By views
By viewsMirroring 101
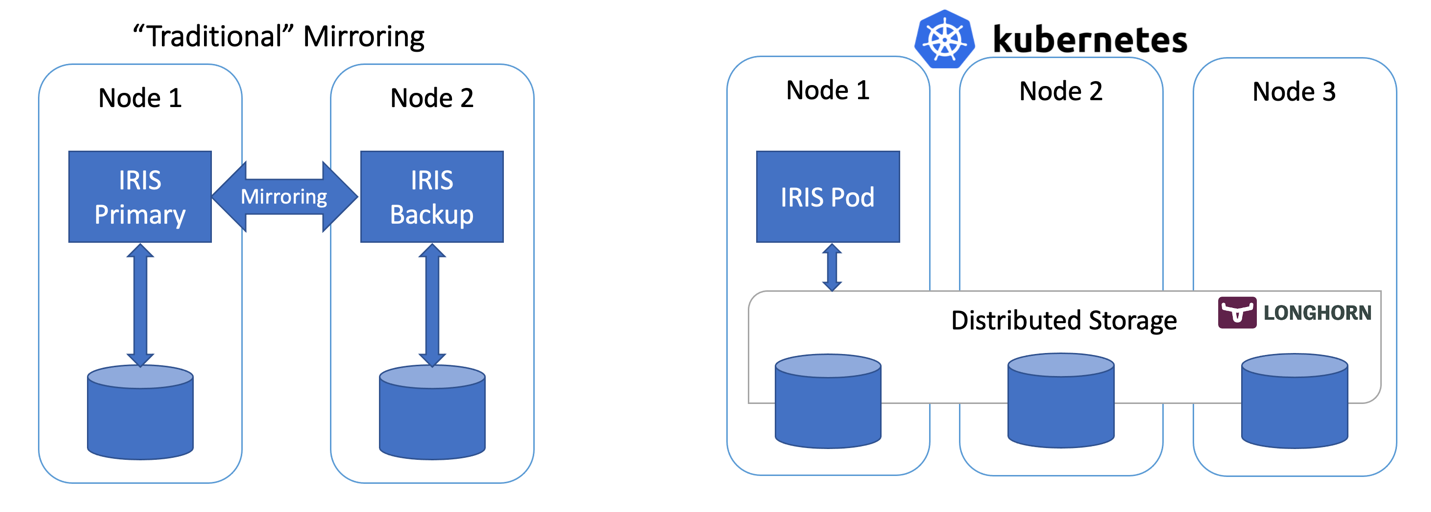
Caché mirroring is a reliable, inexpensive, and easy to implement high availability and disaster recovery solution for Caché and Ensemble-based applications. Mirroring provides automatic failover under a broad range of planned and unplanned outage scenarios, with application recovery time typically limited to seconds. Logical data replication eliminates storage as a single point of failure and a source of data corruption. Upgrades can be executed with little or no downtime.
 Open Exchange app
Open Exchange app