Collations in Caché
Order is a necessity for everyone, but not everyone understands it in the same way (Fausto Cercignani)
Disclaimer: This article uses Russian language and Cyrillic alphabet as examples, but is relevant for anyone who uses Caché in a non-English locale. Please note that this article refers mostly to NLS collations, which are different than SQL collations. SQL collations (such as SQLUPPER, SQLSTRING, EXACT which means no collation, TRUNCATE, etc.) are actual functions that are explicitly applied to some values, and whose results are sometimes explicitly stored in the global subscripts. When stored in subscripts, these values would naturally follow the NLS collation in effect (“SQL and NLS Collations”). Everything in Caché is stored in globals: data, metadata, classes, routines. Globals are persistent. Global nodes are ordered by subscript values, and stored on storage devices, not in insertion order, but in sorted order for better search and disk fetch performance:
USER>set ^a(10)=""
USER>set ^a("фф")=""
USER>set ^a("бб")=""
USER>set ^a(2)=""
USER>zwrite ^a
^a(2)=""
^a(10)=""
^a("бб")=""
^a("фф")=""
During sorting, Caché distinguishes numbers and strings — 2 is treated as number and sorts before 10. Command ZWrite and functions $Order and $Query return global subscripts in the same order these subscripts are stored: first empty string (you cannot use it as subscript), then negative numbers, zero, positive numbers, then strings in the order defined by collation (collation).
Standard collation in Caché is called (unsurprisingly) — Caché standard. It sorts each string accordingly to their Unicode character codes.
Collation for local arrays in current process is defined by locale (Management Portal > System administration > Configuration > System Configuration > National Language Settings > Locale Definitions). Russian locale for Caché Unicode installations is rusw, and default collation for rusw is Cyrillic3. Other possible collations in the rusw locale are Caché standard, Cyrillic1, Cyrillic3, Cyrillic4, Ukrainian1.
ClassMethod ##class(%Collate).SetLocalName() sets collation for local arrays in current process:
USER>write ##class(%Collate).GetLocalName()
Cyrillic3
USER>write ##class(%Collate).SetLocalName("Cache standard")
1
USER>write ##class(%Collate).GetLocalName()
Cache standard
USER>write ##class(%Collate).SetLocalName("Cyrillic3")
1
USER>write ##class(%Collate).GetLocalName()
Cyrillic3
For every collation, there is a fellow collation that sorts numbers as strings. Name of that collation contains “ string” in the end:
USER>write ##class(%Collate).SetLocalName("Cache standard string")
1
USER>kill test
USER>set test(10) = "", test(2) = "", test("фф") = "", test("бб") = ""
USER>zwrite test
test(10)=""
test(2)=""
test("бб")=""
test("фф")=""
USER>write ##class(%Collate).SetLocalName("Cache standard")
1
USER>kill test
USER>set test(10) = "", test(2) = "", test("фф") = "", test("бб") = ""
USER>zwrite test
test(2)=""
test(10)=""
test("бб")=""
test("фф")=""
Caché standard and Cyrillic3
Caché standard sorts characters accordingly to their codes:
write ##class(%Library.Collate).SetLocalName("Cache standard"),!
write ##class(%Library.Collate).GetLocalName(),!
set letters = "абвгдеёжзийклмнопрстуфхцчщщьыъэюя"
set letters = letters _ $zconvert(letters,"U")
kill test
//fill local array “test” with data
for i=1:1:$Length(letters) {
set test($Extract(letters,i)) = ""
}
//print test subscripts in sorted order
set l = "", cnt = 0
for {
set l = $Order(test(l))
quit:l=""
write l, " ", $Ascii(l),","
set cnt = cnt + 1
write:cnt#8=0 !
}
USER>do ^testcol
1
Cache standard
Ё 1025,А 1040,Б 1041,В 1042,Г 1043,Д 1044,Е 1045,Ж 1046,
З 1047,И 1048,Й 1049,К 1050,Л 1051,М 1052,Н 1053,О 1054,
П 1055,Р 1056,С 1057,Т 1058,У 1059,Ф 1060,Х 1061,Ц 1062,
Ч 1063,Щ 1065,Ъ 1066,Ы 1067,Ь 1068,Э 1069,Ю 1070,Я 1071,
а 1072,б 1073,в 1074,г 1075,д 1076,е 1077,ж 1078,з 1079,
и 1080,й 1081,к 1082,л 1083,м 1084,н 1085,о 1086,п 1087,
р 1088,с 1089,т 1090,у 1091,ф 1092,х 1093,ц 1094,ч 1095,
щ 1097,ъ 1098,ы 1099,ь 1100,э 1101,ю 1102,я 1103,ё 1105,
Cyrillic letters are printed in the same order they go in Russian alphabet, except ‘ё’ and ‘Ё’. Their Unicode character codes are out of order. ‘Ё’ should be collated between ‘Е’ and ‘Д’ and ‘ё’ between ‘е’ and ‘д‘. That’s why Russian locale needs its own collation — Cyrillic3, which has letters in the same order as in Russian alphabet:
USER>do ^testcol
1
Cyrillic3
А 1040,Б 1041,В 1042,Г 1043,Д 1044,Е 1045,Ё 1025,Ж 1046,
З 1047,И 1048,Й 1049,К 1050,Л 1051,М 1052,Н 1053,О 1054,
П 1055,Р 1056,С 1057,Т 1058,У 1059,Ф 1060,Х 1061,Ц 1062,
Ч 1063,Щ 1065,Ъ 1066,Ы 1067,Ь 1068,Э 1069,Ю 1070,Я 1071,
а 1072,б 1073,в 1074,г 1075,д 1076,е 1077,ё 1105,ж 1078,
з 1079,и 1080,й 1081,к 1082,л 1083,м 1084,н 1085,о 1086,
п 1087,р 1088,с 1089,т 1090,у 1091,ф 1092,х 1093,ц 1094,
ч 1095,щ 1097,ъ 1098,ы 1099,ь 1100,э 1101,ю 1102,я 1103,
Caché ObjectScript has a special binary operator ]] — «sorts after». It returns 1, if subscript with first operand sorts after subscript with second operand, and 0 otherwise:
USER>write ##class(%Library.Collate).SetLocalName("Cache standard"),!
1
USER>write "А" ]] "Ё"
1
USER>write ##class(%Library.Collate).SetLocalName("Cyrillic3"),!
1
USER>write "А" ]] "Ё"
0
Globals and collations
Different globals in the same database may have different collation. Each database has a configuration option — default collation for new globals. Right after the installation all databases except USER use the default collation of Caché standard. Default collation for USER database is determined by installation locale. For rusw it is Cyrillic3.
To create a global with collation that is non-default for its database use ##class(%GlobalEdit).Create method:
USER>kill ^a
USER>write ##class(%GlobalEdit).Create(,"a",##class(%Collate).DisplayToLogical("Cache standard"))
There is a collation column for each global In list of globals in Management Portal (System Explorer > Globals).
You cannot change collation of existing global. You should create global with new collation and copy data with Merge command. To do mass conversion of globals use ##class(SYS.Database).Copy()
Cyrillic4, Cyrillic3, and umlauts
It turns out that conversion of string subscript to internal format takes noticeably more time with Cyrillic3 collation than with Caché standard collation, therefore insert and lookup for global (or local) array with Cyrliic3 collation is slower. Caché 2014.1 contains new collation — Cyrillic4 that has the same correct order of letters as Cyrillic3 and better performance.
for collation="Cache standard","Cyrillic3","Cyrillic4" {
write ##class(%Library.Collate).SetLocalName(collation),!
write ##class(%Library.Collate).GetLocalName(),!
do test(100000)
}
quit
test(C)
set letters = "абвгдеёжзийклмнопрстуфхцчщщьыъэюя"
set letters = letters _ $zconvert(letters,"U")
kill test
write "test insert: "
//fill local array “test” with data
set z1=$zh
for c=1:1:C {
for i=1:1:$Length(letters) {
set test($Extract(letters,i)_"плюс длинное русское слово" _ $Extract(letters,i)) = ""
}
}
write $zh-z1,!
//looping through test subscripts
write "test $Order: "
set z1=$zh
for c=1:1:C {
set l = ""
for {
set l = $Order(test(l))
quit:l=""
}
}
write $zh-z1,!
USER>do ^testcol
1
Cache standard
test insert: 1.520673
test $Order: 2.062228
1
Cyrillic3
test insert: 3.541697
test $Order: 5.938042
1
Cyrillic4
test insert: 1.925205
test $Order: 2.834399
Cyrillic4 is not the default collation for rusw locale yet, but you can define your own locale based on rusw and specify Cyrillic4 as default collation for local arrays. Or you can set Cyrillic4 as the default new collation for globals in database settings.
Cyrillic3 is slower than Caché standard and Cyrillic4 because it is based on algorithm that is more general than sorting two strings based on individual character codes.
In German language letter ß should be collated as ss during sorting. Caché respects that rule:
USER>write ##class(%Collate).GetLocalName()
German3
USER>set test("Straßer")=1
USER>set test("Strasser")=1
USER>set test("Straster")=1
USER>zwrite test
test("Strasser")=1
test("Straßer")=1
test("Straster")=1
Please notice the sorting order of strings in subscripts. Particularly, that first four letters of first string are “Stras”, then “Straß”, and then again “Stras”. It is impossible to sort strings in that manner if collation is just a sorting based on the codes of separate characters.
Another example is the Finnish language where ’v’ and ‘w’ should be collated as the same letter. Russian language collation rules are simpler — giving each letter some particular code and then sorting by these codes is enough. That allowed to improve performance of collation Cyrillic4 over Cyrillic3.
Collation and SQL
Don’t confuse collation of array with SQL collation. The latter one is conversion applied to the string before comparison or using it as a subscript in index global. Default SQL Collation in Caché is SQLUPPER. This collation converts all characters to uppercase, removes space characters and adds one space at the beginning of the string. Other SQL Collations (EXACT, SQLSTRING, TRUNCATE) are described in the documentation.
It’s easy to mess things up when different globals in the same database have different collation, and local arrays have other collation. SQL uses CACHETEMP database for temporary data. Default collation for globals in CACHETEMP might be different from collation for Caché installation locale.
There is one main rule — for ORDER BY in SQL queries to return rows in expected order, collation of globals where data and indexes of relevant tables are stored should be the same as the default collation of CACHETEMP database and collation of local arrays. For more details — see the paragraph in documentation “SQL and NLS Collations”.
Let’s create test class:
Class Collation.test Extends %Persistent
{
Property Name As %String;
Property Surname As %String;
Index SurInd On Surname;
ClassMethod populate()
{
do ..%KillExtent()
set t = ..%New()
set t.Name = "Павел", t.Surname = "Ёлкин"
write t.%Save()
set t = ..%New()
set t.Name = "Пётр", t.Surname = "Иванов"
write t.%Save()
set t = ..%New()
set t.Name = "Прохор", t.Surname = "Александров"
write t.%Save()
}
}
Populate class with data (later you can try to use words from the previous example with the German language):
USER>do ##class(Collation.test).populate()
Run the query:
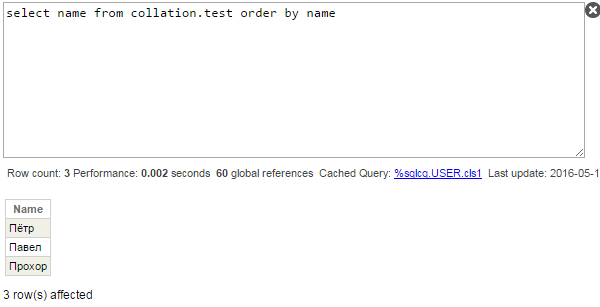
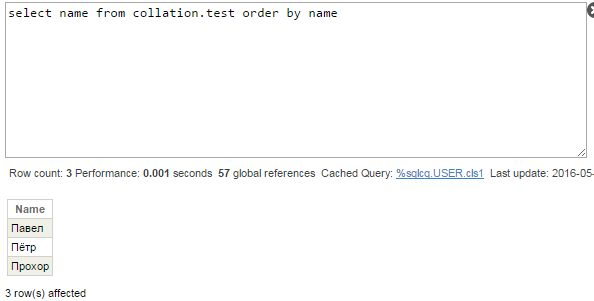
That is the unexpected result. The main question is why names are not ordered alphabetically? (Павел, Пётр, Прохор)? Let’s look at query plan:
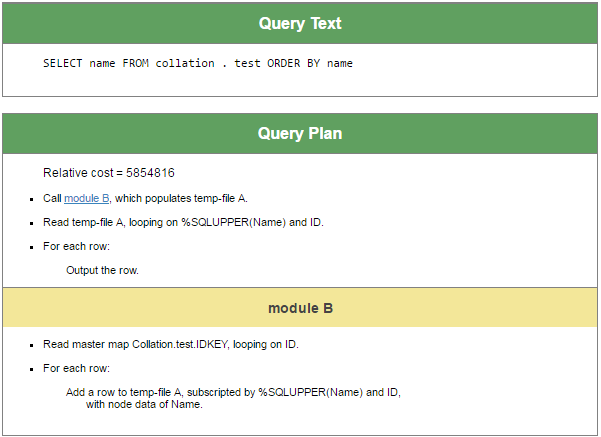
Key words in this plan are “populates temp-file”. SQL engine decided to use temporary structure to run this query. Although called “file”, really this is process-private global and in some cases local array. Subscripts of this global are values to order by, in this particular case — person names. Process-private globals are stored in CACHETEMP database and default collation for new globals in CACHETEMP is Caché standard.
Another reasonable question is why ‘ё’ is returned at the top and not at the bottom (remember, in Caché Standard ‘ё’ is sorted after all Russian letters and ‘Ё’ — before). Subscripts of temporary global are not exact value of Name field, but uppercased values of Name (SQLUPPER is default SQL collation for strings), and therefore ‘Ё’ is returned before other characters.
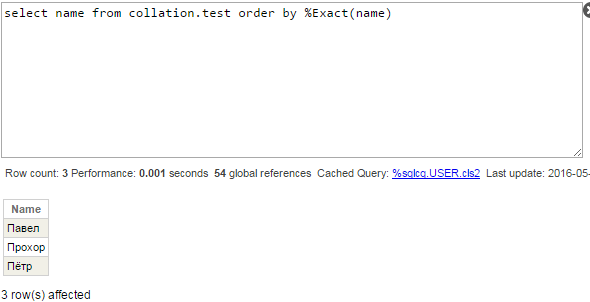
Modifying default collation using %Exact function, we would receive still incorrect, but at least expected result with ‘ё’ sorted after other letters.
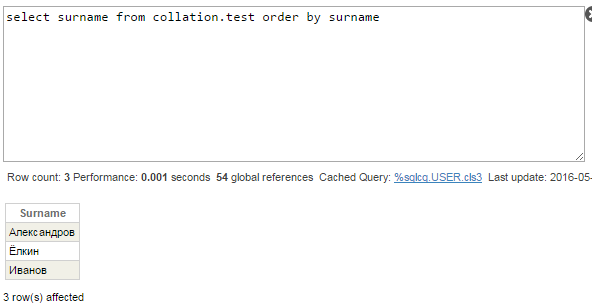
For now, let’s not change default collation of CACHETEMP — let’s check queries with Surname column. Index on this column is stored in ^Collation.testI global. Collation of that global is Cyrillic3, so we should see correct row order:
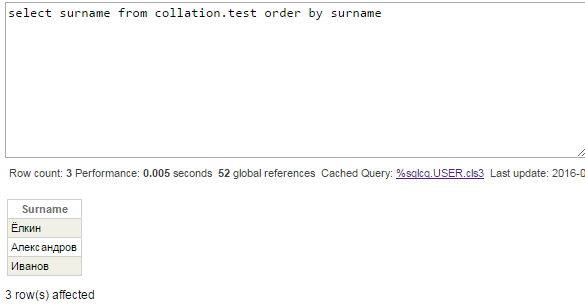
Wrong again — ‘Ё’ should go between ‘А’ and ‘И’. Look at the query plan:

Index data is not enough to output original values of Surname field because SQLUPPER is applied to values in SurInd index. SQL Engine decided to use values from the table itself and sort values in temporary file, just like it did before with Name column.
We can state in the query that we are OK with surnames in uppercase. The order will be correct because rows will be taken directly from index global ^Collation.testI:
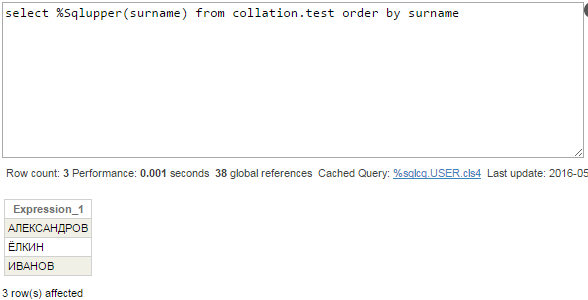
Query plan is as expected:

Now let’s do what we should have been done long ago — change default collation of CACHETEMP database to Cyrillic3 (or Cyrillic4).
Queries that use temporary files will output rows in correct order:
Summary
- If you don’t care for nuances of local alphabets — use collation Caché standard.
- Some collations (Cyrillic4) have better performance than others (Cyrillic3).
- Check that CACHETEMP has the same collation as your main database and local arrays.
Comments
Thank you for this really useful article, there is some great information here.
Useful article on collation basics. Especially useful for those who have to deal with the NLS.
There is also one more quite insidious subtle nuance (rather gotcha!) when one uses integer number as an index to massive and them somewhere else in code relies on collating.
Due to Integers' may not exceed 18 digits in length, starting from 19th digit (and further) - such indices are being treated as strings! Except, (here is gotcha #2) - if these digits (after 18th) are 0 (zeroes).
so
set ^a(123456789012345678)="numeric index"
set ^a("12345678901234567800")="numeric index"
set ^a("12345678901234567899")="string index"
Such annoyance may create problems at looping through arrays with long numeric indices. (For example - accounts' numbers as per RBU - that are of 20 digits in length)
Great article Alexander! One question. Why is there such difference in performance of $order? How could this affect to the general performance of an application using not Caché Standard for globals and mainly using SQL access to deal with data?
I've tested your ordering routing with Spanish2, 4 and 5 collations and are >4 times slower in inserts and order... !!!
Thank you Jose-Tomas.
As I understand (please see last three paragraphs of "Cyrillic4, Cyrillic3, and umlauts" section), Spanish language has some specific collation rules and satisfying these rules require more general (and complex) algorithm than sorting two strings based on individual character codes. That is why Spanish collations are slower then Caché Standard. https://en.wikipedia.org/wiki/Alphabetical_order#Language-specific_conventions
The more processing you application does besides looping with $Order/$Query and inserting data into global the less impact has collation performance. Running ^%SYS.MONLBL with globals/locals with different collation settings should give you more accurate performance data.
Comment on the statement that decimal numbers with more than 18 significant digits are strings. This is often true but it does not affect the accuracy of collating canonical numeric strings.
(1) Strings containing *canonical* representations of decimal numbers collate according to their numeric value and *NOT* according to their string value. (Every non-repeating decimal value has a unique canonical representation in COS. See http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY… for a description of the canonical numeric representation used by Caché.) This collation rule applies even for canonical numeric strings with many more that 19 significant digits.
(2) When Caché does arithmetic on decimal values it generates results with approximately 18.96 decimal digits of precision. I.e. all the integers between 1 and 9223372036854775807 can be represented as an arithmetic result. All the integers between 1000000000000000000 and 9223372036854775807 are integers with 19 digits of precision that can be the result of a Caché arithmetic computation. But the next larger decimal numbers that can result from a Caché arithmetic computation are 9223372036854775810, 9223372036854775820, 9223372036854775830 and so on up to 9999999999999999990. This range of decimal arithmetic will only have 18 digits of precision even though they represent 19 digit integer values. Then come 20 digit integers which go back to having 19 digits of precision starting with 10000000000000000000, followed by 10000000000000000010, 10000000000000000020, 10000000000000000030 and so on up to 92233720368547758070, which is largest 20 digit decimal integer with 19 digits of precision, the next possible arithmetic result is 92233720368547758100, which is a 20 digit number with only 18 digits of precision and which is followed by 92233720368547758200, etc. [[You can ignore these details unless you really need more than 18 digits of precision when doing arithmetic computations in the COS language.]]
Now for an example using canonical numeric strings with 20 digits with a mixture of 20, 19 and 18 significant digits. In this range of values Caché supports 19 digits of precision. We also have two non-canonical numeric strings which do not collate in numeric order but instead collate in character value order after all the canonical numeric strings have collated.
USER>set ^a("09")="noncanonical index"
USER>set ^a("01234567890123456780")="noncanonical index"
USER>set ^a("12345678901234567800")="numeric index"
USER>set ^a("12345678901234567870")="numeric index"
USER>set ^a("12345678901234567874")="string index"
USER>set ^a("12345678901234567876")="string index"
USER>set ^a("12345678901234567880")="numeric index"
USER>set ^a("12345678901234567890")="numeric index"
USER>set ^a("12345678901234567900")="numeric index"
USER>zw ^a
^a(12345678901234567800)="numeric index"
^a(12345678901234567870)="numeric index"
^a("12345678901234567874")="string index"
^a("12345678901234567876")="string index"
^a(12345678901234567880)="numeric index"
^a(12345678901234567890)="numeric index"
^a(12345678901234567900)="numeric index"
^a("01234567890123456780")="noncanonical index"
^a("09")="noncanonical index"
Note that strings containing canonical numbers with 20 significant digits (i.e., "12345678901234567874" and "12345678901234567876") have quotes around them because Caché cannot convert them to numeric format without rounding the low order significant digit into a zero digit. Note also that strings containing non-canonical numeric representation (i.e., "01234567890123456780" and "09") appear last with quotes around the subscript values because these string indices collate as string values. If you do arithmetic on the 20 digit canonical arithmetic strings (e.g., +"12345678901234567874" and +"12345678901234567876") then they will be treated as having the value of nearest decimal number with 19 significant digits (i.e., values 12345678901234567870 and 12345678901234567880 respectively.)
Note: given two canonical numeric strings then the COS "sorts after" operator, ]], returns 1 if the first canonical numeric string operand is greater-than than the second canonical numeric string operand. (I.e., the "]]"-operator returns 1 if the first string operand collates after the second string operand.) This greater-than collation when applied to canonical numeric strings is correctly computed regardless of the number of significant digits in the canonical numeric strings. However, using the COS numeric "greater-than" operator, >, will first convert the operands to numeric representation with only 18.96 digits of precision before doing the numeric comparison.
Examples:
USER>write "12345678901234567874" ]] "12345678901234567870"
1
USER>write "12345678901234567874" > "12345678901234567870"
0
The second write statement returns 0 because the numeric ">" operator rounds it first operand to 19 significant digits which will compare equal-to the numeric value 12345678901234567870.
Summary: When it comes to collating canonical numeric strings, the number of significant digits supported is limited only by the string length. When it comes to doing decimal arithmetic in Caché, the computational results are rounded so they have less than 19 decimal digits of precision.
I.e., the "]"-operator returns 1 if the first string operand collates after the second string operand.
That's true for String type collations only (e.g. Cache String, Cyrillic2 String, etc). For most other collations defined in Cache (traditionally called Numeric collations) which comply the rule "numbers go first" (e.g. Cache Standard, Cyrillic2) one should use "]]" as "collate after" operator. In common, "]]" seems to be the better choice as it uses current collation rather than String one. This small sample code can demonstrate the difference between "]" and "]]":
num
new b,a,i,i0
set b("12345678901234567870")="Num20" set b("12345678901234567874")="NotNum20"
set a=1E30,b(+a)=1,b(+a_"11")=11,b(+a_"111")=111,b(+a_"1a")="3a",a=3E30,b(+a)=3,b(+a_"33")=33,b(+a_"333")=333,b(+a_"1a")="4a"
set i="",i0="" for set i=$order(b(i)) quit:i="" write "(i]]i0)=",i]]i0," (i]i0)=",i]i0," (i>i0)=",i>i0," (i=+i)=",i=+i,?30," " zwrite b(i) set i0=i
quitThe result for Cache Standard collation is:
LEARN>d num^ztest
(i]]i0)=1 (i]i0)=1 (i>i0)=1 (i=+i)=1 b(12345678901234567870)="Num20"
(i]]i0)=1 (i]i0)=1 (i>i0)=0 (i=+i)=0 b("12345678901234567874")="NotNum20"
(i]]i0)=1 (i]i0)=0 (i>i0)=1 (i=+i)=1 b(1000000000000000000000000000000)=1
(i]]i0)=1 (i]i0)=1 (i>i0)=1 (i=+i)=1 b(3000000000000000000000000000000)=3
(i]]i0)=1 (i]i0)=0 (i>i0)=1 (i=+i)=0 b("100000000000000000000000000000011")=11
(i]]i0)=1 (i]i0)=1 (i>i0)=1 (i=+i)=0 b("300000000000000000000000000000033")=33
(i]]i0)=1 (i]i0)=0 (i>i0)=1 (i=+i)=0 b("1000000000000000000000000000000111")=111
(i]]i0)=1 (i]i0)=1 (i>i0)=1 (i=+i)=0 b("3000000000000000000000000000000333")=333
(i]]i0)=1 (i]i0)=0 (i>i0)=0 (i=+i)=0 b("10000000000000000000000000000001a")="3a"
(i]]i0)=1 (i]i0)=1 (i>i0)=1 (i=+i)=0 b("30000000000000000000000000000001a")="4a"Yes, in my original posting I meant to use the "sorts after" operator, ]], when I incorrectly used the "follows" operator, ]. I have corrected the original post.