 By update
By updatet's also an example for a customized command extension (ZZJSON) in IRIS
IRIS has a nice %JSON.Formatter class.
But for debugging it is not really handy.
see:
ZWRITE js1
js1="{""Name"":""Cunningham,John C."",""SSN"":""294-11-9150"",""DOB"":""1933-01-08"",""Home"":{""Street"":""4249 Ash Street"",""City"":""Tampa"",""State"":""MD"",""Zip"":""30176""},""FavoriteColors"":\[""White"",""Red"",""Green""]}"
so you proceed for the most simple case
 Open Exchange app
Open Exchange app
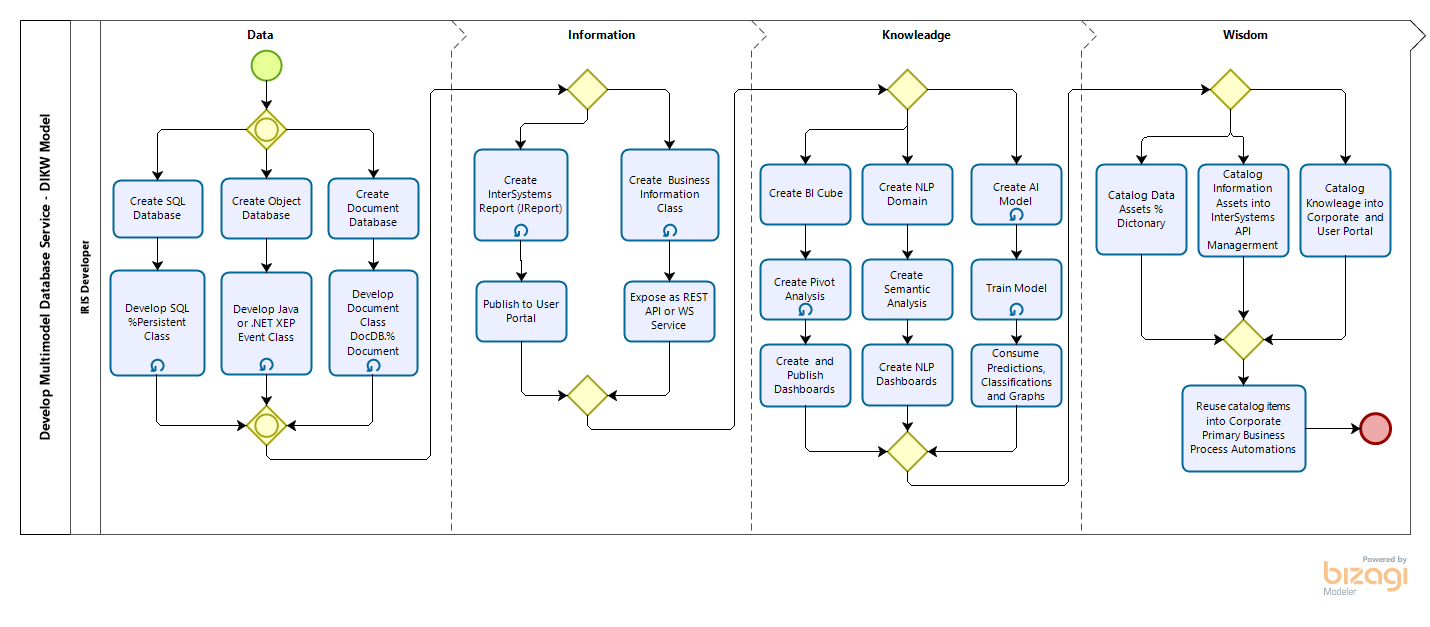
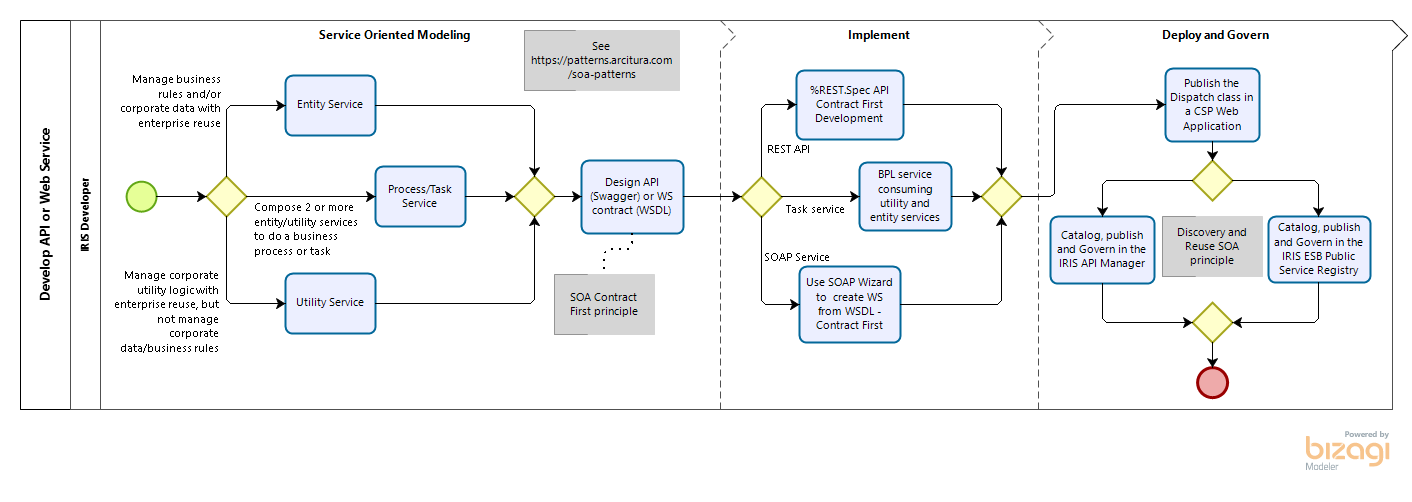
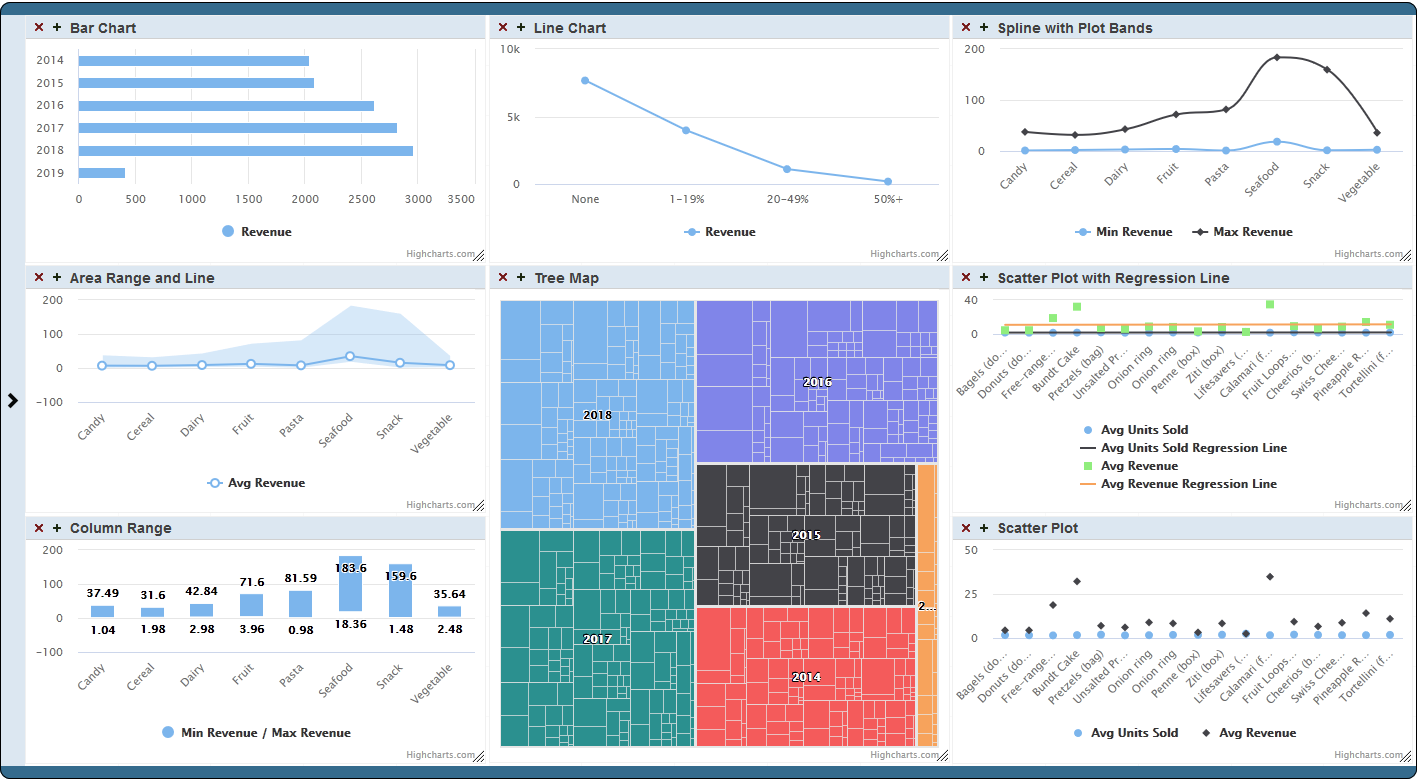
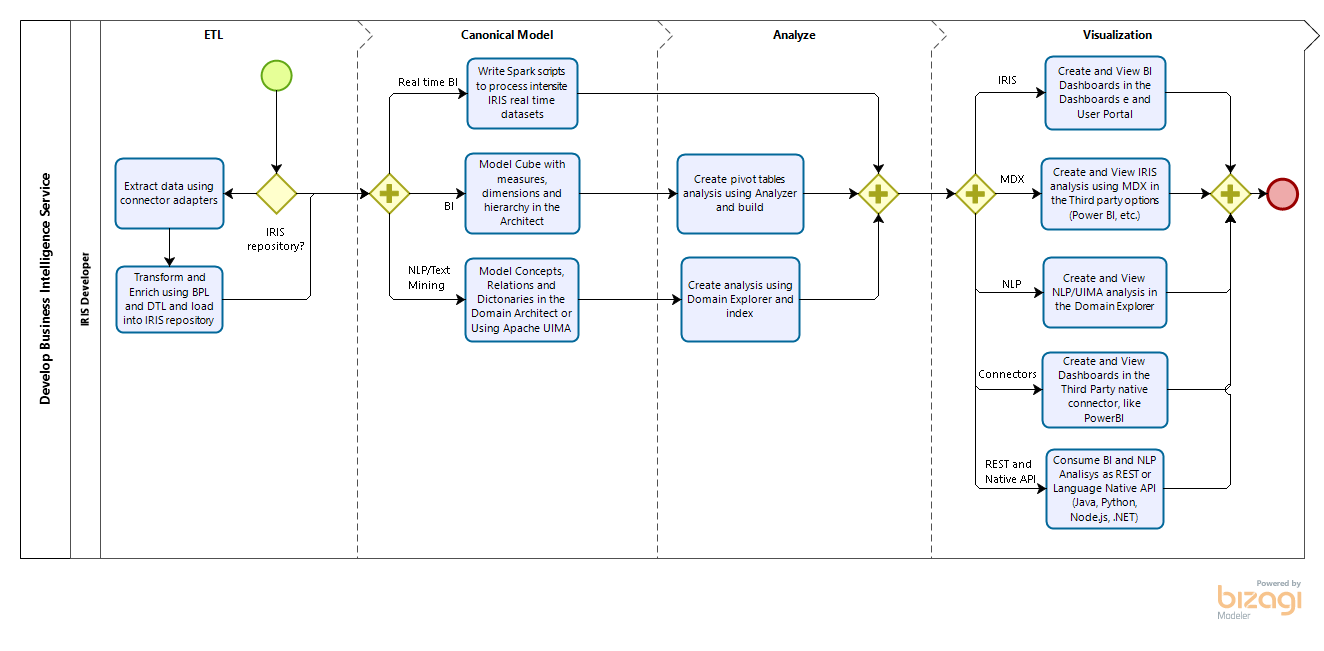
.png)
.png)