 By date
By dateIs there a better way to iterate through all properties of an object than the following? Perhaps without needing to open a definition of the class but directly against the object?

InterSystems IRIS is a Complete Data Platform
InterSystems IRIS gives you everything you need to capture, share, understand, and act upon your organization’s most valuable asset – your data.
As a complete platform, InterSystems IRIS eliminates the need to integrate multiple development technologies. Applications require less code, fewer system resources, and less maintenance.
 Open Exchange app
Open Exchange app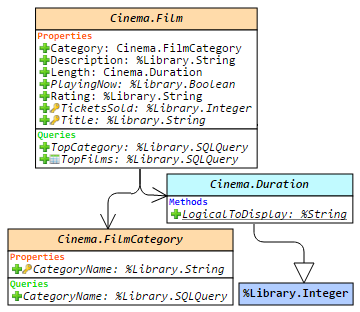 Hello!
Hello!