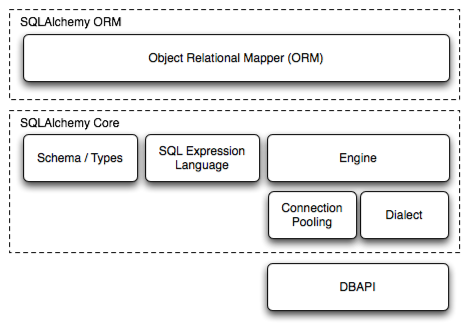
This is not an issue in ObjectScript, due to its typeless nature. But it's essential for external programming languages that care a bit more about types of variables.
And in any case, it's still reproducible in ObjectScript. I have table
CREATE TABLE some_table (
id INTEGER NOT NULL,
x INTEGER,
y INTEGER,
z VARCHAR(50),
PRIMARY KEY (id)
)
And data
INSERT INTO some_table (id, x, y, z) VALUES (1, 1, 2, 'z1');
INSERT INTO some_table (id, x, y, z) VALUES (2, 2, 3, 'z2');
INSERT INTO some_table (id, x, y, z) VALUES (3, 3, 4, 'z3');
INSERT INTO some_table (id, x, y, z) VALUES (4, 4, 5, 'z4');
 By views
By views.png)

 Open Exchange app
Open Exchange app.png)

.png)

.jpg)