InterSystems IRIS is built on an architecture that separates the logical organization of data (namespaces) from its physical storage location (databases). Understanding this separation and the distinction between Namespaces and Databases is crucial for effective data management, security, and especially, high-performance data sharing.
In this article, I will discuss these foundational components and provide a practical guide on leveraging global mappings to share native data structures (globals) across different logical environments.
Databases: Physical Reality
A database represents the physical reality of where the data is stored on the disk. First and foremost, it’s a file in a file system called IRIS.dat (e.g., <Install folder>\mgr\user\IRIS.DAT). The maximum size of this file is 32TB. It is the container for all the actual data and the code. Databases are managed by the IRIS kernel, which handles caching, journaling, and transaction logging at the physical file level.
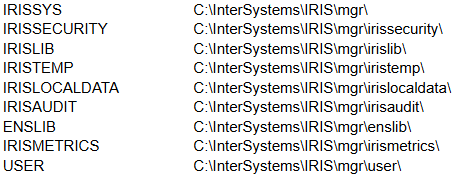
When you install InterSystems IRIS DBMS, the following databases are installed automatically:
.png)

.png)

(2).png)
