Hello everybody,
In the documentation I read the following:
Alerts are messages generated by production components. InterSystems IRIS automatically writes the alerts to a log file and sends then to the production component named Ens.Alert. If your production does not have a component named Ens.Alert, then InterSystems IRIS writes alerts to the log file but does not send them to any component. The component named Ens.Alert can be of any class. The most frequently used classes for Ens.Alert are:
I am not able to find the log file where the alerts are stored.


.png)
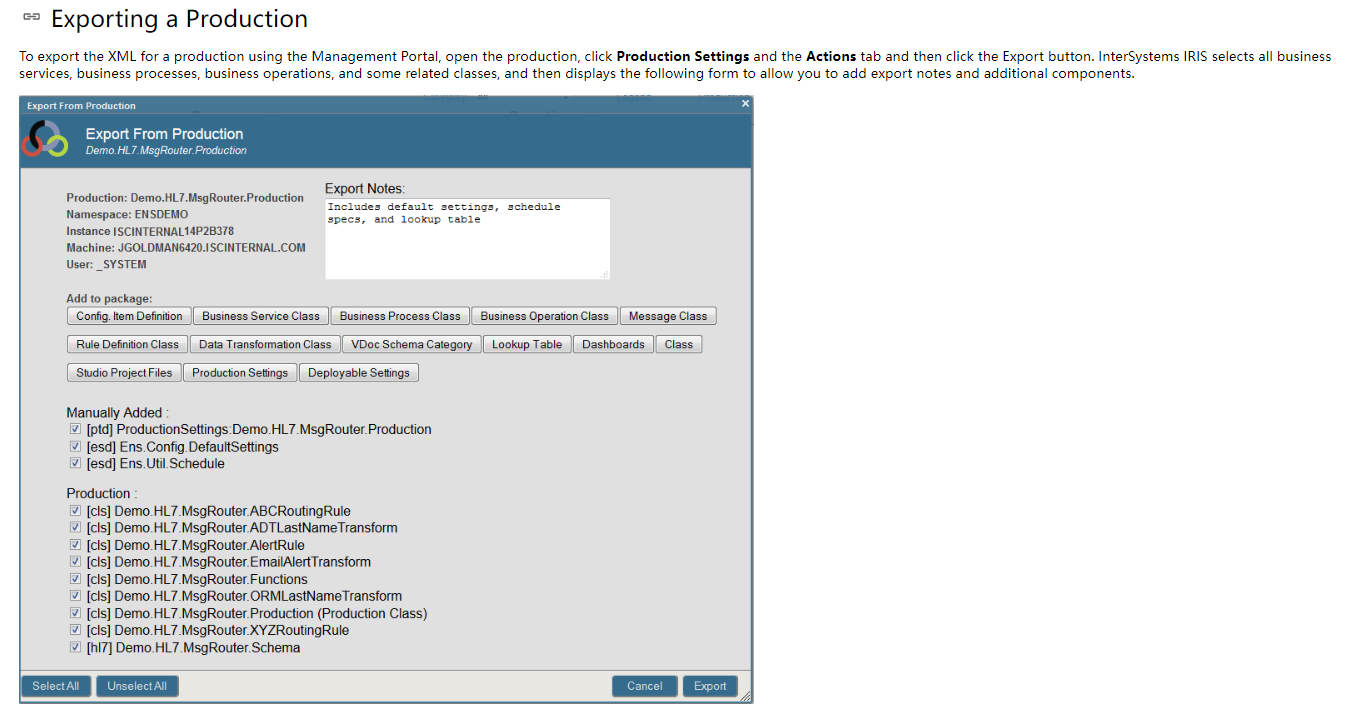
.png)

.png)

