Vector search is a retrieval method that converts text, images, audio, and other data into numeric vectors using an AI model, and then searches for items that are semantically close. It enables “semantic similarity search” from free text, which is difficult with keyword search alone.
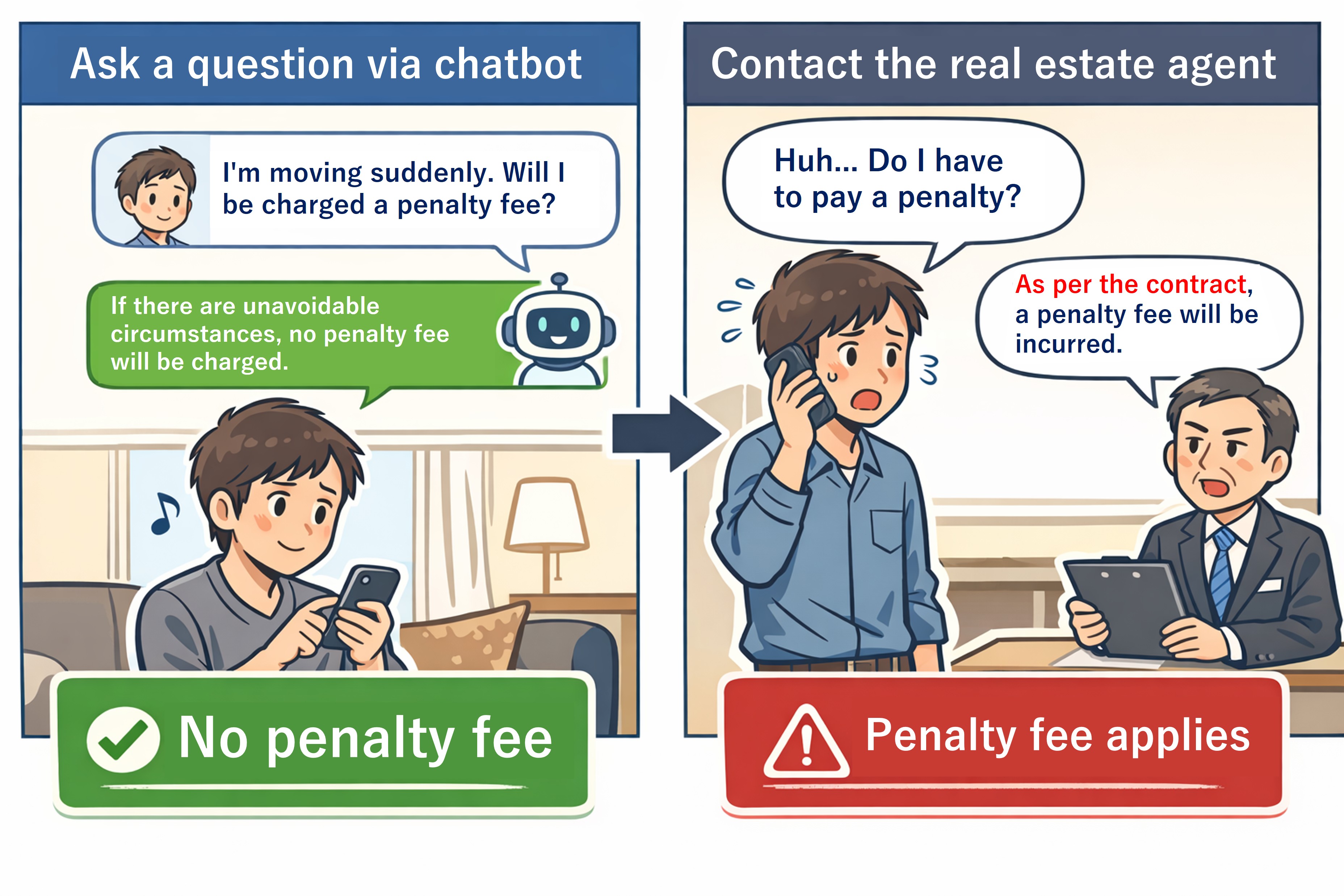
However, in real use, I encountered cases where results that are “close in meaning” but logically the opposite appeared near the top of the search results.
This is a serious issue in situations where affirmation vs. negation matters. If the system returns the wrong answer, the impact can be significant, so we cannot ignore this problem.
This article does not propose a new algorithm. I wrote it to share a practical way I found useful when semantic search fails due to negation.