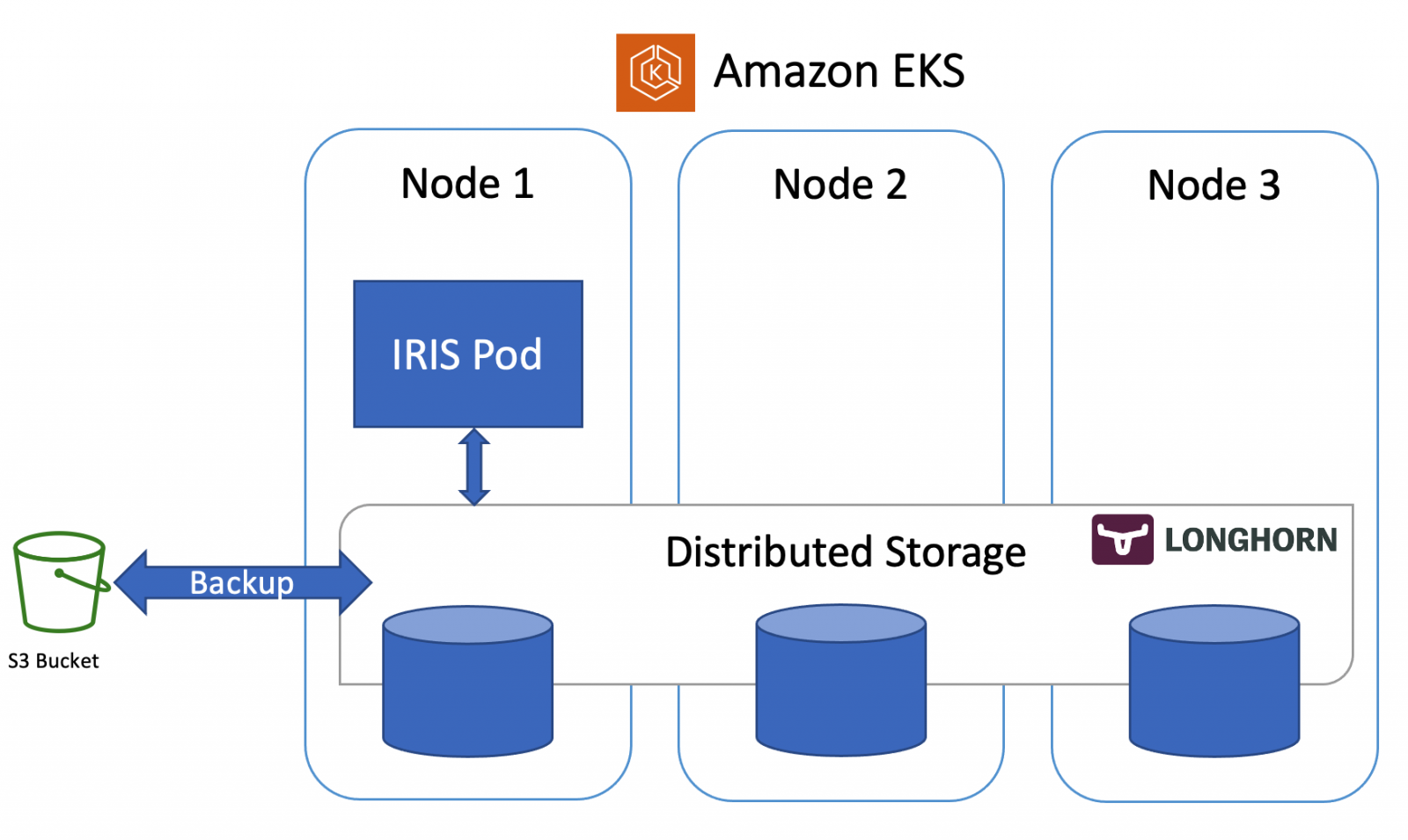
I have a client who' recently acquired a business that was running software that uses InterSystems IRIS as the database back end. In the process of preparing to have my company's software installed the client formatted the hard drive of his server, wiping out his data. I can't convert the data to MS SQL without a functioning database. He had a backup on an external drive, which I have copied down to my local machine. I loaded up a virtual machine with Windows 10 Pro, I installed Docker and IRIS. I started searching for explicit instructions for restoring the .
In information technology, a backup, or the process of backing up, refers to the copying and archiving of computer data so it may be used to restore the original after a data loss event.
In InterSystems Data Platform backup means procedures for backing up data in database files and all the related procedures which assure that no any application data is being lost during backup and recovery.

.png)