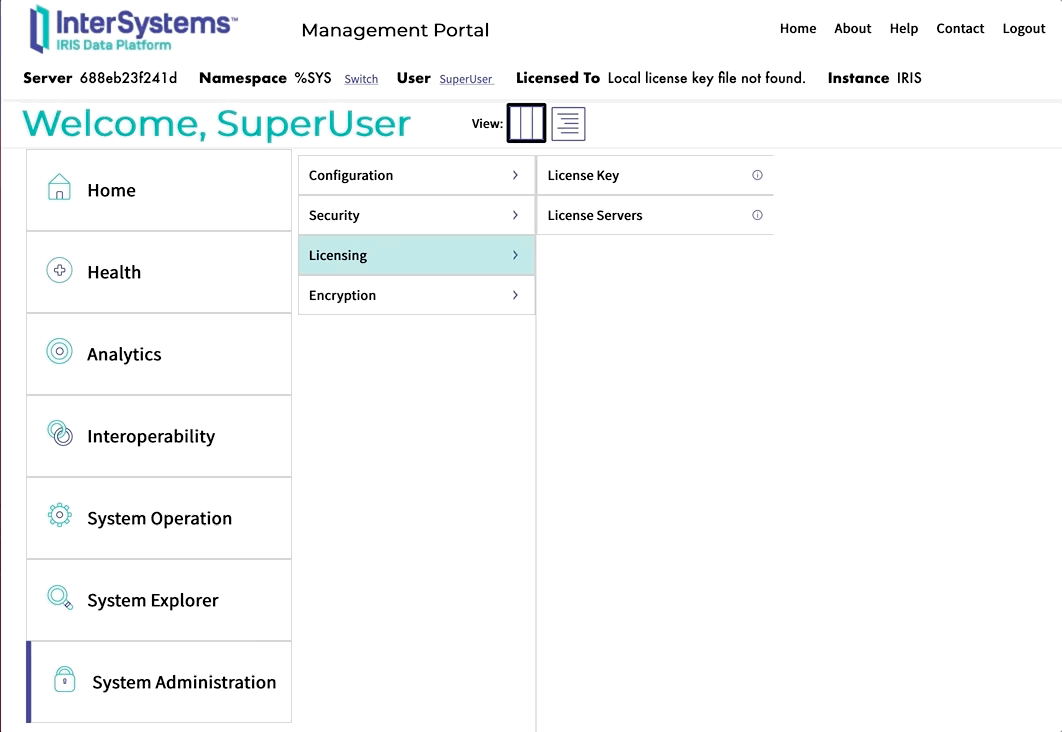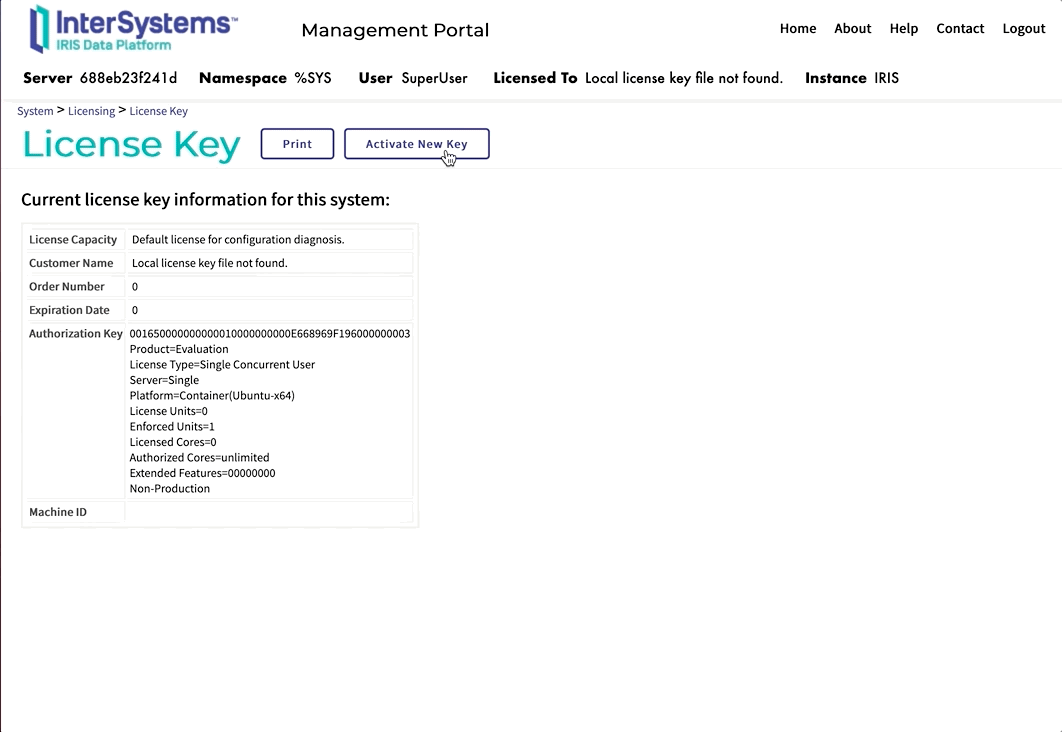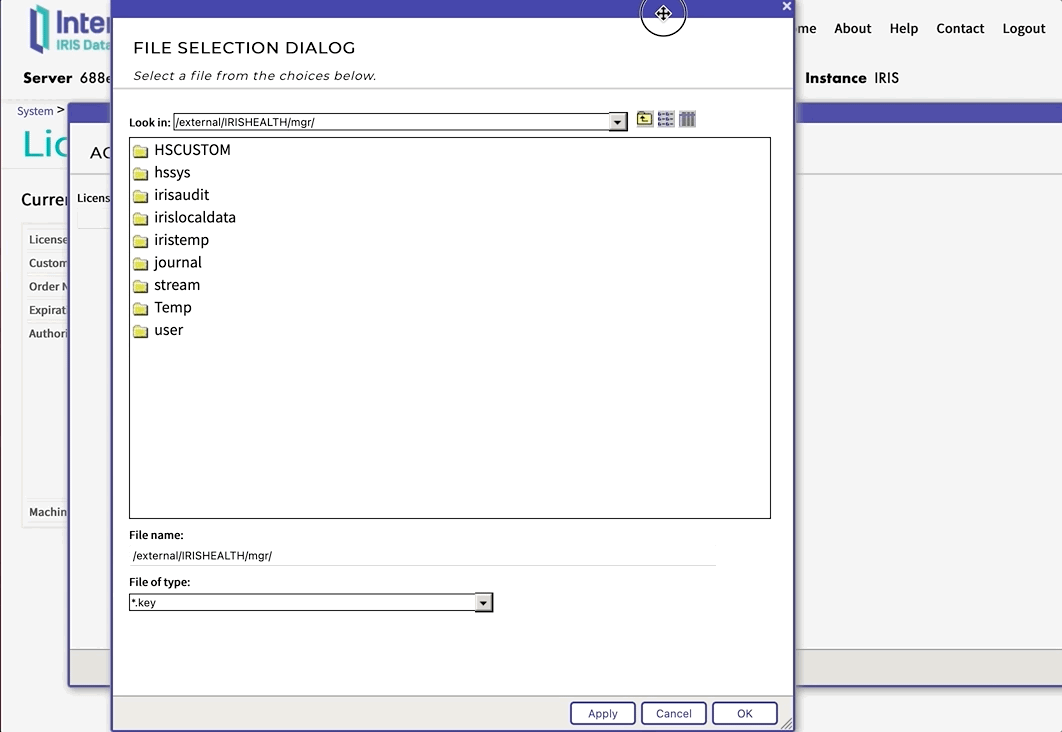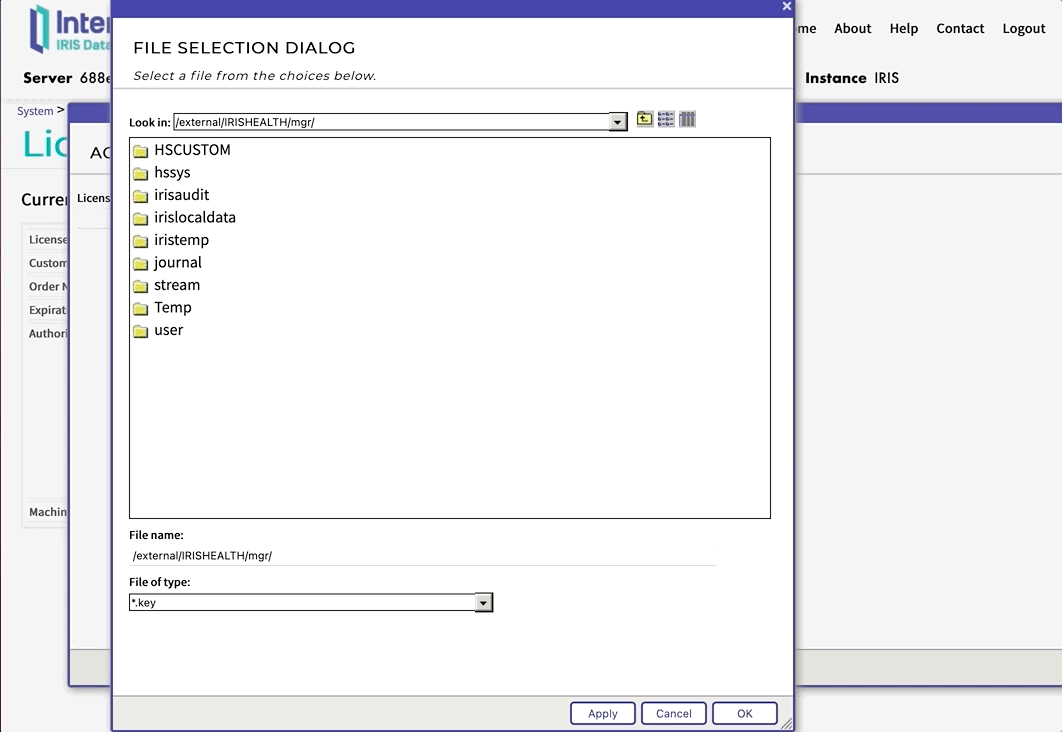
May I ask what the solution is to the error below?
Recovery started at Fri Apr 23 09:14:58 2021
Current default directory: c:\intersystems\cache\mgr
Log file directory: c:\intersystems\cache\mgr\
WIJ file spec: c:\intersystems\cache\mgr\CACHE.WIJ
Recovering local (c:\intersystems\cache\mgr\CACHE.WIJ) image journal file...
Starting WIJ recovery for 'c:\intersystems\cache\mgr\CACHE.WIJ'.
 339
339