You need to install the application first. If not installed, please refer to the previous article
Application demonstration
After successfully running the iris image vector search application, some data needs to be stored to support image retrieval as it is not initialized in the library.
We recently changed the 'UserID" property in a "User" class from type of %String to be %Library.Username. This is for better consistency across our codebase regarding MAXLEN limit.
%Library.Username is a system wrapper datatype which extends %String and has a MAXLEN of 160. This change should have minimal/no impact on code behavior. However, we found that some SQL query cannot return expected rows after the change. Query will return empty values even if the entry is in the table.
What is Unstructured Data? Unstructured data refers to information lacking a predefined data model or organization. In contrast to structured data found in databases with clear structures (e.g., tables and fields), unstructured data lacks a fixed schema. This type of data includes text, images, videos, audio files, social media posts, emails, and more.
In the world of APIs, REST is very extended. But what happens when you need more flexibility in your data-fetching strategies? For instance letting the client to choose what fields is going to receive. Enter GraphQL, a query language for your APIs that provides a flexible alternative to REST.
In this post, we will:
Compare REST and GraphQL.
Dive into the basics of GraphQL: Queries, Mutations, and HTTP.
Build a simple GraphQL server implementation using Graphene, SQLAlchemy, and Flask over data in InterSystems IRIS.
Explore how to deploy your GraphQL server as a WSGI application in IRIS.
In some of the last few articles I've talked about types between IRIS and Python, and it is clear that it's not that easy to access objects from one side at another.
Fortunately, work has already been done to create SQLAlchemy-iris (follow the link to see it on Open Exchange), which makes everything much easier for Python to access IRIS' objects, and I'm going to show the starters for that.
If you want to import data from a mySQL export file (exported with mysqldump), you will find here a little script that could help.
Only the INSERT commands in the sql file are executed into Caché. Indices are not computed for better performance. %NOINDEX, %NOCHECK and %NOLOCK are generated on each INSERT line.
Currently, the file can not contain a "),(" pattern inside the values part of the INSERT command. If this is the case, the line is skipped. This feature may be implemented in the extractValuesList method.
There is a Link Procedure Wizard option within the Management Portal (System > SQL >Wizards > Link Procedure) which I had reliability issues with so I decided to use this solution instead.
As we all know, Caché is a great database that accomplishes lots of tasks within itself. However, what do you do when you need to access an external database? One way is to use the Caché SQL Gateway via JDBC. In this article, my goal is to answer the following questions to help you familiarize yourself with the technology and debug some common problems.
The ID of the last updated record can be obtained using the SQL function LAST_IDENTITY(). * This function can be used with embedded SQL or ODBC but not with Dynamic SQL, SQL Shell, or the Management Portal's SQL interface.
Here's an example of usage with simple Embedded SQL:
What I find really useful about IRIS when teaching my subject of Postrelational databases is the fact that it is a multi model database. Which means that I can actually go into architecture and structure and all that only once but then show the usage of different models (like object, document, hierarchy) using the same language and approach. And it is not a huge leap to go from an object oriented programming language (like C#, Java etc) to an object oriented database.
However, along with advantages (which are many) come some drawbacks when we switch from object oriented model to relational. When I say that you can get access to the same data using different models I need to also explain how it is possible to work with lists and arrays from object model in relational table. With arrays it is very simple - by default they are represented as separate tables and that's the end of it. With lists - it's harder because by default it's a string. But one still wants to do something about it without damaging the structure and making this list unreadable in the object model.
So in this article I will showcase a couple of predicates and a function that are useful when working with lists, and not just as fields.
I was struggling with a procedure that was meant to receive a string and use it as a filter, I've found that since I want the procedure to do some data transformation and return a dataset, I needed to use objectScript language.
I've created the procedure using the SQL GUI in the portal, and everything works fine when calling the procedure from the SQL GUI but not through a JDBC connection here is the call "call spPatientOS('2024-04-07T12:35:32Z')"
I just wrote up a quick sample to help a colleague load data into IRIS from R using RJDBC, and figured it's worth sharing here for future reference.
Ultimately it was pretty simple, aside from IRIS not liking "." in column names; the workaround is to just rename the columns. Someone better at R than me could probably provide some generic approach.
FOREIGN TABLES is a rather fresh feature in IRIS (2023.?) So I was motivated to try something new by own hands. Documentation of Foreign Table from File is a good starting point. Also the related promotional video is fine to start with.
What do you do if you want to have the ID field have a meaningful name for your application?
Sometimes it comes to pass that when you're making a new table that you want to have the unique row identifier (a.k.a. IDKEY) to be a field that has a name that is meaningful for your data. Moreover, sometimes you want to set this value directly. Caché fully supports this functionality and it works Suppose you have a class Test.Kyle. The data will be stored like so:
I'm participating in the Developing with InterSystems Objects and SQL with Joel Solon. The course is very nice and I will share with you some tips I got during the training. Tips presented in the day 3:
As you may well remember from Global Summit 2022 or the 2022.2 launch webinar, we're releasing an exciting new capability for including in your analytics solutions on InterSystems IRIS. Columnar Storage introduces an alternative way of storing your SQL table data that offers an order-of-magnitude speedup for analytical queries. First released as an experimental feature in 2022.2, the latest 2022.3 Developer Preview includes a bunch of updates we thought were worth a quick post here.
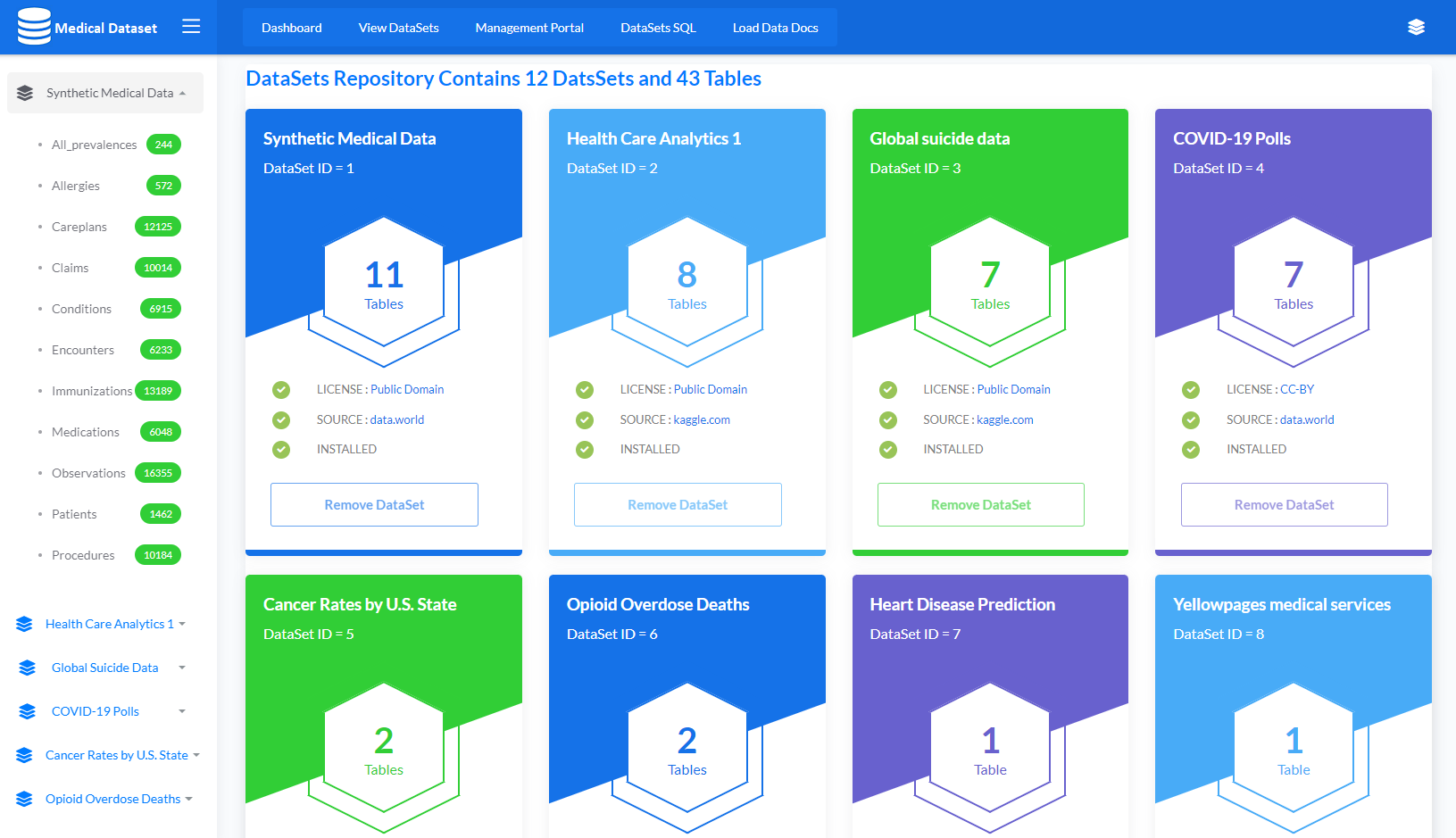
Application to import 12 Datasets along with 43 tables dynamically by using LOAD DATA command which loads data from a source into an IRIS SQL table. List of Datasets
If you are looking to breathe new life into an old MUMPS application follow these steps to map your globals to classes and expose all that beautiful data to Objects and SQL.
This example is going to cram in 4 or 5 different things beyond what was covered in Part 1
Let's say we have two serial classes, one as a property of another:
Class test.Serial Extends %SerialObject
{
Property Serial2 As test.Serial2;
}
Class test.Serial2 Extends %SerialObject
{
Property Property As %String;
}
And a persistent class, that has a property of test.Serial type:
Class test.Persistent Extends %Persistent
{
Property Datatype As %String;
Property Serial As test.Serial;
}
So it's a serial, inside a serial, inside a persistent object.
This is a translation of the following article. Thanks [@Evgeny Shvarov] for the help in translation.
Someone posted a question on DC asking whether it was possible to determine access rights for a particular table row always at runtime, and if it was, how could one do that? Answer: it is possible and it’s not hard at all.
With InterSystems IRIS 2022.2, we introduced Columnar Storage as a new option for persisting your IRIS SQL tables that can boost your analytical queries by an order of magnitude. The capability is marked as experimental in 2022.2 and 2022.3, but will "graduate" to a fully supported production capability in the upcoming 2023.1 release.
The product documentation and this introductory video, already describe the differences between row storage, still the default on IRIS and used throughout our customer base, and columnar table storage and provide high-level guidance on choosing the appropriate storage layout for your use case. In this article, we'll elaborate on this subject and share some recommendations based on industry-practice modelling principles, internal testing, and feedback from Early Access Program participants.
Presenter: Anton Umnikov Task: Identify your slowest SQL queries and tune them for better performance Approach: Use InterSystems’ query profiling and analysis tools. Discuss how system configuration can affect performance
This session will show you how you identify the weakest link in your application SQL and introduce you to the fine art of tuning those queries. To do this we will take a look at InterSystems query profiling and analysis tools, as well as how system configuration can impact SQL performance.
Problem: Obscurity on how our SQL engine works
Content related to this session, including slides, video and additional learning content can be found here.
The FHIR standard establishes a powerful but flexible data model that can smoothly adapt to the complexities of operational healthcare data management. This flexibility comes at the cost of a data model with many tables and relationships, even for simple data such as the patient's record of telephone numbers, addresses, and emails. It would easily require querying 4 different tables. However, FHIR SQL Builder eliminates this problem, allowing you to create visual projections (mappings) in web wizards.
 By replies
By replies Open Exchange app
Open Exchange app