#InterSystems Natural Language Processing (NLP, iKnow)
7
InterSystems IRIS Natural Language Processing (NLP), formerly known as iKnow, allows you to perform text analysis on unstructured data sources in a variety of natural languages without any prior knowledge of their content. It does this by applying language-specific rules that identify semantic entities. Because these rules are specific to the language, not the content, NLP can provide insight into the contents of texts without the use of a dictionary or ontology. Learn more.
To achieve optimized AI performance, robust explainability, adaptability, and efficiency in healthcare solutions, InterSystems IRIS serves as the core foundation for a project within the x-rAI multi-agentic framework. This article provides an in-depth look at how InterSystems IRIS empowers the development of a real-time health data analytics platform, enabling advanced analytics and actionable insights. The solution leverages the strengths of InterSystems IRIS, including dynamic SQL, native vector search capabilities, distributed caching (ECP), and FHIR interoperability. This innovative approach directly aligns with the contest themes of "Using Dynamic SQL & Embedded SQL," "GenAI, Vector Search," and "FHIR, EHR," showcasing a practical application of InterSystems IRIS in a critical healthcare context.
As said in the previous article about the iris-fhir-generative-ai experiment, the project logs all events for analysis. Here we are going to discuss two types of analysis covered by analytics embedded in the project:
This is the second article in a series on iKnow demo applications, showcasing how the concepts and context provided through iKnow's unique bottom-up approach can be used to implement relevant use cases and help users be more productive in their daily tasks. Last week's article discussed the Knowledge Portal, a straightforward tool to browse iKnow indexing results.
This week, we'll look into the Set Analysis demo, a slightly more advanced application where you'll be using the concepts identified by iKnow to organize your content into sets of documents. The original version of this demo was developed by Danny Wijnschenk & Alain Houf for an academy session at GS2015, but the app has evolved significantly since then.
The InterSystems DBMS has a built-in technology for working with non-structured data called iKnow and a full-text search technology called iFind. We decided to take a dive into both and make something useful. As the result, we have DocSearch — a web application for searching in InterSystems documentation using iKnow and iFind.
This summer the Database Platforms department here at InterSystems tried out a new approach to our internship program. We hired 10 bright students from some of the top colleges in the US and gave them the autonomy to create their own projects which would show off some of the new features of the InterSystems IRIS Data Platform. The team consisting of Ruchi Asthana, Nathaniel Brennan, and Zhe “Lily” Wang used this opportunity to develop a smart review analysis engine, which they named Lumière. As they explain:
InterSystems' iKnow technology allows you to identify the concepts in natural language texts and the relations that link them together. As that's still a fairly abstract definition, we produced this video to explain what that means in more detail. But when meeting with customers, what really counts is a compelling demonstration, on data that makes sense to them, so they understand the value in identifying these concepts over classic top-down approaches. That's why it's probably worth spending a few articles on some of the demo apps and tools we've built to work with iKnow.
In the first article in this series, we'll start with the Knowledge Portal, a simple query interface to explore the contents of your domain.
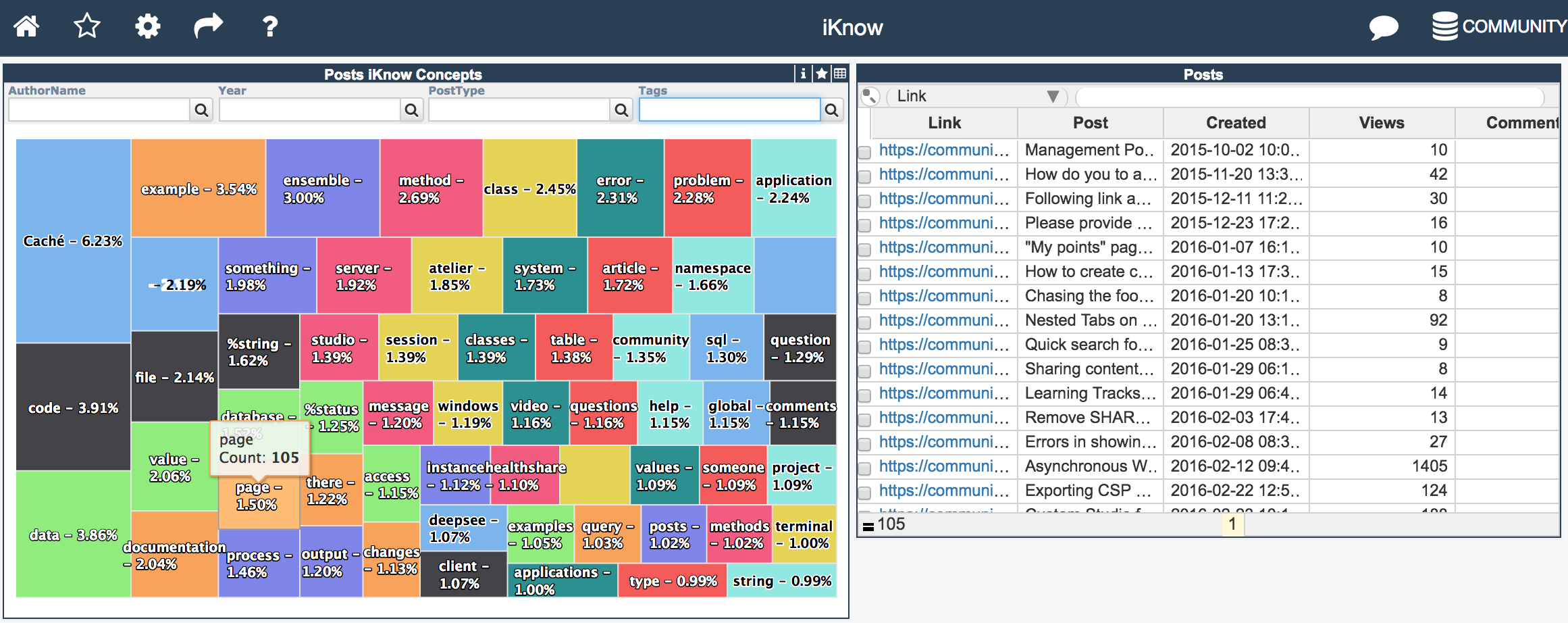
We are playing with InterSystems iKnow analytics against Developer Community posts and introduced the new dashboard, which shows Top 60 concepts for all the posts:
If you've worked with iKnow domain definitions, you know they allow you to easily define multiple data locations iKnow needs to fetch its data from when building a domain. If you've worked with DeepSee cube definitions, you'll know how they tie your cube to a source table and allow you to not just build your cube, but also synchronize it, only updating the facts that actually changed since the last time you built or synced the cube. As iKnow also supports loading from non-table data sources like files, globals and RSS feeds, the same tight synchronization link doesn't come out of the box. In this article, we'll explore two approaches for modelling DeepSee-like synchronization from table data locations using callbacks and other features of the iKnow domain definition infrastructure.
After a five-part series on sample iKnow applications (parts 1, 2, 3, 4, 5), let's turn to a new feature coming up in 2017.1: the iKnow REST APIs, allowing you to develop rich web and mobile applications. Where iKnow's core COS APIs already had 1:1 projections in SQL and SOAP, we're now making them available through a RESTful service as well, in which we're trying to offer more functionality and richer results with fewer buttons and less method calls. This article will take you through the API in detail, explaining the basic principles we used when defining them and exploring the most important ones to get started.
This earlier article already announced the new iKnow REST APIs that are included in the 2017.1 release, but since then we've added extensive documentation for those APIs through the OpenAPI Specification (aka Swagger), which you'll find in the current 2017.1 release candidate. Without wanting to repeat much detail on how the APIs are organised, this article will show you how you can consult that elaborate documentation easily with Swagger-UI, an open source utility that reads OpenAPI specs and uses it to generate a very helpful GUI on top of your API.
This article contains the tutorial document for a Global Summit academy session on Text Categorization and provides a helpful starting point to learn about Text Categorization and how iKnow can help you to implement Text Categorization models. This document was originally prepared by Kerry Kirkham and Max Vershinin and should work based on the sample data provided in the SAMPLES namespace.
A group of students at the Chalmers University of Technology (Gothenburg, Sweden) tried different approaches to automatically rating the quality of emergency calls, including iKnow.
Excerpt: "The most impressive results produced by iKnow is its ability to correctly classify 100% of the calls using the Average algorithm. This is quite surprising since iKnow only compares low-level concepts, how words relates to each other."
In a conference call earlier this week, a customer described how they built an iKnow domain with clinical notes and now wanted to filter the contents of that domain based on the patient's diagnosis codes.
This is the fourth article in a series on iKnow demo applications, showcasing how the concepts and context provided through iKnow's unique bottom-up approach can be used to implement relevant use cases and help users be more productive in their daily tasks. Previous articles discussed the Knowledge Portal, the Set Analysis Demo and the Dictionary Builder Demo, each of which gradually implemented slightly more advanced interactions with what iKnow gleans from unstructured data.
This week, we'll look into one more demo application, the Rules Builder Demo, in which we'll build on previous work but again climb a step on the level ladder, implementing a more high-level use case than in the previous ones. The idea came from an opportunity where we were asked to help the customer in the finance sector make sense of vast volumes of contract data. They wanted to semi-automate the extraction of logical rules from that text (in fluent legalese!), so they could be fed into other systems. While this was an exciting use case to work on (and more on it in this GS2016 presentation), we've also used it in other cases, for example to extract mentions of ejection fraction from Electronic Health Records.
This is the third article in a series on iKnow demo applications, showcasing how the concepts and context provided through iKnow's unique bottom-up approach can be used to implement relevant use cases and help users be more productive in their daily tasks. Previous articles discussed the Knowledge Portal, a straightforward tool to browse iKnow indexing results, and the Set Analysis Demo, in which you can use the output of iKnow indexing to organize your texts according to their content, such as in patient cohort selection.
This week, we'll look into another demo application, the Dictionary Builder demo, in which we'll marry iKnow's bottom-up insights with top-down expertise, organizing our domain knowledge into dictionaries that are composed of the actual terms used in the data itself. Sticking to a top-down approach only, you'd risk missing out on some terminology used in the field that a domain expert sitting in his office wouldn't be aware of.
In previous articles on iKnow, we described a number of demo applications (iKnow demo apps parts 1, 2, 3, 4 & 5) that are either part of the regular kit or can be easily installed from GitHub. All of those applications assumed you already had your iKnow domain ready, with your data of interest loaded and ready for exploration. In this article, we'll shed more light on how exactly you can get to that stage: how you define and then build a domain.
Earlier in this series, we've presented four different demo applications for iKnow, illustrating how its unique bottom-up approach allows users to explore the concepts and context of their unstructured data and then leverage these insights to implement real-world use cases. We started small and simple with core exploration through the Knowledge Portal, then organized our records according to content with the Set Analysis Demo, organized our domain knowledge using the Dictionary Builder Demo and finally build complex rules to extract nontrivial patterns from text with the Rules Builder Demo.
This time, we'll dive into a different area of the iKnow feature set: iFind. Where iKnow's core APIs are all about exploration and leveraging those results programmatically in applications and analytics, iFind is focused specifically on search scenarios in a pure SQL context. We'll be presenting a simple search portal implemented in Zen that showcases iFind's main features.
Sentiment Analysis is a thriving research area in the broader context of big data, with many small as well as large vendors offering solutions extracting sentiment scores from free text. As sentiment is highly dependent on the subject a piece of text is about (financial news vs tweets about the latest computer game), most of these solutions are targeted at specific markets and/or focus on a given type of source data, such as social media content.
Presenter: Danny Wijnschenk Task: Help people make better decisions by letting application deal with all the data. Approach: As an example, we’ll extend a demo asset management application for portfolio and trade compliance, using iKnow technology to translate agreements into rules that ensure portfolio compliance prior to trade execution.
In this session, we’ll discuss how easy it is to extend a classic application that deals with straightforward transactions, to also offer insights and actions based on more complex, unstructured data. We’ll present a use case on portfolio compliance from the financial services industry.
Content related to this session, including slides, video and additional learning content can be found here.
Presenter: Benjamin De Boe Task: Extract specialized information from your unstructured data Approach: Combine InterSystems iKnow technology with third-party and custom text-processing tools
This session explains how you can easily combine ISC, third-party and custom text processing tools to get the broadest insights in your unstructured data.
Content related to this session, including slides, video and additional learning content can be found here.
Presenter: Dirk Van Hyfte Task: Leverage unstructured data to improve how clinicians deliver care Approach: Give real-world examples of organizations that are benefiting from using their unstructured data
This session will feature real-world examples of how healthcare organizations can benefit from exposing unstructured data to clinicians at point-of-care as well as to clinical informatics building predictive models. Presenters are Wesley Williams, PhD, Vice President and Chief Information Officer, Mental Health Center of Denver; Augie Turano PhD. IT Director Veterans Informatics and Computer Infrastructure (VINCI); and Dirk Van Hyfte, MD, PhD, Senior Research Consultant.
Content related to this session, including slides, video and additional learning content can be found here.
Presenter: Misha Bouzinier Task: Gain an understanding of natural language processing and the current state of the art Approach: Discuss how InterSystems iKnow technology fits into the NLP ecosystem and complements the output of other components such as Lucene and Stanford NLP tools
A 101 session on Natural Language Processing that positions Intersystems tools in the broader ecosystem Problem: we’ve been touting “unstructured data” for five years, but many people both internally and externally still don’t know what it means to “process natural language” in general and how iKnow and our upcoming UIMA capabilities fit in this NLP ecosystem. This session will describe what a number of common technologies offer and how bare-bone NLP output typically needs to be complemented with more classic analytics or inference tooling to get the value out.
Content related to this session, including slides, video and additional learning content can be found here.
A simple and rather automated search portal leveraging iFind capabilities for rich text search in 2016.1. It has simple faceting, result ranking, highlighting of search results etc and just works off any table you point it to that has an iFind index by appending ?t=MyPackage.TableName to the URL.
Big Data for Enriching Analytical Capabilities - Big data is revolutionizing the world of business intelligence and analytics. Gartner predicts that big data will drive $232 billion in spending through 2016, Wikibon claims that by 2017 big data revenue will have grown to $47.8 billion, and McKinsey Global Institute indicates that big data has the potential to increase the value of the US health care industry by $300 billion and to increase the industry value of Europe's public sector administration by Ä250 billion.
Experts estimate that 85% of all data exists in unstructured formats – held in e-mails, documents (contracts, memos, clinical notes, legal briefs), social media feeds, etc. Where structured data typically accounts for quantitative facts, the more interesting and potentially more valuable expert opinions and conclusions are often hidden in these unstructured formats. And with massive volumes of text being generated at unprecedented speed, there’s very little chance this information can be made useful without some process of synthesis or automation.
 By update
By update Open Exchange app
Open Exchange app