Hi community,
my database (HSAUDIT) is only on the read mode , how can i pass to the Read/Write mode?
thank's
This tag includes content related to databases as systems for storing, organizing, and managing data. Covers concepts such as data models, querying, indexing, performance, and best practices for working with structured and unstructured data.
Hi community,
my database (HSAUDIT) is only on the read mode , how can i pass to the Read/Write mode?
thank's
I am trying to replace one of our SQL Integration Service jobs with Ensemble and I am running into an issue executing a query against a MS SQL database using JDBC drivers.
My SQL Outbound code looks like this.
Method SelectPaceartCharges(As
have set the query property to a max length of 10000.
Property query As %String(MAXLEN = 10000);
I have two databases, and both of them have a global ^Data with subscripts going from 1 to 10 000 000.
I want to get one database with global ^Data but with subscripts going from 1 to 20 000 000.
Since each db is around 100 Gb and they are on a different hosts, what's the best way to merge them?
It was my answer to the question appeared in GoogleGroups. And when I answered there I figured out that it might worth to post an article and to add some light on how Unicode is stored in Caché.
Recently, we scheduled two tasks (1008 and 1009) within Task Manager. Task ID 1008 is set to run after Purge Tasks (%SYS-ID:3), and Task 1009 is set to run at 7:00:00 each day.
In attempt to provide as much detail as possible, each of the tasks are as follows:
WHILE (($p($h,",",2) < $ZTH("10:00 PM")) && ($P($g(^Task.1008(+$h,$j)),"^",1) = +$h)) { J ^ROUTINE, ^ROUTINE2 D SUB^ROUTINE3 H 5 }WHILE (($p($h,",",2) < $ZTH("10:00 PM")) && ($P($g(^Task.1009(+$h,$j)),"^",1) = +$h)) { d ^ROUTINE4, ^ROUTINE5 J SUB^ROUTINE6 }While creating namespaces, there is a provision for keeping the data, and code separately in database.
What I am looking for,
What are the benefit we can achieve by doing this?
Is there any documentation of article which might help understanding?
Thanks You!
In which global cache class codes are storing in cache DB?
For example, Routine codes are storing in ^ROUTINE global.
situation: Need to read line by line and need to replace one string to another string in class files(.cls file) using programming.
Need to replace Property type in class files using programming i mean via programming to edit the class files
MonCaché — MongoDB API implementation based on InterSystems Caché
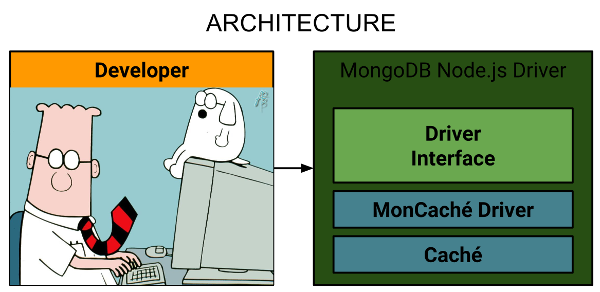
The idea of the project is to implement basic MongoDB (v2.4.9) API features for searching, saving, updating and deleting documents in a way that will allow the use of InterSystems Caché instead of MongoDB without changing the code on the client side.
Perhaps, if we take an interface based on MongoDB and use InterSystems Caché for data storage, we may see a performance boost.

Have you noticed that what ever the model and data structure in databases we cannot escape from the fundamental principle of managing data allocation space with references, i.e. pointer based logic, memory addressing ? Isn’t this the fundamental mechanism of programming languages too ? The problem I see with all these modern NoSQL databases, especially graph databases is that they provide a higher level abstraction for the end developer but they hide and lock completely the access to the low level storage and retrieval mechanism including indexes.
Hi,
I would like to draw your attention on a recently published article, titled "A Quick Guide on How to Prevail in the Graph Database Arena", that has been posted also at LinkedIn Intersystems Caché has been referenced several times.
We are running Caché v2010.2 on OpenVMS and are receiving the message, 'Unable to start the database read test' in our CCONSOLE.LOG.
I was wondering if anyone could offer some insight on this as I was not able to find the error mentioned in the documentation.
Does anyone know of a utility to compare two databases (i.e., CACHE.DAT files) and find globals/subscripts that are different between them?
If not, I'll write one and share it. ![]()
Hi,
I use cache 5.0 and access cache through OpenVMS.
The disk-space under a particular namespace has grown up in size due to cache.dat. How to recreate cache.dat to bring up more space back on disk?
I'm trying to recreate a smaller copy of our DEV machine on a sandbox instance. I installed a new instance, and thought it would be a good idea to copy over a few cache.dat files from the critical namespaces (but not all of them), and start from there.
However, I can't compile any UI files in my new instance because I'm getting a <PROTECT> error on the %qCacheMsg global -- for any element that displays text (i.e. the first <label> that's encountered) the generated code is trying to get text from the global ^%qCacheMsg("%Utility","en",node) = text -- from a node that doesn't exist.
Greetings,
How do I organize a wildcard search with respect to a database search?
Example of what I am trying to do: s x=$o(^G("ABC","A*",x))
Trying to navigate through the ^G global for all occurrences of "ABC", and "A*" ("A"+wildcard) but I am new to M and don't know positively how to do this. Perhaps I don't use an "*" at all, rather; another convention altogether.
Please advise.
Thanks in advance for everyone's assistance.
During a Caché system management training course today we discussed structural database integrity (a.k.a. physical integrity) and the tools InterSystems provides for checking integrity and fixing problems.
I need to execute a single csession command which calls a multi-parameter routine, such as ^SECURITY. This will be to do things such as create databases, resources, etc. (see below). When I run the command all at once, I get a PARAMETER error.
We have multiple server and multiple namespace.
I have a script having sql query which fetch data from current namespace of a server.
If I want to run the same query on different server to fetch data, but I want to run that script on just one server for all server.
Please let me know how can I proceed.
Hi Everyone,
Link to webinar recording: https://learning.intersystems.com/course/view.php?id=623
Thank you for your interest in this webinar!
Please submit questions about the content of the webinar as comments below this article.
The webinar covers two topics: monitoring message activity and volume and monitoring disk space. I summarize and motivate the topics in the following two sections. The information in this webinar and post applies to the Ensemble, Health Connect, and HealthShare products. For simplicity, I am only going to refer to Ensemble in this post.
Hi Everybody,
I'm trying to restore database to a 2016.2.2.853 caché version but i've some problems ...
Into my backup file, i've 6 namespaces. After use the Do ^DBREST and configure all namespace into the portal, I can only reach 2 of 6.
when I write zn "blabla" into the terminal, i've got this error message :
ZN "blabla"
^
<DIRECTORY> *r:\data\blabla
Of course, Database and namespace are correctly define.
I've try this on a previous version of caché (2015.2.2.811) and it's working fine.
So, do you already got this kind of issue with your caché server ?
Tanks a lot for your help!
Sam
Currently, we have an application running in one namespace ("Database B") that has globals and routines mapped to another database ("Database A"). After enforcing clean up on Database A, we found that 90% of the disk is free. We would like to compact Database A and release the unused space. However, we are running OpenVMS, which seems to be the issue.
For databases consisting of only globals, we are able to use ^GBLOCKCOPY; however, we need to ensure that the routines and mappings are also copied.
What would be the best recommended way to do this?
Can someone direct me to where in the documentation we can find how consumption may be calculated for global storage?
| Caché Version | 2010.1 |
| Operating System | HP OpenVMS 8.4 |
EDIT: After receiving some responses, it seems I was unclear in my initial inquiry. I am looking to determine our rate of consumption of storage; however, I am having some difficulty in doing that.
While utilizing ^%GSIZE, which is used by the %GlobalEdit class, the results appeared odd. I have provided my results below, which illustrate the global structure on the left and the usage indicated by ^%GSIZE on the right.
Currently, namespace Alpha is configured to use database AlphaDB as its global database. How would we go about having namespace Alpha configured to use database AlphaDB for its global database except where global ^Customers(CustomerId) has a CustomerId greater than 10M, which we would like to have it redirected to database BetaDB.
In other words, ^|"AlphaDB"|Customers contains all customers between 1 and 10,000,000; and ^|"BetaDB"|Customers contains all customers greater than 10,000,000. Any help would be appreciated.
Good Morning
I have to create a new code table with data from a spreadsheet. This spreadsheet has 170 rows of data.
Is there any easy way of importing the data from Excel into my new Code Table?
Thank You
Hello. When you export and then import a table of data, is the import smart enough to figure out if a row already exists in the new namespace, and if so update the row rather than just save/add the row?
For example, we have a table in DEV, and the same table in QA. The DEV table has more fields than QA. When we moved up the class, the field definitions went with the table into QA, so now the table definition is the same in both.
We need to export the data from DEV and import it into QA, but file each row in QA as an existing row, and just update its data.
We don't often use SQL within our org, which is mostly due to the performance issue we experience due to the quantity of data we are reviewing.
Aside from the standard performance measures for non-Caché databases, are there any recommended approaches when querying large tables?
The table would have roughly 50M records, but there are not a finite amount of sub-nodes.
November 22, 2016 – Alert: Database Integrity on UNIX® and Linux Platforms
InterSystems has corrected a defect that may, in rare circumstances, result in database degradation on UNIX and Linux platforms.
This defect affects Caché, Ensemble, and HealthShare distributions beginning with Caché version 2012.1. It is only a possible risk on UNIX and Linux platforms that are using asynchronous I/O for database writes. The following table specifies if asynchronous I/O is always on or optional for the affected platforms and releases:
|
Platform |
Versions 2012.1 to 2015.1 |
Version 2015. |
I get this on some queries in some namespaces. For instance, this query:
It works fine in HSBUS but in HSREG it throws the error.
Server closed communication device
Does anyone know what would cause this? Would it log something more useful somewhere?
Hi,
How to change READ ONLY Database to READ/WRITE Could not find an option to edit it.
PS: Cache 2016.1.0.656
Thanks, Sansa.S
Hello, I would like to know if CACHE has any limitations on uploading files.
Why am I asking this, why am I going through a problem here.
What happens is that when uploading files or images that are larger than 2.7 MB CACHE is limiting the size to 2.7 MB, any file larger than that is saved corrupted.
Already at the time of uploading the file or image, CACHE is limiting the size of the file to 2.6 MB.