New
Hi Community,
Stay ahead with content relevant to your role and goals with the InterSystems Learning Services newsletter!
See how to customize your journey! 👇


InterSystems IRIS is a Complete Data Platform
InterSystems IRIS gives you everything you need to capture, share, understand, and act upon your organization’s most valuable asset – your data.
As a complete platform, InterSystems IRIS eliminates the need to integrate multiple development technologies. Applications require less code, fewer system resources, and less maintenance.
Hi Community,
Stay ahead with content relevant to your role and goals with the InterSystems Learning Services newsletter!
See how to customize your journey! 👇
What's the most straight-forward way to install this on an offline server? I'm trying to set this up on an Azure DevOps server to support our CI/CD pipelines. I've tried using zpm installing the tgz from the local filesystem. I note zpm seems to need a repo configured to install but I can't work out how to setup a bare-bones Filesystem repo (please point me to some documentation on this). I have no idea what I'm doing...
Common Table Expressions (CTEs) provide a structured framework for defining reusable intermediate result sets within SQL statements. InterSystems IRIS implements CTEs via the WITH clause, enabling clearer query composition and modular analytical processing while remaining fully integrated with the IRIS cost-based optimizer.
This article explores the semantics of CTEs in InterSystems IRIS, explains their interaction with query optimization, discusses appropriate deployment scenarios, and presents executable examples illustrating practical patterns for production environments.
When building a Production, should I create separate message classes for each integration flow, or is it acceptable to reuse generic request/response classes across different Business Operations? I'm trying to understand how to keep things organized as the number of integrations grows.
What is the recommended way to handle errors inside a Business Process in IRIS? Should I use Try/Catch within the BPL, return error responses to the caller, or rely on the built-in retry mechanism of the Production? Looking for guidance on what's considered good practice.
What is the recommended approach for handling upgrades in an InterSystems IRIS Kubernetes environment?
For example, if we deploy version 1.0.0 of our product and subsequently need to upgrade to 1.0.1, and this upgrade requires changes to SQL tables containing customer data.
The quickest solution that comes to mind is creating an 'upgrade method' that runs on startup to check if any data migration actions are required. However, I'm wondering if there are better solutions or established best practices for this.
Thanks in advance!
Hello Community,
What is the most efficient, memory-safe way to get the names of the corrupted indexes on very large tables for a rebuild. However, if an index has millions of corrupted rows, the .errors array in %ValidateIndices grows too large and throws a errorerror.
I recently started using Cursor/VSCode with an IRIS container for development rather than Studio/Terminal.
I've noticed that whenever I use %G (so basically all the time), when I exit %G, the terminal window simply closes, rather than returning me to my usual namespace prompt.
%G also does not retain the command stack like it does in old school terminal, so I'm forced to constantly retype every global reference.
Anyone figured out a solution to this? It's a relatively minor problem in the grand scheme of things, but a time consuming and irritating one.

When developing Python applications with InterSystems IRIS, you can quickly end up with several execution contexts:
python3 process that loads the Embedded Python libraries from a local IRIS installation;These three cases are useful, but they do not behave exactly the same way for imports, system configuration, object APIs, and SQL access.
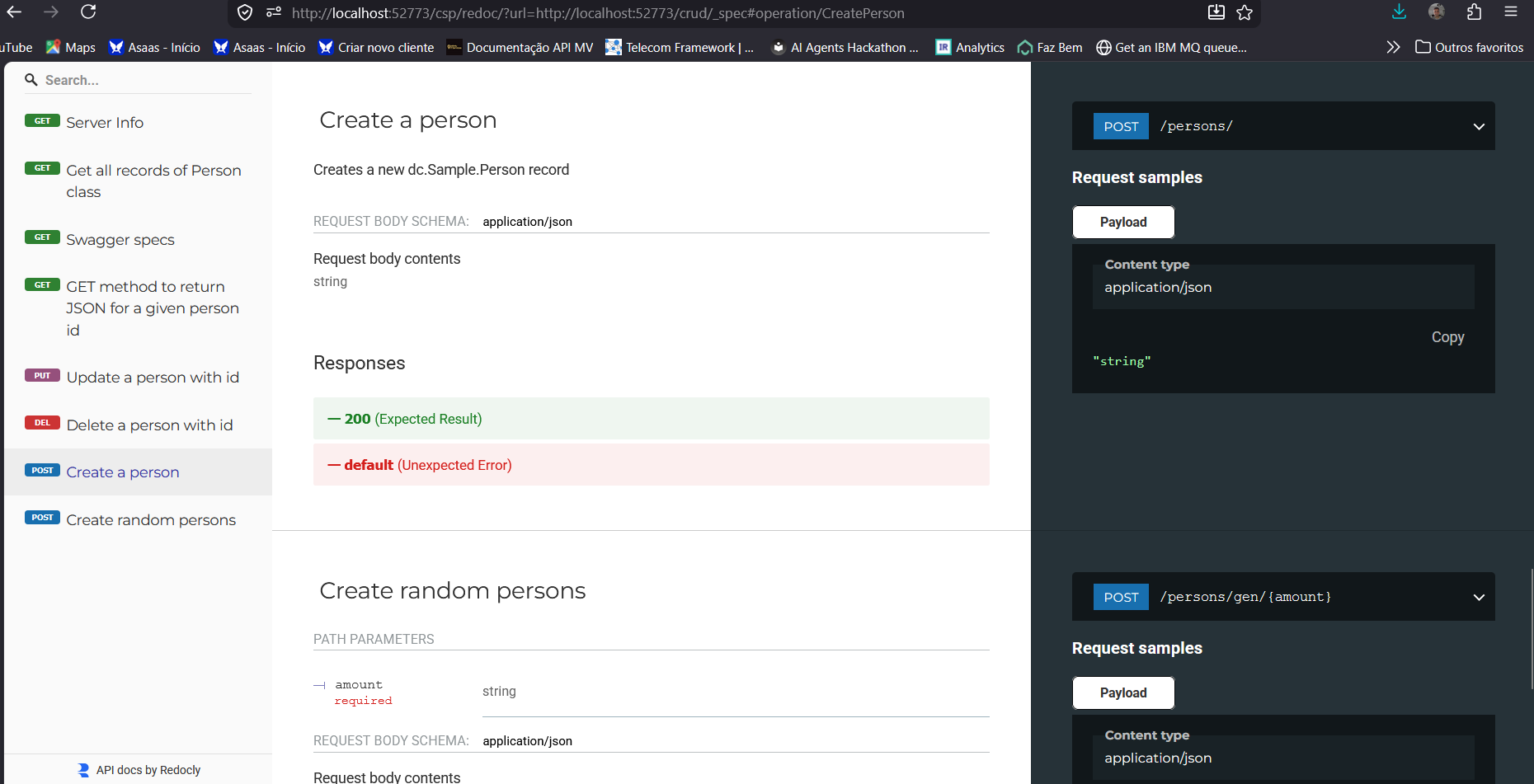
Redoc is an Open Source solution capable of rendering API specifications in OpenAPI 2.0 or 3.0+ as very beautiful and functional web portals. Currently, to have something similar, we need the ZPM SwaggerUI extension or we need to install IAM - InterSystems API Manager and then configure the IAM Developer Portal. Well, now the community has one more option, iris-redoc. This solution installs a web application on your IRIS instance that uses Redoc to present a beautiful web portal for your REST APIs:
For those who learned Caché ObjectScript from scratch: what kind of personal or practice projects did you build to get comfortable with the language? I come from a C# background and I'm looking for project ideas that are small enough to be feasible but meaningful enough to actually teach the core COS concepts.
Hello Community!
We’re excited to invite you to our upcoming Hebrew webinar, presented by @Keren Skubach, an InterSystems Senior Sales Engineer:
👉A Practical Guide to Leveraging AWS Adapters and APIs 👈
📅 Date & time: June 2nd, 3:00 PM IDT
Discover how to accelerate cloud-based integration with InterSystems' native AWS adapters for S3, SQS, SNS, and CloudWatch.
This session provides a practical look at building modern interoperability workflows — from secure file ingestion and asynchronous messaging to automated notifications and centralized monitoring.
Recently, a question on the Community was asked by @Vermon Ferre about storing data from inherited classes in different globals. So, I decided to simulate the following behavior: I created a superclass called Article.MainClass and two subclasses, Article.Class1 and Article.Class2. By default, when each class extends %Persistent IRIS creates independent storage structures for them. This will work as intended if the first class in the list of superclasses is %Persistent. But it also means that if there are any parameters in the main class, they will be lost, because only parameters from the first class in the list get inherited.

IRIS 2026.1 provided Partitioned Tables as a new option for large data sets
It's a great improvement as it offers standardization of this feature.
Though:
It was possible also before, matching requirements and leaving room for creativity.
less elegant with a bit more coding and fewer automatisms.
Today, coding assistants like Claude, GitHub Copilot and Cursor have transformed the way developers write code. However, these tools are limited by being isolated from the systems and data sources that developers work with daily. This limitation can be overcome through the Model Context Protocol (MCP), an open standard designed to connect AI assistants to external data sources and tools in a secure and standardized way.
In this review article, we'll explore the current state-of-the-art regarding the MCP within the InterSystems ecosystem.
install below 3 extensions
input connection details
IP:localhost
Port: 52773
choose global & http connection method
Input username and password of Intersystems management portal
screenshot for success connection:
This article presents a straightforward approach to automatically and efficiently tune hyperparameters for machine learning models using Optuna as the optimisation framework. We explore how to use both Optuna’s native storage options and InterSystems IRIS as a database backend to track the progress of hyperparameter searches. We also show how MLflow can be used to monitor experiments and manage models through its tracking and model registry UI.
This article is based on this Kaggle Notebook, which you can run and directly edit yourself.

When managing critical healthcare data through an integration engine you want to know the moment a queue starts backing up or a service drops.
Unfortunately, this usually leads to an email inbox stuffed full of notifications that can sometimes seem impossible to maintain.
Well, I’ve not solved that problem.
But I have created something that could help...
Hi Community,
Enjoy the new video on InterSystems Developers YouTube:
⏯ Advanced InterSystems IRIS Automation Using Ansible @ Ready 2025
Data privacy regulations such as GDPR, LGPD, and HIPAA demand that organizations know exactly where Personally Identifiable Information (PII) lives inside their databases. Yet in practice, most teams rely on manual inventories, tribal knowledge, or external scanning tools that require data to leave the database engine — a process that itself creates privacy and security risks.
This article presents an MVP that takes a different approach: it runs PII detection inside InterSystems IRIS using Embedded Python, analyzing data where it lives and never exporting it to an external process.
InterSystems IRIS globals are one of the platform's core strengths: they store hierarchical data in a direct, ordered, and efficient structure. But when working from Python, manipulating globals can sometimes feel closer to a low-level API than to the natural habits of the language.
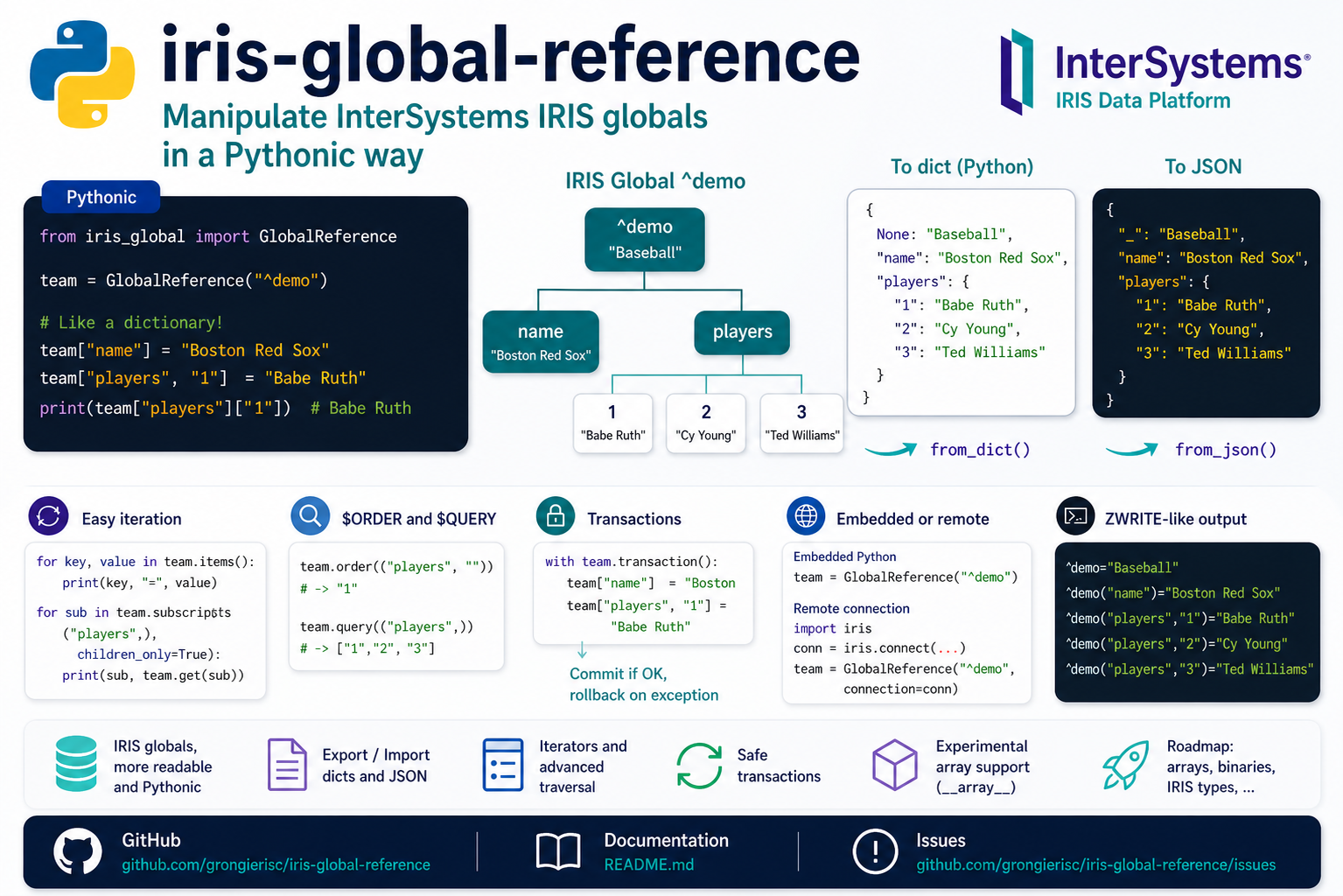
The iris-global-reference project provides a Python layer on top of IRIS globals. Its goal is simple: make access to globals more readable, more idiomatic, and easier to integrate into modern Python code, without hiding the underlying hierarchical model.
What is wrong with the *inc file code below:
#define ArrayToString(%array,%out,%del) set %out="" for { ##continue
set key=$order(%array("")) quit:key="" ##continue
set %out=%out_%del_key ##continue
} quit
Compilation at calling classmethod as : Set tQStr = $$$ArrayToString(pQArray,tQStr,"##") brings error as:
Hi Community,
Enjoy the new video on InterSystems Developers YouTube:
⏯ Productive Data Science with InterSystems IRIS and Python @ Ready 2025
I need to analyse and improve the performance on some old SQL statements.
One statement uses NVL in the WHERE clause (no wonder why it's slow) but I still have to improve the performance and the data really needs to be the same when returned.
SELECT *
FROM TOURHead, TOURFIND, SGNRFIND, TNRHead
WHERE TOURHead.cl = '123'
AND TOURHead.cl = TOURFIND.cl
AND TOURHead.TOURNR = TOURFIND.TOURNR
AND TOURFIND.cl =* SGNRFIND.cl
AND TOURFIND.SGNR =* SGNRFIND.SGNR
AND TOURFIND.cl = TNRHead.cl
AND NVL(TOURFIND.TNR, SGNRFIND.TNR) = TNRHead.TNR;
Really hope someone can help me with this one.
Many organizations that operate systems built on legacy technology stacks are facing significant support and maintenance complexities. They are eager to modernize, but the transition is usually prohibitively complex and expensive. These challenges apply to virtually any legacy tech, while InterSystems-based systems have their own unique nuances.
Key modernization challenges include:
Hi Community,
Enjoy the new video on InterSystems Developers YouTube:
⏯ Succeeding with Python Development on InterSystems IRIS @ Ready 2025
Hello, community.
I've been working with Intersystem Caché for two years, and right away I was excited about the rich ecosystem that Caché provides. However, I was disappointed with calls using #call, and I understand that it was a limitation of the time. Well, the frustration is that #call returns null by default, meaning an AJAX request is executed, but there's no hook to retrieve the return from that request. The only way to retrieve the data from that request is by building a callback on the server side using &js<>.
In healthcare interoperability environments, InterSystems Health Connect typically contains critical components such as productions, business processes, operations, services, utility classes, routines, and other ObjectScript artifacts. Traditionally, many deployments of these components have been done manually, by copying classes, importing XML, or using administrative tools from the management portal.
In our previous article, we explored the basics of unit testing in IRIS and the ways to apply it to a REST API. We even figured out how to test logic before finalizing network configurations and authentication, allowing us to focus solely on testing the API contents. Today, we will build upon that foundation and elevate our unit testing strategy by using another tool: %Populate .
At first glance, the %Populate class appears to be very simple. You can create a class that extends both %Persistent and %Populate and inherit a Populate method designed to generate randomized records.