Hi,
Working on integrating with O365 Sharepoint REST API. I would want to know if anyone can share their experience with integration with Sharepoint REST API and how they implemented security?
Thanks
Kiran Kumar
Hi,
Working on integrating with O365 Sharepoint REST API. I would want to know if anyone can share their experience with integration with Sharepoint REST API and how they implemented security?
Thanks
Kiran Kumar
Hello
I am trying to import a WSDL using the wizard and it outputs:
ERROR #6413: Element 'wsdl:binding:operation:msg': corresponding to message null : http://services.sanidad....
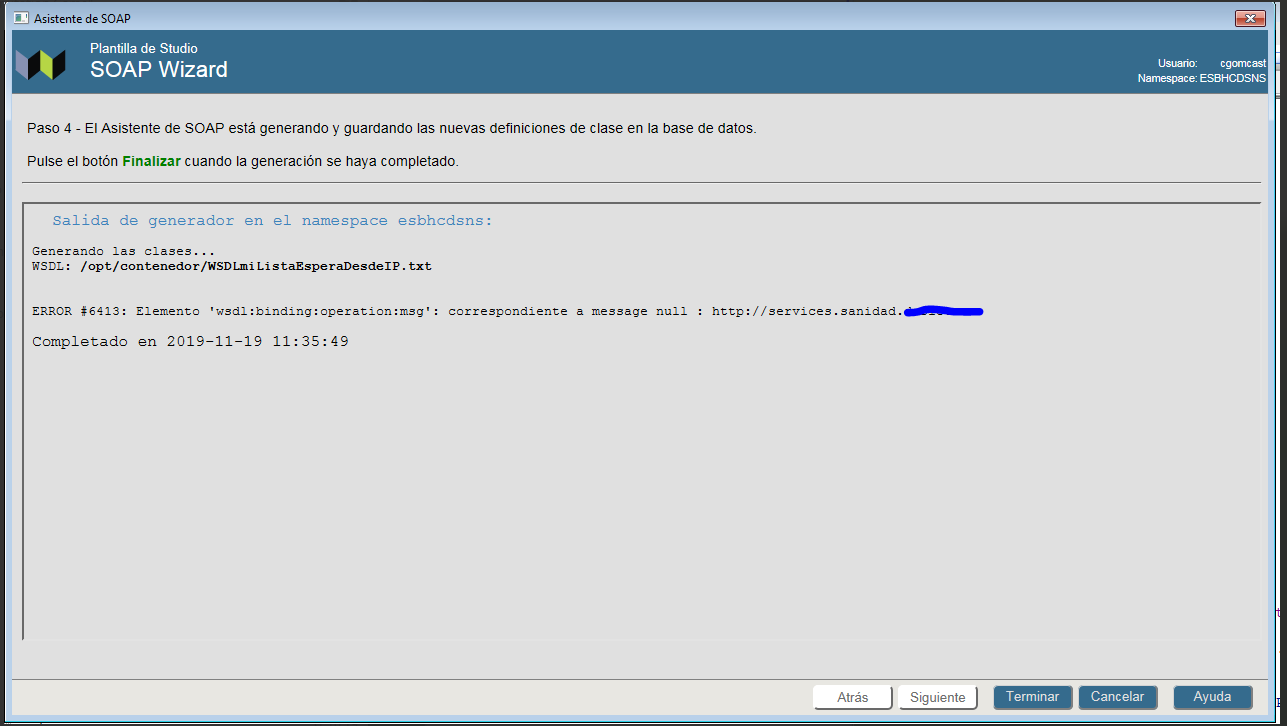
I have tried to find more information:
It is close to this case, however it is not the same error number:
Source: https://cedocs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?…
Here the error number does not give us much information:
Source: https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.
I'm trying to create a new Record Map but I keep getting a ZEN Exception error. I actually go this to work the very first time I did it and have a record map. But I need to do more.
I'm working on my local machine so I can grab a CSV (or txt in this case as it's pipe delimited) from the local directory. I pick the file I want to use but when I click OK i get a popup and the following error:
I am experiencing a problem with an EDI process that uses a SQL Batch Service to connect to our DEV environment. However, when we point the EDI service to our TEST server, it errors out.
I have checked every single property on our TEST and DEV servers as well as the properties on the associated tables. They are identical. Nothing has changed in the SQL either.
The EDI is a PUBSUB that generates X12 834s for various vendors. The SQL Batch Service is running a modified code that executes a stored procedure.
Hi,
I'm trying to establish a communication between my edge, which is in one server, with my HUB which is in another one.
In EDGE, when the HS.Gateway.HSWS.WebServices component sends a message to the HUB component, it receives the following error: "Cannot invoke method RegisterGateway; WebServiceClientClass 'HS.Hub.HSWS.WebServicesClient' could not be instantiated, or the WebServiceURL Location could not be determined".
May someone help me?
Trying to map two repeatable fields from a record mapper. The fields are separated by a ^. I've tried a fore each, but still getting an error when testing in the transform.
How can i access the model Patient class file from org.hl7.fhir.dstu3.model jar in spring boot
Hi
I am currently working with a "Stem Cell" supplier who do not have any/much Interface capability to push "Bone Marrow" harvest information. But willing to develop an HL7 feed/ WSDL capability.
It will be ideal, if I can get this via HL7 as much as possible and wondering if anyone has used HL7 to transmit bone marrow CD34, CD3 makers, product location and Harvest information? if so can you please advise which HL7 messages are ideal and some sample messages if possible please?
How about
1. R22 -Unsolicited Specimen Oriented Observation Message
2.
When publish my application on the iis server below function not working..
Public Shared Sub Connection()
Try
factory = CreateObject("CacheObject.Factory")
If Not factory.IsConnected() Then
Dim connectstring As String
connectstring = ConfigurationManager.AppSettings.Get("con")
Dim success As Boolean
success = factory.Connect(connectstring)
End If
Catch ex As Exception
Dim Err As New CreateLogFiles()
Err.ErrorLog(HttpContext.Current.Server.
Hello community,
I have a very weird situation that in the name space, when I choose the soap service for a component from Basic Settings->ServiceName dropdown menu, the service registry name is there. However, when I go to HealthShare management->Service Registry, there is not any service showing up. Then I am trying to add this service by clicking the Add Service button and fill out the api information, then I hit save button and it says that "Service with this name and service type already exists", which won't allow me to add this particular service.
Hi, i am trying to transform a mensage HL7 ORUR01. The segmnet OBX.5 is dynamic and i'm calling to subtranform item but fail.
this is the error:
ERROR <Ens>ErrException: <METHOD DOES NOT EXIST>zTransform+16 ^es.gra.informes.transformaciones.OBXToInforme.1 *GetSegmentAt,EnsLib.HL7.Segment -- - registrado como '-'
número - @'
Set zSrcOBJz=source.GetSegmentAt("5",.tSC1)'
<ORU_R01.OBSERVATION> <OBX> <OBX.1>1</OBX.1> <OBX.2>ED</OBX.2> <OBX.3> <CE.1>INFHEMAT</CE.1> <CE.2>INFORME HEMATOLOGIA</CE.2> </OBX.3> <OBX.5> <ED.1> <HD.1>1709265</HD.1> </ED.1> <ED.2>AP</ED.2> <ED.3>PDF</ED.3> <ED.4>Base64</ED.4> <ED.5>base64filedates</ED.5> </OBX.5> <OBX.11>F</OBX.11> </OBX> </ORU_R01.OBSERVATION>
I'm running SQL reports on some HL7 messages and need to report the raw content of both the outbound message and the ACK response.
When looking in a Visual Trace at an I/O (Ens.Util.IOLog), under the Header tab it lists "InObject" and "OutObject" as each having values - in the example I'm looking at, the OutObject value is the EnsLib.HL7.Message ID I need for the outbound message, and the InObject value is the EnsLib.HL7.Message ID I need for the ACK response. My thought was that I could query that class via SQL and do two joins on the EnsLib_HL7.
I need to split a large XMLfile into multiple smaller ones, grouping by an element multiple iterations deep.
In XSLT 2 I use for-each-group group-by, which perfectly does the trick.
I wonder if it is possible to do the grouping in DTL?
When a X12 message comes into Ensemble as a Whole Batch how do you search on a segment within the body of the message? For example, a REF segment. It appears the only way is to set the Service to a single session batch, but this doesn't allow you to send the message as a Whole Batch to the Operation.
We're moving an Ensemble production from Ensemble 2010 to Ensemble 2017 and in it we have a ebXML SOAP Service. It extends EnsLib.ebXML.Service.SOAPService and just contains one method with a method keyword of SoapAction = ebXML.
We're receiving a SOAP message with a SOAP action = urn:nhs:names:services:pdsquery/QUPA_IN000011UK02 and this is getting rejected with the error message ERROR #6207: Unexpected SOAPACTION value: urn:nhs:names:services:pdsquery/QUPA_IN000011UK02
We've narrowed down the cause of the failure to the Process method of class %SOAP.WebService. Where it does Set className=.
Hi guys,
I'm starting few POCs to test InterSystems IRIS with a .Net core backend of an API Gateway and I have few questions about this integration.
Hi,
I want to edit the the Master viewer /source UI of HealthShare Provider Directory with a property/ element of String type.
There are predefined CodeTables structure by which i can't add the Attributes of the above element because somehow above element attributes are different than the code Table structures .
Can we add a new Customize Code Table other than predefiend Code tables in the HealthShare Provider Directory ?
Is there any way or any tutorial by which we can edit the Master Viewer ?
As of Now , I have added the below code in Local.PD.
Hi All,
Is there a way to include the build files (dist folder files after building vuejs) into a CSP page.
Thanks,
Hey Developer Community,
I wanted to reach out and ask the group who is still using the Polymetric Dashboard? You can read about it in this older Community article.
It was created as a sample that is designed to be customized by you, so it is a community supported tool vs. an official InterSystems supported tool. I've noticed that it hasn't been updated in a while and some of the dependencies have some potential security vulnerabilities.
I am new to CCDs and I have a question for you all.
I need to take in a CCD from our EMR, filter out sensitive data then send it on as a CCD.
All feedback is appreciated.
Thanks
Hi All,
I try to validate SAML inbound Message in Cache. In Document mentioned following command.
Set assertion=..SecurityIn.FindElement("Assertion")
My question is based on SAML token key how to validate manually? without using above method any one give suggestions
Hi
Has anyone implemented the message bank functionality in particular in the UK and if so what are your experiences of it in particular for custom messages? We are thinking of using it as our long term store and would like any feedback on it. We use a mix of REST web services, custom messages, HL7v2 and FHIR messaging within the Health area (NHS Trust to be exact).
I would also be interested in which version you implemented this upon.
Thanks
Ian
Hi,
I have been trying to implement SPA using routing between two components in a CSP page.
If i use the line which i commented the page views and gets data from the vue instance (when not using the <route-view> and other 2 vue route functions below).
since i need to implement routing i am using as below, now the property "selectedYear" is not getting data from vue instane and i am getting the below error as well.
I dont know whether i am going down the right path.
please see my code below and help me
Good day.
The issue is related to Cache Studio. I wrote a plugin for creating reports using FastReport. The plugin is called via the context menu. In this case, the class is d ## (%ZFastReport.SourceControl) .InstallSorceControllAllNameSpace ().
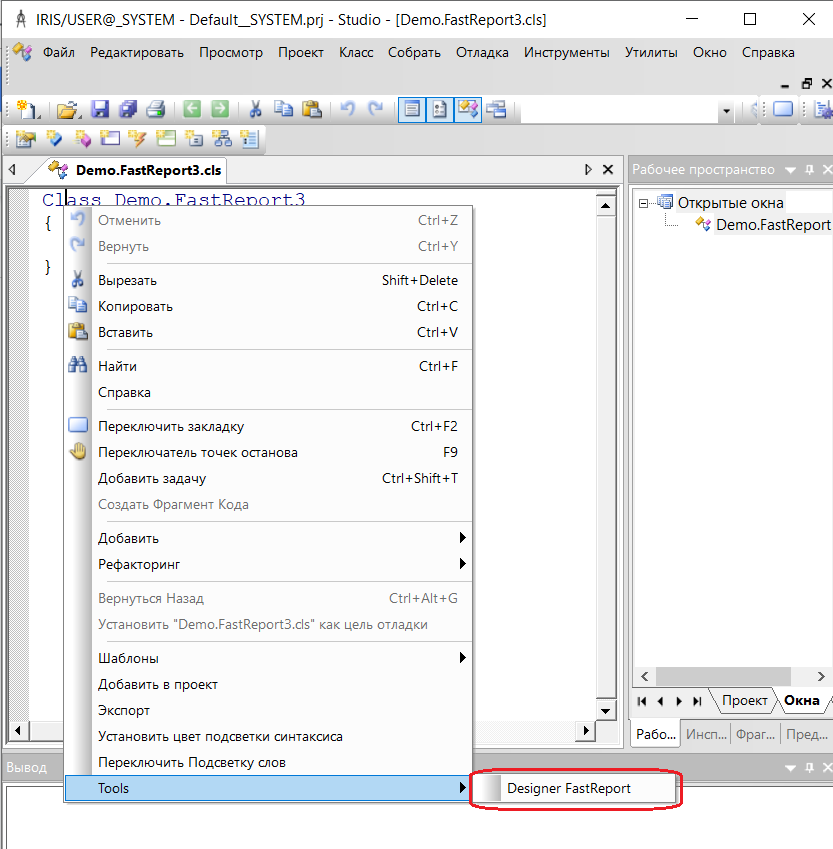
Example: https://github.com/MyasnikovIA/CacheFastReport
1) Tell me please, can I create a context menu for calling a program, without using a version control system?
2) How to determine the local location of the CStudio.exe file on the client side? The plugin is located on the client in the BIN directory.
Hello
Is there anyone who can convert this code From PHP TO CACHE in File (.mac)?
this is my function is empty :/
thank you all
.png)
| <?php $output_dir = "uploads/"; if(isset($_FILES["myfile"])) { $ret = array(); // This is for custom errors; /* $custom_error= array(); $custom_error['jquery-upload-file-error']="File already exists"; echo json_encode($custom_error); die(); */ $error =$_FILES["myfile"]["error"]; //You need to handle both cases //If Any browser does not support serializing of multiple files using FormData() if(! |
Does anyone have a tool or standard to anonymize CCDAs?
I would like to know any experience working with OPC UA standard in industry sector or IoT. Currently there is no adaptor implemented in IS IRIS for it but it seems to be pushed as the main standard in industry. Did anyone had to implement their own libraries or adaptors to deal with it? Or do you advice to use any already implemented library in Java, Python,...? Any feedback would be appreciated.
I can refer to the TracerName for a given ImageFile object with the following syntax: obj.Study.Injection.GetAt(obj.InjKey).RadioTracer.TracerName
Is it possible to write an SQL statement to search the PET.ImageFile table to find a match based on the RadioTracer.TracerName?
SQL gateway. 'Locking' problem.
while debugging, is there in Caché a command to 'unlock' the instance of a class ?
close class, and kill class is not enough.
same problem in %Activate link
for each debug I have to exit (Halt) the terminal,
make debug in C#
coming back , and re-load again in Caché.
Regards,
Emanuel
Hi, guys,
I've written a DT for a partner which transfers a csv file into SDA3.
I', using record map to gather data from a folder storing csv files and using the DT to tranfer the records into sda3 entities.
The followings are the codes of that DT:
Class POC.DT.CSV2SDA3 Extends Ens.DataTransformDTL [ DependsOn = (User.PhysicalExam.Record, POC.SDA.Container) ]
{
Parameter IGNOREMISSINGSOURCE = 1;
Parameter REPORTERRORS = 1;
Parameter TREATEMPTYREPEATINGFIELDASNULL = 0;
XData DTL [ XMLNamespace = "http://www.intersystems.com/dtl" ]
{

