By update
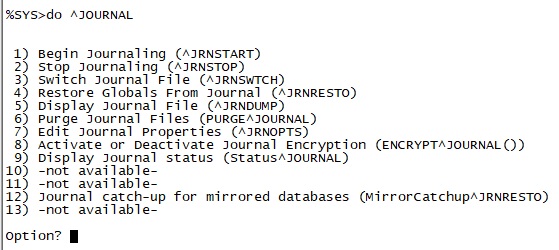
By updateI'm working for an organisation that is running a very old version of InterSystems Cache (5.016) which runs on AIX . The last two times we have re-booted Cache, we have encountered rollbacks. I've been asked two questions. During the rollback it was "How long is it going to take?" and after the system returned, it was "So what caused it?". My answer to both was "I don't know".