This tag relates to the discussions on the development of analytics and business intelligence solutions, visualization, KPI and other business metrics management.
I am looking for a reporting tool (Analytics purpose) which can be built using cache object script/MUMPS. Basically my requirement is to find a tool where I can implement cache code to report data for my application.
I am unaware of DeepSee and how it works. Please assist for the same.
I have 3 simple tables: Encounter, Patient and Immunizations. Encounter makes a reference to Patient, and Patient contains a list of Immunization objects.
I've tried using PowerBI to access IRIS (using ODBC connector, not InterSystems BI connector), PowerBI reports the error:
Expression.Error: The column 'Patient' of the table wasn't found.
Details:
Patient
it does this for two of the three tables I need only (Patient and Encounter), but not for Immunization IRIS table..
I am looking for a mapping from SDA collections to the HS Analytics (HSAA) data model. Specifically HS.SDA3.Container.Observations to the tables (Couldn't find all the fields in HSAA.Observation). Can someone help? Thanks
I asked previously about the DR server in the cloud but actually, I'm curious about the backup server to use as analytics server more than for recovery in DR case.
There is a recommended practice to use an async mirror as a server for BI (InterSystems Analytics, DeepSee)
The question is if I have PRIMARY in the cloud (AWS, Google, Azure, etc) "how far" should async mirror member be placed? Same cloud, same private cloud or it doesn't matter at all for analytics purposes?
I am receiving Mirroring updates to an IRIS for Health async reporting server and need to pause the mirroring journal processing to periodically quiesce the database to rebuild cubes and custom staging tables.
What API or web service can I use to quiesce the reporting server and then later initiate catch up?
When we have to predict the value of a categorical (or discrete) outcome we use logistic regression. I believe we use linear regression to also predict the value of an outcome given the input values.
Then, what is the difference between the two methodologies?
Hi, I'm new to the Analytics world in Intersystems and was attempting to print and/or export selected rows from a detail listing in a pivot on a dashboard. I am able to print and/or export all the rows; but if I select a specific set of rows, it prints out the entire detail listing; not the selected rows. Please advise on the best approach to accomplish this task. Thanks.
In DeepSee we have a field that is numeric but is used as a dimension. In DeepSee it sorts this field in the following order. 10, 11, 15, 2, 3, 5, 6, 8, 990. Is there a way to have DeepSee sort it numerically instead of treating it like a character field? We would want to see it show up in the dimension as 2,3,5,6,7,10,11,15,990.
I have a method like this and I want to be able to see the results on the terminal, how do I run this method on a terminal to display the results of this SQL query?
The goal is to get data (from half a thousand to 3-4 thousands lines) from DB, calculate standart deviation then use it as logical condition in analyzer.
For example IF std > custom_value = show_the_result ELSE null
There is a STDDEV(MDX) method used in Analyzer but it is a measure and it can not be used as logical condition (correct me if i am wrong)
I am trying to create a query that returns the best and worst performing products for a given customer, based on this year's net sales versus last year's net sales, weighted by the total net sales for all of the products sold to this customer in the last two years.
I have created Last Year Net Sales (up to the last month end): AGGREGATE(PERIODSTODATE([Invoice Date].[H1].[YEAR],[Invoice Date].[H1].[Month].[NOW-13]),measures.[Net Sales])
I have recently studied deepsee and developed few dashboards needed for our web app users. I am trying to embed them in our existing web app which uses angular with delegated user access. I need to embed the native IRIS dashboard into it. ( I can't use Highcharts or any other js tools).
How do I setup the dashboards to work with delegated authentication (Without providing access to management portal or other parts) ? Also should I use the default csp/{Namespace}/_DeepSee.UserPortal.DashboardViewer.zen? or any other web application URL ?
we are wondering if anybody has a reporting tool that is capable using IRIS Objects?
I know there are things like Crystal Reports and others out there who can read the SQL Data throug ODBC but we need the capability of using object methods while running the report.
Since now we where using a JAVA based report generator (ReportWeaver) but since the object binding for JAVA doesn't exist anymore in IRIS data platform, did any of you have an alternative report generator?
When creating pivots in DeepSee, there is the ability to group date dimensions by Day, Week, Month, Quarter, Year. For some of our reporting the Week option is desired. However the display looks like the image shown below. Notice the "YYYYW##" formatting.
Is there any ability within DeepSee to modify the display of grouped week dates? E.g. instead of 2020W14 it could be 03/30/2020-04/05-2020, or even just the start or end date, etc.
I would like to define an advanced filter within my pivot table that allows me to look at diagnosis codes, or at procedure codes - but I do not want to hard code values within the pivot table definition (get the %OR defined).
I would like to be able to allow my dashboard user to chose what specific diagnosis codes or procedure codes they are interested in. So for example one user may want to look for # of patients with cancer dx or patients who have had a radiation procedure.
How can I accomplish this OR feature using dashboard filters?
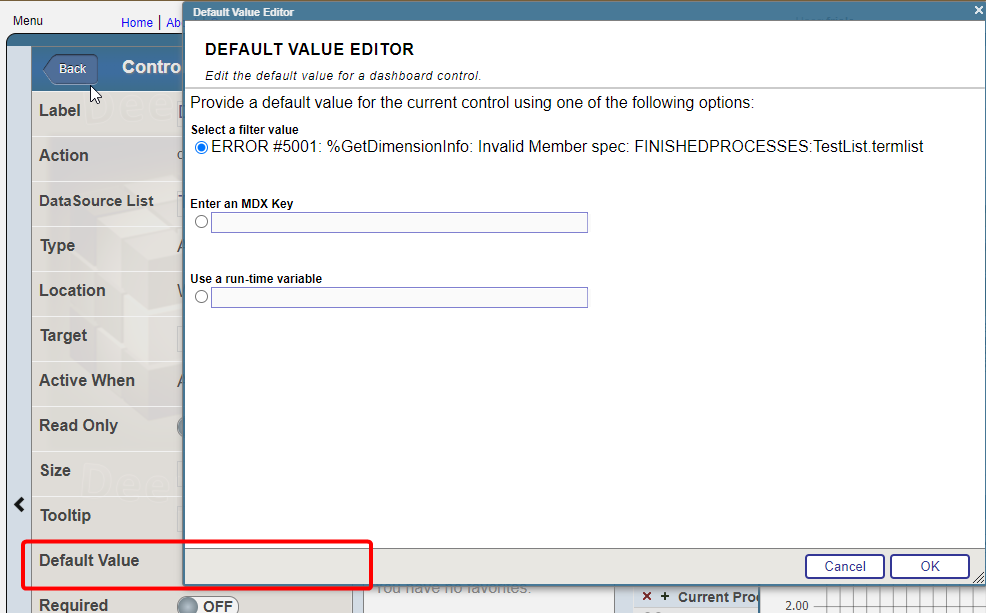
I have a widget that uses "choose Data source" control option. Termlist for the control consist of the two data sources and i want to set one of them by default. For example: I have two data sources, one is grouped by month, the other by year. I need to set the one that is grouped by year by default
Back in my COBOL days, there was a utility that would analyze running COBOL code and expose bottle necks and those modules that were inefficient or were executed multiple times. This was to help the programmer know where to concentrate streamlining efforts.
 By likes
By likes.png)
.png)