New
Hi community,
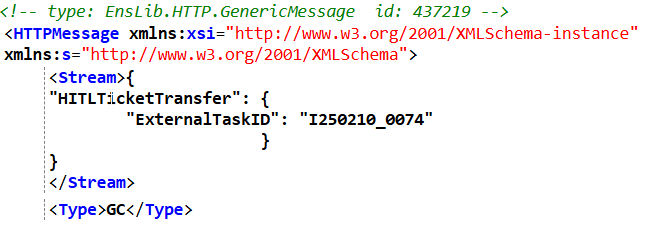
I've been working on a side project that I'd love to get some eyes on: a ground-up rebuild of the classic IRIS Production Monitor using a modern web stack. The existing ZEN/CSP-based portal does the job, but I wanted to explore what a contemporary, real-time version of it could look like.
What it is
A standalone Angular web application that connects to any Interoperability-enabled IRIS namespace and gives you a live view of your production — services, processes, operations, queues, event log, and message traffic — all in one screen.