I (really) spent hours on finding the maximum size a Global is allowed to be (for Windows, if that matters). All I seem to run into are database sizes (derived from a max number of blocks and block size), but I refuse to believe that is correct because too small to be realistic.
If I add the same patient data with a different unique ID then it inserts as new data using a POST request. So, In the FHIR server How can I prevent this kind of thing by using POST requests? Note:- I don't want to use a PUT request for the same. The main thing is I want to get a unique patient record. Que:- Is there any way to check data duplication on each FHIR resource?
Use case: small in-house hospital systems that query patient demographics via SQL. The new PAS being implemented in the near future will only support query/response via HL7. SQL access is available but intended for reporting so up to 24 hours behind.
Probably the easiest option is to set up a database in Ensemble and keep it up to date via standard ADT feed. This is going to have quite a large footprint and has a risk of getting out of sync.
With the latest improvements in support for Python in IRIS, and continued work on Python DB-API support by InterSystems. I've implemented IRIS support to the Django project where is Python DB-API is used to work with some other databases.
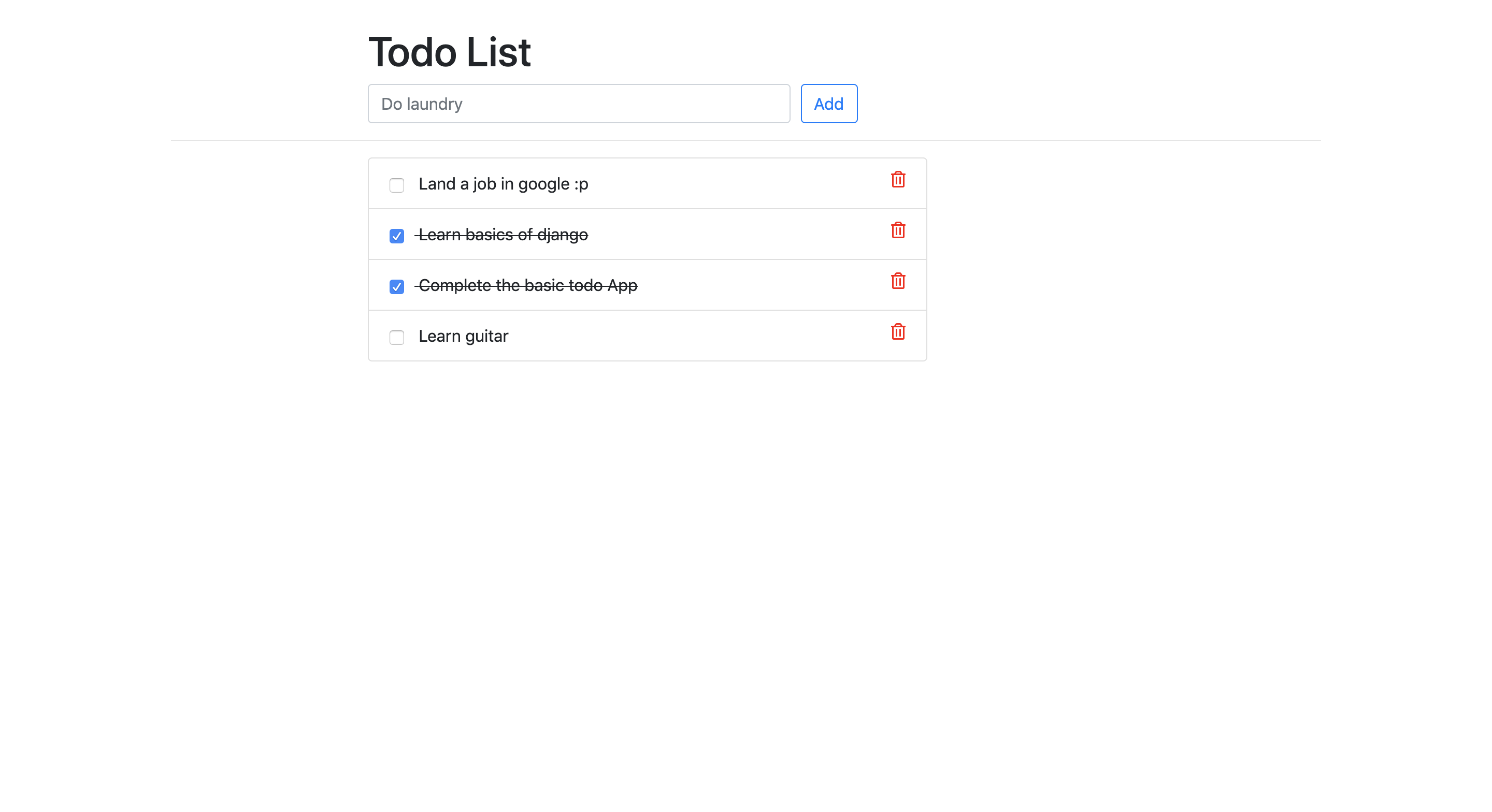
Let's try a simple application on Django, which stores its data in IRIS.
We are happy to share interesting information with you, as well as tell you why Python is good, where it is used.
Among the most used libraries are NumPy and Pandas. NumPy (Numerical Python) is used to sort large datasets. It simplifies mathematical operations and their vectorization on arrays. Pandas offers two data structures: Series (a list of elements) and Data Frames (a table with multiple columns). This library converts data into a Data Frame, allowing you to remove and add new columns, as well as perform various operations.
Coming up on Thursday March 3rd, VS Code Day 2022, the second official Visual Studio Code event from Microsoft.
Join the Visual Studio Code team and community at a live event just for VS Code users. Get a glimpse of things to come and meet the team who works on VS Code every day.
The title says it all. I’m building an IRIS image with docker-compose using a separate Dockerfile. Pretty straightforward procedure: I import a Installer script inside the container containing a Installer Manifest I defined. Within the manifest, I create a namespace with code and data databases in separate locations. My intention is to keep the code database inside the container, so whenever I build the container, the imported code is replaced. The data, however, should be persistent.
We invite you to share your feedback about our gamification program for developers - Global Masters. How did we do in 2021? What do you like about it? What you'd like to change?
In my article I described the work using iris.gref . As the official documetation is rather slim on the subject it was necessary to dig into it. Using the power of Python I was able to detect what I needed but was hidden. I decided to share this with you. pydoc did the magic.
I have performed the suggested steps given in the below link for IAM installation but got an error "docker. errors.NullResource: Resource ID was not provided [21528] Failed to execute script docker-compose"
When designing a hierarchy in DeepSee, a child member must have only one parent member. In the case where a child corresponds to two parents, the results can become unreliable. In the case where two similar members exist, their keys must be changed so that they are unique. We will take a look at two examples to see when this happens and how to prevent it.
I am looking for some ideas from people who have automated alerting in place for their Ensemble or IRIS productions.
I want to start with basic things like, simply checking if a Production is up and running. Once this has been achived, I am looking to go deeper and implement monitoring on each interface level for things like, Queue Size, Errors and Inactivity.
Found one interesting behaviour in one system with Ensemble. Some Request class has a property with type %XML.CharacterStream by design, this class is the heaviest request in the system, and with profiling journal files, it got about 40% of the file. When I counted all the sizes of such streams per one day and found that the real stored data is three times less.
 By update
By update

 Open Exchange app
Open Exchange app


.png)
.png)