With IRIS 2021.1, we released a significant revision our SQL utilities API at %SYSTEM.SQL. Yes, that's a while ago now, but last week a customer asked a few questions about this and then @Tom Woodfin applied gentle mental pressure ;-) to make me describe the rationale of these changes in a little more detail on the Developer Community. So here we go!
This is the third article in our short series around innovations in IRIS SQL that deliver a more adaptive, high-performance experience for analysts and applications querying relational data on IRIS. It may be the last article in this series for 2021.2, but we have several more enhancements lined up in this area. In this article, we'll dig a little deeper into additional table statistics we're starting to gather in this release: Histograms
Benjamin De Boe wrote this great article about Universal Cached Queries, but what the heck is a Universal Cached Query (UCQ) and why should I care about it if I am writing good old embedded SQL? In Caché and Ensemble, Cached Queries would be generated to resolve xDBC and Dynamic SQL. Now i
The Caché System Management Portal includes a robust web-based SQL query tool, but for some applications it’s more convenient to use a dedicated SQL client installed on a user’s PC.
SQuirreL SQL is a well known open source SQL client built in Java, which uses JDBC to connect to a DBMS. As such, we can configure SQuirreL to connect to Caché using the Caché JDBC driver.
Order is a necessity for everyone, but not everyone understands it in the same way
(Fausto Cercignani)
Disclaimer: This article uses Russian language and Cyrillic alphabet as examples, but is relevant for anyone who uses Caché in a non-English locale. Please note that this article refers mostly to NLS collations, which are different than SQL collations. SQL collations (such as SQLUPPER, SQLSTRING, EXACT which means no collation, TRUNCATE, etc.) are actual functions that are explicitly applied to some values, and whose results are sometimes explicitly stored in the global subscripts. When stored in subscripts, these values would naturally follow the NLS collation in effect (“SQL and NLS Collations”).
What is Unstructured Data? Unstructured data refers to information lacking a predefined data model or organization. In contrast to structured data found in databases with clear structures (e.g., tables and fields), unstructured data lacks a fixed schema. This type of data includes text, images, videos, audio files, social media posts, emails, and more.
With the release of InterSystems IRIS Cloud SQL, we're getting more frequent questions about how to establish secure connections over JDBC and other driver technologies. While we have nice summary and detailed documentation on the driver technologies themselves, our documentation does not go as far to describe individual client tools, such as our personal favourite DBeaver. In this article, we'll describe the steps to create a secure connection from DBeaver to your Cloud SQL deployment.
This article is an overview of SQLAlchemy, so let's begin!
SQLAlchemy is the Python SQL toolkit that serves as a bridge between your Python code and the relational database system of your choice. Created by Michael Bayer, it is currently available as an open-source library under the MIT License. SQLAlchemy supports a wide range of database systems, including PostgreSQL, MySQL, SQLite, Oracle, and Microsoft SQL Server, making it versatile and adaptable to different project requirements.
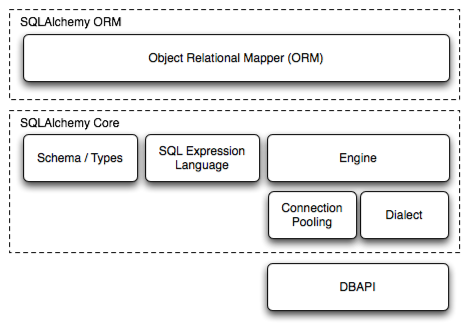
The SQLAlchemy SQL Toolkit and Object Relational Mapper from a comprehensive set of tools for working with databases and Python. It has several distinct areas of functionality which you can use individually or in various combinations. The major components are illustrated below, with component dependencies organized into layers:
The Certification Team of InterSystems Learning Services is in the process of developing two exams focused on using SQL in InterSystems IRIS and we need input from our InterSystems IRIS SQL community. Your input will be used to evaluate and establish the contents of the exam.
How do I provide my input? We will present you with a list of job tasks, and you will rate them on their importance as well as other factors.
Say you have a receiving system that accepts HL7 and provides error messages in field ERR:3.9 in the ACK it returns. You require a different reply code action depending on the error message, however the Reply Code Actions settings for the operation do not provide this level of granularity. One option could be to create a process that takes the ACK and then completes the action you were expecting, however things can get a bit messy if the action is to retry the message, especially when trying to view a message trace.
Sometimes we need to import data into InterSystems IRIS from CSV. It can be done e.g. via csvgen tool that generates a class and imports all the data into it.
But what if you already have your own class and want to import data from CSV into your existing table?
There are numerous ways to do that but you can use csvgen (or csvgen-ui) again! I prepared and and example and happy to share. Here we go!
The newer dynamic SQL classes (%SQL.Statement and %StatementResult) perform better than %ResultSet, but I did not adopt them for some time because I had learned how to use %ResultSet. Finally, I made a cheat sheet, which I find useful when writing new code or rewriting old code. I thought other people might find it useful.
First, here is a somewhat more verbose adaptation of my cheat sheet:
There are three things most important to any SQL performance conversation: Indices, TuneTable, and Show Plan. The attached PDFs includes historical presentations on these topics that cover the basics of these 3 things in one place. Our documentation provides more detail on these and other SQL Performance topics in the links below. The eLearning options reinforces several of these topics. In addition, there are several Developer Community articles which touch on SQL performance, and those relevant links are also listed.
There is a fair amount of repetition in the information listed below. The most important aspects of SQL performance to consider are:
The types of indices available
Using one index type over another
The information TuneTable gathers for a table and what it means to the Optimizer
How to read a Show Plan to better understand if a query is good or bad
If you are looking to breathe new life into an old MUMPS application follow these steps to map your globals to classes and expose all that beautiful data to Objects and SQL.
If the above does not sound familiar to you please start at the beginning with the following:
Earlier in this series, we've presented four different demo applications for iKnow, illustrating how its unique bottom-up approach allows users to explore the concepts and context of their unstructured data and then leverage these insights to implement real-world use cases. We started small and simple with core exploration through the Knowledge Portal, then organized our records according to content with the Set Analysis Demo, organized our domain knowledge using the Dictionary Builder Demo and finally build complex rules to extract nontrivial patterns from text with the Rules Builder Demo.
This time, we'll dive into a different area of the iKnow feature set: iFind. Where iKnow's core APIs are all about exploration and leveraging those results programmatically in applications and analytics, iFind is focused specifically on search scenarios in a pure SQL context. We'll be presenting a simple search portal implemented in Zen that showcases iFind's main features.
Recently I have been posting some updates to our JSON capabilities and I am very glad that so many of you provided feedback. Today I would like to focus on another facet: Producing JSON with a SQL query.
FOREIGN TABLES is a rather fresh feature in IRIS (2023.?) So I was motivated to try something new by own hands. Documentation of Foreign Table from File is a good starting point. Also the related promotional video is fine to start with.
In a customer project I was asked how you can keep track of database changes: Who changed what at which date and time. Goal was to track insert, update and delete for both SQL and object access.
This is the table that I created to keep the Change Log:
Last week at the InterSystems Global Summit, we announced our new Foreign Tables capability, which was introduced as an experimental feature with the 2023.1 release earlier this year.
An interesting pattern around unique indices came up recently (in internal discussion re: isc.rest) and I'd like to highlight it for the community.
As a motivating use case: suppose you have a class representing a tree, where each node also has a name, and we want nodes to be unique by name and parent node. We want each root node to have a unique name too. A natural implementation would be:
Sometimes when we develop a mockup or PoC there is a need for a simple interface that will provide data in IRIS in JSON against SQL queries.
And recently I contributed a simple module that does exactly that:
accepts SQL string and returns the JSON.
How to install? Just call:
zpm "install sql-rest"
If you install it in a namespace X it will setup a /sql endpoint to your system that will accept POST requests with SQL string and will return the result for you for the data available in the namespace X.
Hello community! I have to work with queries using all kinds of methods like embedded sql and class queries. But my favorite is dynamic sql, simply because of how easy it is to manipulate them at runtime. The downside to writing a lot of these is the maintenance of the code and interacting with the output in a meaningful way.
Every row-and-column intersection contains exactly one value from the applicable domain (and nothing else).
The same value can be atomic or non-atomic depending on the purpose of this value. For example, “4286” can be
atomic, if its denotes “a credit card’s PIN code” (if it’s broken down or reshuffled, it is of no use any longer)
non-atomic, if it’s just a “sequence of numbers” (the value still makes sense if broken down into several parts or reshuffled)
This article explores the standard methods of increasing the performance of SQL queries involving the following types of fields: string, date, simple list (in the $LB format), "list of <...>" and "array of <...>".
So I know it's been a while, and I hate to let my adoring fans down... just not enough to actually start writing again. But the wait is over and I'm back! Now bask in my beautiful ginger words!
For this series, I am going to look at some common problems we see in the WRC and discuss some common solutions. Of course, even if you find a solution here, you are always welcome to call in and expression you gratitude, or just hear my voice!
This week's common problem: "My query returns no data."
 By update
By update Open Exchange app
Open Exchange app