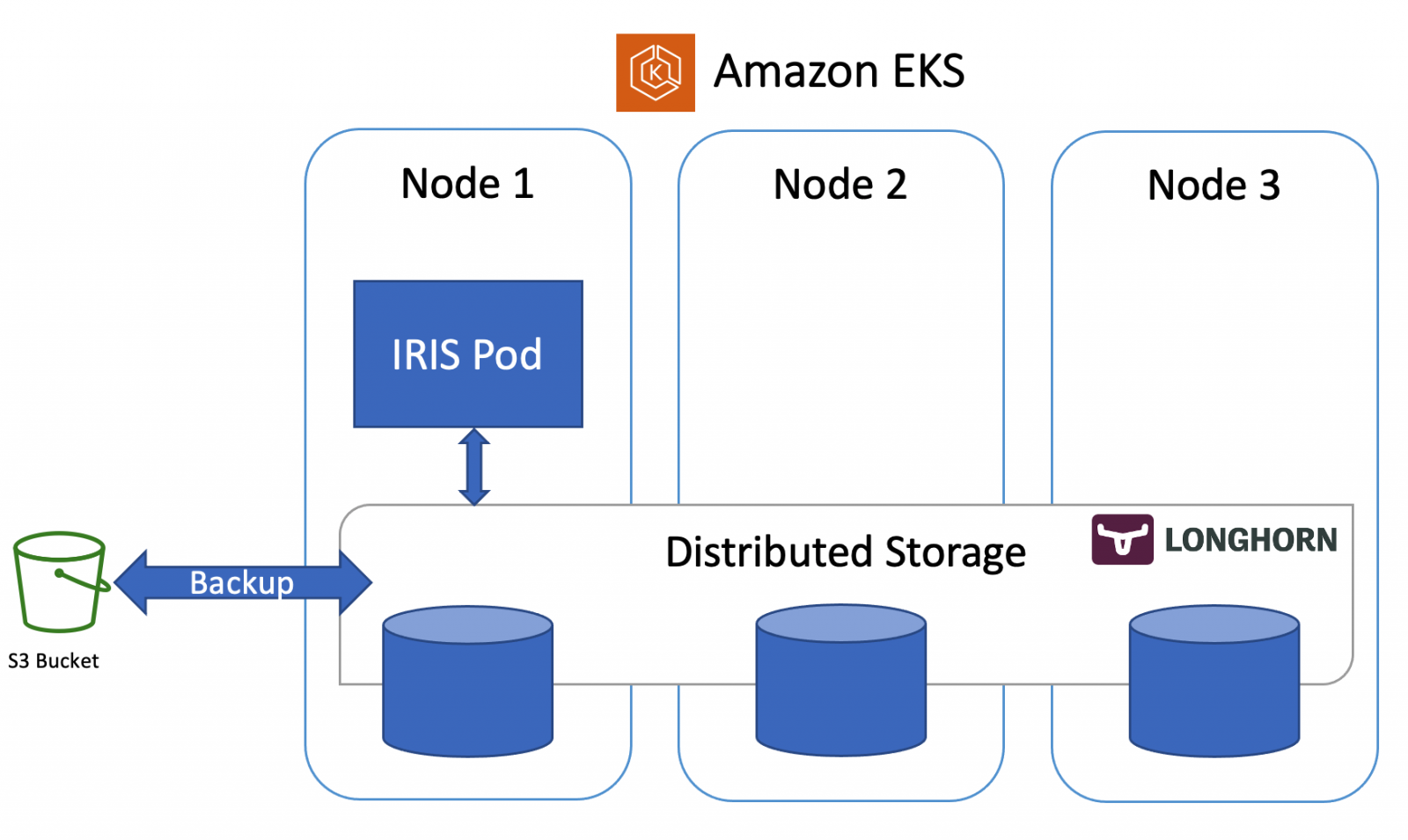
Some Usage cases
1. A deployment may consist of two high availability instances and two disaster recovery instances in a different data center.
The corresponding UAT environment could replicate this giving a total of 8 instances. How do you confirm CPF and Scheduled task alignment across ALL instances.
2. Another team (possibly in anther organization) makes changes to an IRIS instance to correct a problem, improve security, or modify shared system task configuration. Capture the CPF before and after to see what was done across instances.
.png)

.png)