 By update
By updateHello,
I would like to implement the Activity Monitor in a Sharepoint page.
How is it possible to integrate only the Zen element?
Is it necessary to develop a CSP application in which this element exists?
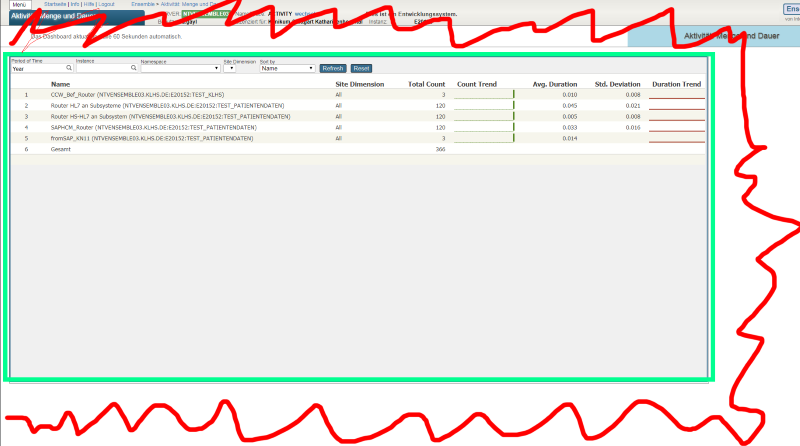
Has anyone done this before and can I get a tip?
With kind regards
Armin
