When calling out to web services there are several settings of the Business Operation that play together in controlling what will happen when a response is not returned in the desired time.
It is becoming more and more common to see beautiful badges in the README.MD file with useful information about the current project in the repositories of GitHub, GitLab and others.
For instance:
This article provides a reference architecture as a sample for providing robust performing and highly available applications based on InterSystems Technologies that are applicable to Caché, Ensemble, HealthShare, TrakCare, and associated embedded technologies such as DeepSee, iKnow, Zen and Zen Mojo.
Azure has two different deployment models for creating and working with resources: Azure Classic and Azure Resource Manager. The information detailed in this article is based on the Azure Resource Manager model (ARM).
As the health interoperability landscape expands to include data exchange across on-premise as well as hosted solutions, we are seeing an increased need to integrate with services such as cloud storage. One of the most prolifically used and well supported tools is the NoSQL database DynamoDB (Dynamo), provided by Amazon Web Services (AWS).
The %Net.SSH.Session class lets you connect to servers using SSH. It's most commonly used with SFTP, especially in the FTP inbound and outbound adaptors.
In this article, I'm going to give a quick example of how to connect to an SSH server using the class, describe your options for authenticating, and how to debug when things go wrong.
Visual Studio Code (VSCode) is the most popular code editor on the market. It was created by Microsoft and distributed as a free IDE. VSCode supports dozens of programming languages, including ObjectScript, Until 2018, Atelier (based on Eclipse). It was considered as one of the main options to develop InterSystems products.
This article will describe and include an example of how to embed an external PDF file into an HL7 segment, specifically ADT_A01:2.3.1 OBX(). This can be useful when attempting to insert pictures or other external data into an HL7 message. In this example, the name of the PDF file to be embedded is provided in the incoming HL7 message in OBX(1):ObservationValue field.
We all know that having a set of proper test data before deploying an application to production is crucial for ensuring its reliability and performance. It allows to simulate real-world scenarios and identify potential issues or bugs before they impact end-users. Moreover, testing with representative data sets allows to optimize performance, identify bottlenecks, and fine-tune algorithms or processes as needed. Ultimately, having a comprehensive set of test data helps to deliver a higher quality product, reducing the likelihood of post-production issues and enhancing the overall user experience.
In this article, let's look at how one can use generative AI, namely Gemini by Google, to generate (hopefully) meaningful data for the properties of multiple objects. To do this, I will use the RESTful service to generate data in a JSON format and then use the received data to create objects.
https://www.youtube.com/embed/3KClL5zT6MY [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
https://www.youtube.com/embed/cuMLSO9NQCM [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
Extracting and plotting pButtons data including timeframes and iostat.
As an IT and cloud team manager with 18 years of experience with InterSystems technologies, I recently led our team in the transformation of our traditional on-premises ERP system to a cloud-based solution. We embarked on deploying InterSystems IRIS within a Kubernetes environment on AWS EKS, aiming to achieve a scalable, performant, and secure system. Central to this endeavor was the utilization of the AWS Application Load Balancer (ALB) as our ingress controller.
To connect to AtScale, we will use the SQL Server Analysis Services database. Let's open it in the Power Query editor. To do that, select Transform Data on the Home. In the window that appears, go to the Home, expand New Source and select Analysis Services.
This post will guide you through the process of sizing shared memory requirements for database applications running on InterSystems data platforms. It will cover key aspects such as global and routine buffers, gmheap, and locksize, providing you with a comprehensive understanding. Additionally, it will offer performance tips for configuring servers and virtualizing IRIS applications. Please note that when I refer to IRIS, I include all the data platforms (Ensemble, HealthShare, iKnow, Caché, and IRIS).
Suppose you have a persistent class with data and you want to have a simple Angular UI for it to view the data and make CRUD operations.
Recently @Alberto Fuentesdescribed how to build Angular UI for your InterSystems IRIS application using RESTForms2.
In this article, I want to tell you how you can get a simple Angular UI to CRUD and view your InterSystems IRIS class data automatically in less than 5 minutes.
Some time ago GitHub, has announced the new feature, GitHub Codespaces. It gives an ability to run VSCode in the browser, with almost the same power as it would run locally on your machine, but also with a power of clouds, so, you are able to choose the machine type with up to 32 CPU cores and 64 GB of RAM.
Looks impressive, is not it? But how it could help us, to work with projects driven by InterSystems IRIS? Let's have a look, how to configure it for us.
Let’s imagine that you are a Python developer or have a well-trained team specialized in Python, but the deadline you got to analyze some data in IRIS is tight. Of course, InterSystems offers many tools for all kinds of analyses and treatments. However, in the given scenario, it is better to get the job done using the good old Pandas and leave the IRIS for another time.
Suppose you have an application that allows users to write posts and comment on them. (Wait... that sounds familiar...)
For a given user, you want to be able to list all of the published posts with which that user has interacted - that is, either authored or commented on. How do you make this as fast as possible?
Here's what our %Persistent class definitions might look like as a starting point (storage definitions are important, but omitted for brevity):
NB. Please be advised that PKI is not intended to produce certificates for secure production systems. You should make alternate arrangements to create certificates for your productions. NB. PKI is deprecated as of IRIS 2024.1: documentation and announcement.
In this post, I am going to detail how to set up a mirror using SSL, including generating the certificates and keys via the Public Key Infrastructure built in to InterSystems IRIS Data Platform. I did a similar post in the past for Caché, so feel free to check that out here if you are not running InterSystems IRIS. Much like the original, the goal of this is to take you from new installations to a working mirror with SSL, including a primary, backup, and DR async member, along with a mirrored database. I will not go into security recommendations or restricting access to the files. This is meant to just simply get a mirror up and running. Example screenshots are taken on a 2018.1.1 version of IRIS, so yours may look slightly different.
The Amazon Web Services (AWS) Cloud provides a broad set of infrastructure services, such as compute resources, storage options, and networking that are delivered as a utility: on-demand, available in seconds, with pay-as-you-go pricing. New services can be provisioned quickly, without upfront capital expense. This allows enterprises, start-ups, small and medium-sized businesses, and customers in the public sector to access the building blocks they need to respond quickly to changing business requirements.
How to include IRIS Data into your Google Big Query Data Warehouse and in your Data Studio data explorations. In this article we will be using Google Cloud Dataflow to connect to our InterSystems Cloud SQL Service and build a job to persist the results of an IRIS query in Big Query on an interval.
We started to use Azure Service Bus (ASB) as an enterprise messaging solution 3 years ago. It is being used to publish and consume data between many applications in the organization. Since the data flow is complex, and one application’s data is usually needed in multi applications the “publisher” ---> ”multiple subscribers” model was a great fit. The ASB usage in the organization is dozens of millions of messages per day, while IRIS platform is having around 2-3 million messages/day.
Surely you have all heard about FHIR as the panacea and solution to all interoperability and compatibility problems between systems. Right here we can see one of his classic defenders holding a FHIR resource in his hand and enjoying it immensely:
But for the rest of us mortals we are going to make a small introduction.
Python has become the most used programming language in the world (source: https://www.tiobe.com/tiobe-index/) and SQL continues to lead the way as a database language. Wouldn't it be great for Python and SQL to work together to deliver new functionality that SQL alone cannot? After all, Python has more than 380,000 published libraries (source: https://pypi.org/) with very interesting capabilities to extend your SQL queries within Python.
Journaling is a critical IRIS feature and a part of what makes IRIS a reliable database. While journaling is fundamental to IRIS, there are nuances, so I wrote this article to summarize (more briefly than our documentation which has all the details) what you need to know. I realize the irony of saying the 27 minute read is brief.
In this article, we will run an InterSystems IRIS cluster using docker and Merge CPF files - a new feature allowing you to configure servers with ease.
On UNIX® and Linux, you can modify the default iris.cpf using a declarative CPF merge file. A merge file is a partial CPF that sets the desired values for any number of parameters upon instance startup. The CPF merge operation works only once for each instance.
Our cluster architecture is very simple, it would consist of one Node1 (master node) and two Data Nodes (check all available roles). Unfortunately, docker-compose cannot deploy to several servers (although it can deploy to remote hosts), so this is useful for local development of sharding-aware data models, tests, and such. For a productive InterSystems IRIS Cluster deployment, you should use either ICM or IKO.
We resume our series of articles on the FHIR Adapter tool available to HealthShare HealthConnect and InterSystems IRIS users.
In the previous articles we have presented the small application on which we set up our workshop and showed the architecture deployed in our IRIS instance after installing the FHIR Adapter. In today's article we will see an example of how we can perform one of the most common CRUD (Create - Read - Update - Delete) operations, the reading operation, and we will do it by recovering a Resource.
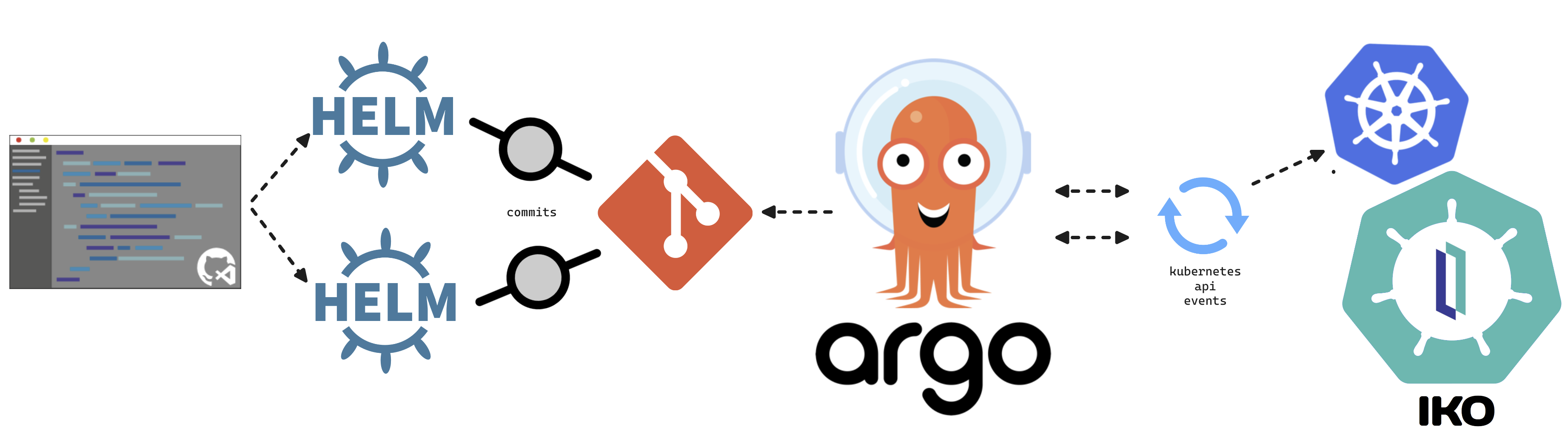
This article will cover turning over control of provisioning the InterSystems Kubernetes Operator, and starting your journey managing your own "Cloud" of InterSystems Solutions through Git Ops practices. This deployment pattern is also the fulfillment path for the PID^TOO||| FHIR Breathing Identity Resolution Engine.
 By replies
By replies
 Open Exchange app
Open Exchange app

.png)

.png)