Hi Guys,
I get a Quit argument not allowed error in an if block how can I fix this?
.png)
InterSystems IRIS for Health™ is the world’s first and only data platform engineered specifically for the rapid development of healthcare applications to manage the world’s most critical data. It includes powerful out-of-the-box features: transaction processing and analytics, an extensible healthcare data model, FHIR-based solution development, support for healthcare interoperability standards, and more. All enabling developers to realize value and build breakthrough applications, fast. Learn more.
Hi Guys,
I get a Quit argument not allowed error in an if block how can I fix this?
I thought I knew how to return a Response from a Business Process back to the Source Config Name, but I guess not.
I am working on a Proof of Concept, that the Request Message Class would determine a "Route" within a Business Process to make a FHIR call (search, read) to our External FHIR repository, and return back the HS.FHIR.DTL.vR4.Model.Resource.xxxxxxx as a Response to the Source Config Name.
I have the FHIR part working, however now that I have the data in the form of HS.FHIR.DTL.vR4.Model.Resource.
So I would like to start a production with a service that has an SQL trigger for after and INSERT. Then I would like it to start a process. Could someone help me in the direction of a solution, please and thanks.
I have created the following Task to kick off a Ens.BusinessService to execute a SQL query and process the results
Class OSU.Workday.TerminationsTask Extends %SYS.Task.Definition
{
Parameter TaskName As STRING = "OSU - Workday Termination Update";
Method OnTask() As %Status
{
#Dim sc as %Status
#Dim ex as %Exception.AbstractException
set sc = $$$OK
try{
// create the service
#Dim tService As OSU.DataSource.Workday.TermService
Set tServiceConfigName = "OSU.DataSource.Workday.TermService"
// Call BusinessService
$$$ThrowOnError(##class(Ens.Director).CreateBusinessService(tServiceConfigName,.tService))
$$$ThrowOnError(tService.Adapter.OnTask())
set (tHint) = ""
}catch ex{
set tSC = ex.AsStatus()
}
quit tSC
}
ClassMethod TestTask()
{
set tTask = ##class(OSU.Workday.TerminationsTask).%New()
$$$ThrowOnError(tTask.OnTask())
}
/// Location and Revision of this file in Perforce (Auto-updating)
Parameter SrcVer = "$Id$";
}
Hello, I am working with @Alberto Fuentes https://openexchange.intersystems.com/package/workshop-iris-oauth2.
I wonder how do I get a token to send to the resserver?
I tried calling "token_endpoint" : "https://webserver/authserver/oauth2/token"
The response was "error":"invalid_request","error_description":"Unknown grant_type"
I wonder what needs to be in the request body? Is it a GET or POST?
As you all probably know, Health Connect / IRIS for Health natively supports DICOM messaging, and many of you will have used it daily. Well, I recently discovered a rather insidious little issue that our beloved @Alberto Fuentes gave me the solution.
We (I) will call this phenomenon the Creosote effect (those of you who know Monty Python will understand the reference, for the rest you can see the sketch here )
Mr.
How many times have we migrated an IRIS Instance to another machine, maybe even another version, and after a few days realized we forgot that one SSL Configuration critical for a Business Operations to work? Or maybe a credential, or a lonely class in a package by itself?
The simple solution is to make a checklist¹. A checklist of the entities we have to move. But simple checklists on Word documents are often forgotten, or just ignored.
I have a json object coming in on a service with a field that has "NaN" as its value.
"ReferralInOutOfNetworkCd": "NaN",
In my DTL, I do a straight copy. yet what goes outbound is NaN, without being wrapped in double quotes
"consulting_provider_network_ordering_rd":NaN,
Has anyone experience this? If so, did you find a way to fix or work around it?
Introduction
The recent addition of FIFO groups allows First-In, First-Out (FIFO) message processing to be maintained in an interoperability production even when a Pool Size is greater than 1, enabling higher performance without sacrificing correctness. This feature first appears in InterSystems IRIS® data platform, InterSystems IRIS® for Health, and InterSystems Health Connect™ in version 2025.3.
First-In, First-Out message processing is critical in many integration scenarios, especially in healthcare. Traditionally, FIFO ordering is enforced by configuring each business host to process only one message at a time (Pool Size = 1). While effective, this approach can limit throughput and underutilize system resources. FIFO groups preserve FIFO ordering where needed without requiring a Pool Size of 1.
| Alert Id | Product & Versions Affected | Risk Category & Score | Explicit Requirements |
| DP-449126 | InterSystems IRIS® data platform InterSystems IRIS® for Health InterSystems Health Connect™ versions 2024.1.0 – 2024.1.5, 2024.2.0, 2024.3.0, 2025.1.0 – 2025.1.3, 2025.2.0, 2025.3.0 |
Data Integrity: Low Risk | Database updates executed as part of custom logic for CSP session events may not be journaled. |
Hello Community!
We're pleased to invite you to the upcoming webinar in Hebrew:
👉Getting Started with OAuth 2.0 on InterSystems👈
📅 Date & time: March 25th, 3:00 PM IDT
I created a new repo called ipm-module-budget from https://github.com/intersystems-community/intersystems-iris-dev-template template.
I cloned the repo to an EC2 instance in AWS. When I try to build image, I see this error:
#8 22.09 [IRISAPP|ipm-module-budget] Reload START (/home/irisowner/dev/)Segmentation fault (core dumped) #8 ERROR: process "/bin/sh -c pip3 install -r requirements.txt && iris start IRIS && \tiris session IRIS < iris.scri pt && iris stop IRIS quietly" did not complete successfully: exit code: 139
| Alert Id | Product & Versions Affected | Risk Category & Score | Explicit Requirements |
| DP-448888 |
Products: Versions: |
Operational: High Risk | ≥ 2 TB of database cache is used |
In the versions specified above, an instance may fail to start or may hang during operation if the database cache is greater than or equal to 2,097,152 MB (2 TB).
Hi Community,
We're super excited to share that we’ve just launched a new free, interactive tutorial designed especially for those who are new to InterSystems IRIS and looking for a clear, practical introduction to its core concepts.
🧑🏫 Data Models of InterSystems IRIS 🧑💻

Hi Community,
In this article, I will introduce my application iris-HL7v2Gen .
IRIS-HL7v2Gen is a CSP application that facilitates the dynamic generation of HL7 test messages. This process is essential for testing, debugging, and integrating healthcare data systems. The application allows users to generate a wide variety of HL7 message types, validate their structure against HL7 specifications, explore the message hierarchy, and transmit messages over TCP/IP to production systems. These features are particularly useful in settings where compliance with HL7 standards is mandatory for interoperability between different healthcare organizations or systems.
There are lessons we learned from developing and maintaining code for interoperability components within a healthcare institutional environment.
Be prepared to rebuild, improve, extend, and fix the plane mid-flight.
Maintenance windows for hospital systems are often very limited, with some required to be operational 24/7. While the critical health systems such as imaging modalities or registration kiosks — or at least their critical functions — must operate autonomously, efficiency and usability may be compromised when interoperability components malfunction.
Hi community,
I've been working on a side project that I'd love to get some eyes on: a ground-up rebuild of the classic IRIS Production Monitor using a modern web stack. The existing ZEN/CSP-based portal does the job, but I wanted to explore what a contemporary, real-time version of it could look like.
A standalone Angular web application that connects to any Interoperability-enabled IRIS namespace and gives you a live view of your production — services, processes, operations, queues, event log, and message traffic — all in one screen.
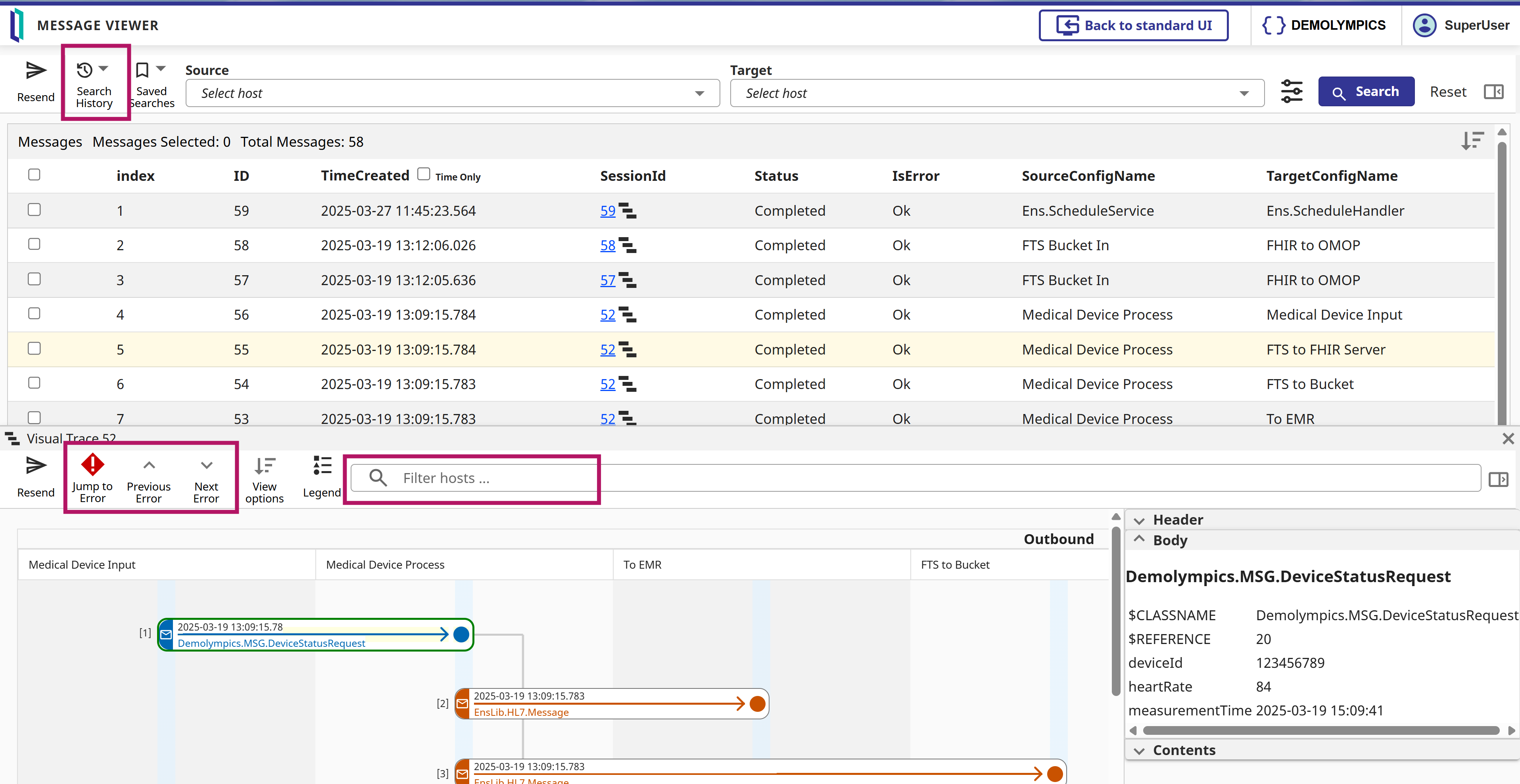
As part of the new Interoperability UI wave (see what was new in 2025.1, and 2025.3 by @Aya Heshmat), v2026.1 which is available already as a Developer Preview, and this could be a reason for you to give it a ride - will be shipping the new UI for the Message viewing and searching, including Visual Trace (and other UI goodies).
He's a quick teaser:
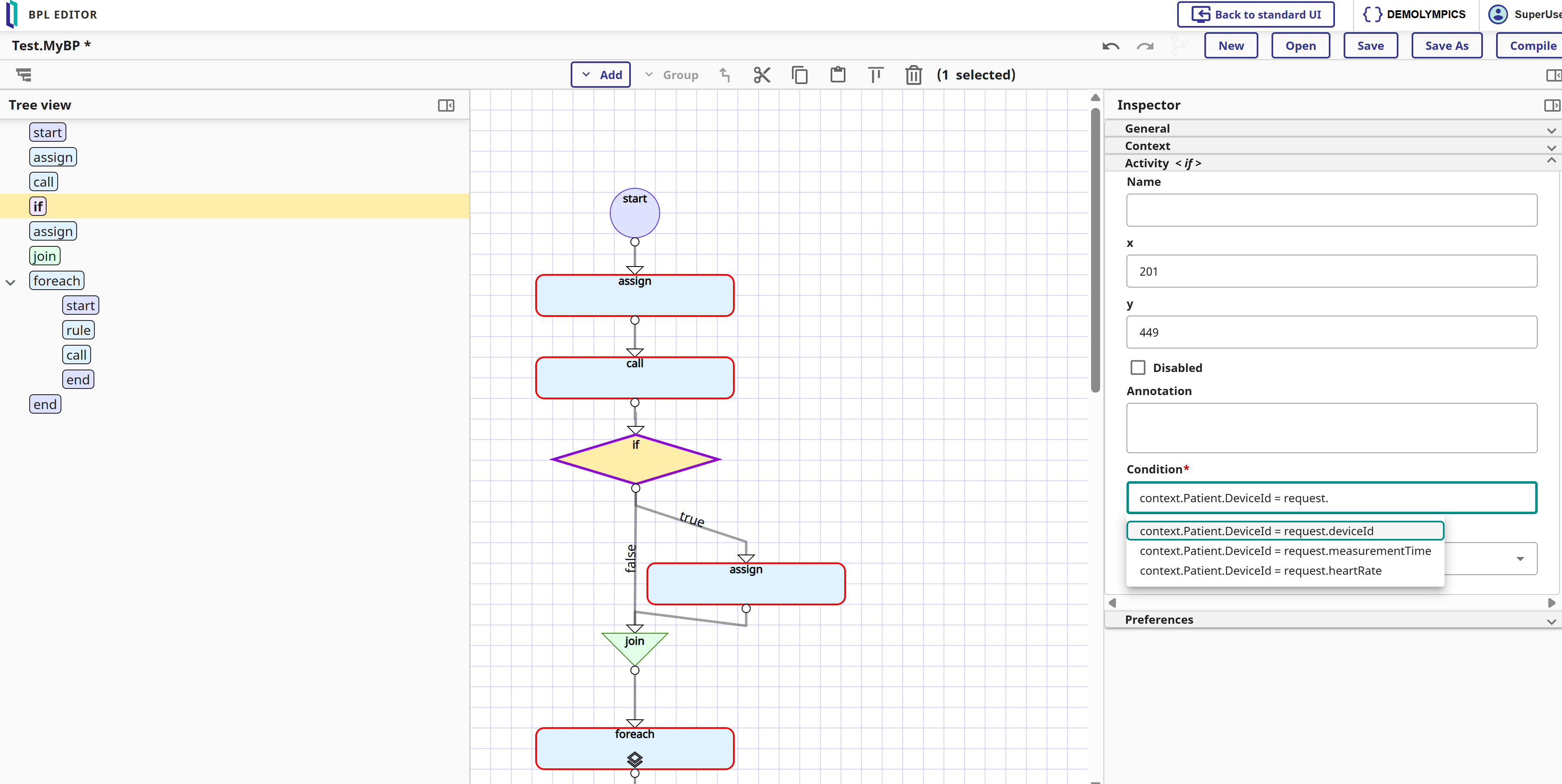
As part of the new Interoperability UI wave (see what was new in 2025.1, and 2025.3 by @Aya Heshmat), v2026.1 which is available already as a Developer Preview, and this could be a reason for you to give it a ride - will be shipping the new UI for the BPL editor (and other UI goodies).
He's a quick teaser:
I may have mentioned this before: I believe the Visual Traces, these sequence diagrams with full content of each step, are a fantastic feature of the IRIS Data platform! Detailed information about how the API works internally, as a visual trace, can be very useful for projects on the IRIS platform. Of course, this applies when we are not developing a high-load solution, in which case we simply don't have time for saving/reading messages. For all other cases, welcome to this tutorial!
Hey Community!
We're happy to share a new video from our InterSystems Developers YouTube:
We are trying to track down significant growth within our Namespaces, one big culprit is Ens.AppData (EnsLib.SQL.Snapshot).
Within many of our BPL's we use EnsLib.SQL.Snapshot to return Results from External SQL Stored Procedures or Query's. The same EnsLib.SQL.Snapshot context variable is used for many of these calls within a BPL.
Is there something we should be doing at the end of the BPL to ensure that EnsLib.SQL.Snapshot gets cleaned up and purged from Ens.AppData?
How can I create a Task that tells a Ens.BusinessService to execute its SQL query using the EnsLib.SQL.InboundAdapter?
So far I have come up with
Class OSU.Workday.TerminationsTask Extends %SYS.Task.Definition
{
Parameter TaskName As STRING = "OSU - Workday Termination Update";
Method OnTask() As %Status
{
try{
// Call BusinessService
set tSC = ##class(Ens.Director).CreateBusinessService("OSU.DataSource.Workday.TermService",.tService)
if $IsObject(tService){
set inputMessage = ##class(Ens.StringContainer).%New()
set inputMessage.StringValue = "1"
Set tSC = tService.ProcessInput(inputMessage,.output)
} Else {
Set tSC = $$$ERROR($System.Status.GetErrorCodes(tSC), "Failed to create Business Service")
}
}catch ex{
set tSC = ex.AsStatus()
}
quit tSC
}
/// Location and Revision of this file in Perforce (Auto-updating)
Parameter SrcVer = "$Id: //custom_ccrs/us/OSUM/OSUMHSCUSTOM/UAT/cls/OSU/Workday/TerminationsTask.xml#20 $";
}
Emergency Medical Services (EMS) teams often arrive at the emergency department with patients whose demographics are incomplete or unknown—no medical record number (MRN), no confirmed name, and sometimes no date of birth. Yet EMS transportation notes still need to land in the correct chart.
To support safe and reliable documentation, EMS agencies, third-party integration services, and hospital integration teams build secure interfaces that exchange identifiers and clinical messages.
Hello everyone,
I am André from MedVertical. We are exploring InterSystems-native ways to operationalize continuous FHIR conformance: repeatable regression runs, baseline/delta comparisons, and evidence-style reporting to detect drift after releases and IG changes.
In many FHIR implementations, validation is done “point-in-time” in pre-prod, but conformance degrades in production due to IG/profile updates, terminology changes, mapping evolution, upstream releases, and configuration drift.
IPM version 0.10.6 was released on February 24th, 2026. This version is mostly bug fixes, but does add the -export-python-deps flag to the package and publish commands to include Python dependencies with the IPM module itself. As usual, you can check it out on the GitHub page or through the Community Registry.
Here's the complete changelog:
Added
- #1024: Added flag -export-python-deps to publish command
Fixed
- #996: Ensure COS commands execute in exec under a dedicated, isolated context
- #1002: When listing configured repositories, only show the TokenAuthMethod when a token is defined.
Hi, Community!
Working with large volumes of data? See how streams can help:
This is more for my memory that anything else but I thought I'd share it because it often comes up in comments, but is not in the InterSystems documentation.
There is a wonderful utility called ^REDEBUG that increases the level of logging going into mgr\cconsole.log.
You activate it by
a) start terminal/login
b) zn "%SYS"
c) do ^REDEBUG
d) change logging level to FFFFFFFF
if you are on you production system (with lots of traffic) I suggest you quickly reproduce the error, rename the cconsole.log file, and repeat the steps above to set the logging level to FF.
JSON
JSON (JavaScript Object Notation) is a lightweight, text-based format designed for structured data interchange. It represents data objects consisting of key–value pairs and arrays, and it is entirely language-independent.
Configuration differences between environments are not always mistakes, but they should always be intentional and governed.
We're excited to announce that version 3.6 of JediSoft IRISsync® is now available, bringing enhancements designed to give teams more control and visibility when managing configuration settings across multiple IRIS instances.
What's new in IRISsync 3.6: