New
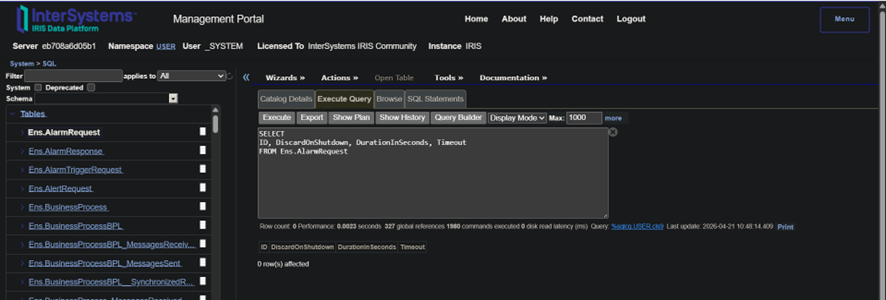
The Management Portal doesn't have a native way to switch to Dark Mode. This can be resolved using a Chrome extension called Dark Reader. See the result:
To install and use the Dark Reader:
The Management Portal doesn't have a native way to switch to Dark Mode. This can be resolved using a Chrome extension called Dark Reader. See the result:
To install and use the Dark Reader:
A microservice is an architectural style that structures an application as a collection of small, autonomous services. Each component is developed around a specific business capability, can be deployed independently, and is typically managed by a miniature, specialized, self-governing team. (Source: https://microservices.io/)
The PACELC theorem was created by Daniel Abadi (University of Maryland, College Park) in 2010 as an extension of the CAP theorem (created by Eric Brewer - Consistency, Availability, and Partition Tolerance). Both help design how to architect the most suitable operation of data platforms in distributed environments under the aspects of consistency versus availability. The difference is that PACELC also allows analysis of the best option for non-distributed environments, making it the gold standard for considering all possible scenarios to define your deployment topology and architecture.
The CAP theorem states that in distributed systems, it is not possible to have consistency, availability, and partition tolerance simultaneously, requiring a choice of two out of three, according to the following diagram.
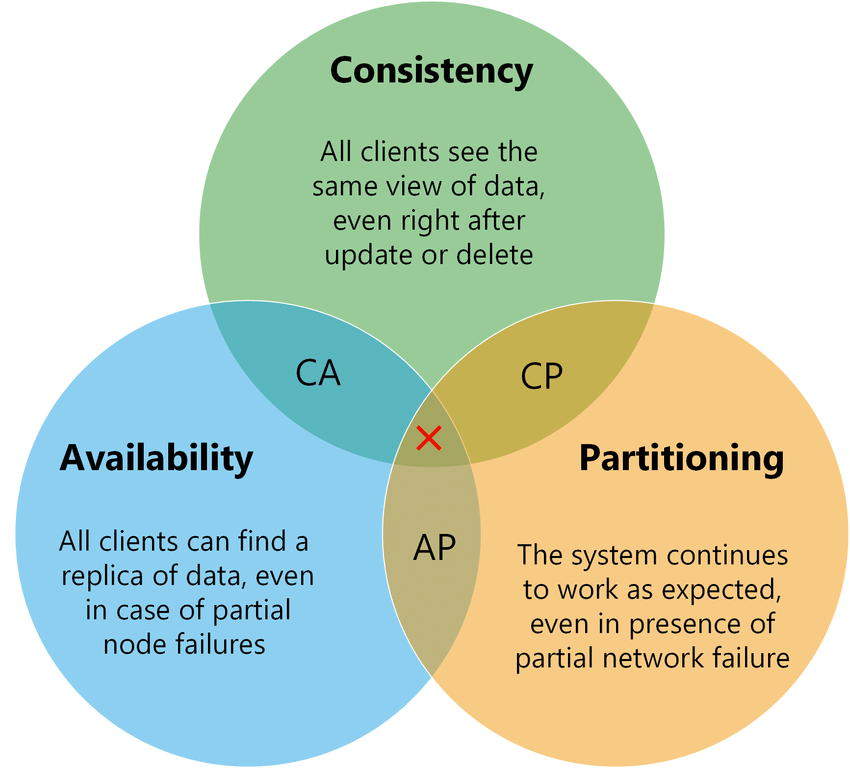
Source: https://medium.com/nerd-for-tech/understand-cap-theorem-751f0672890e
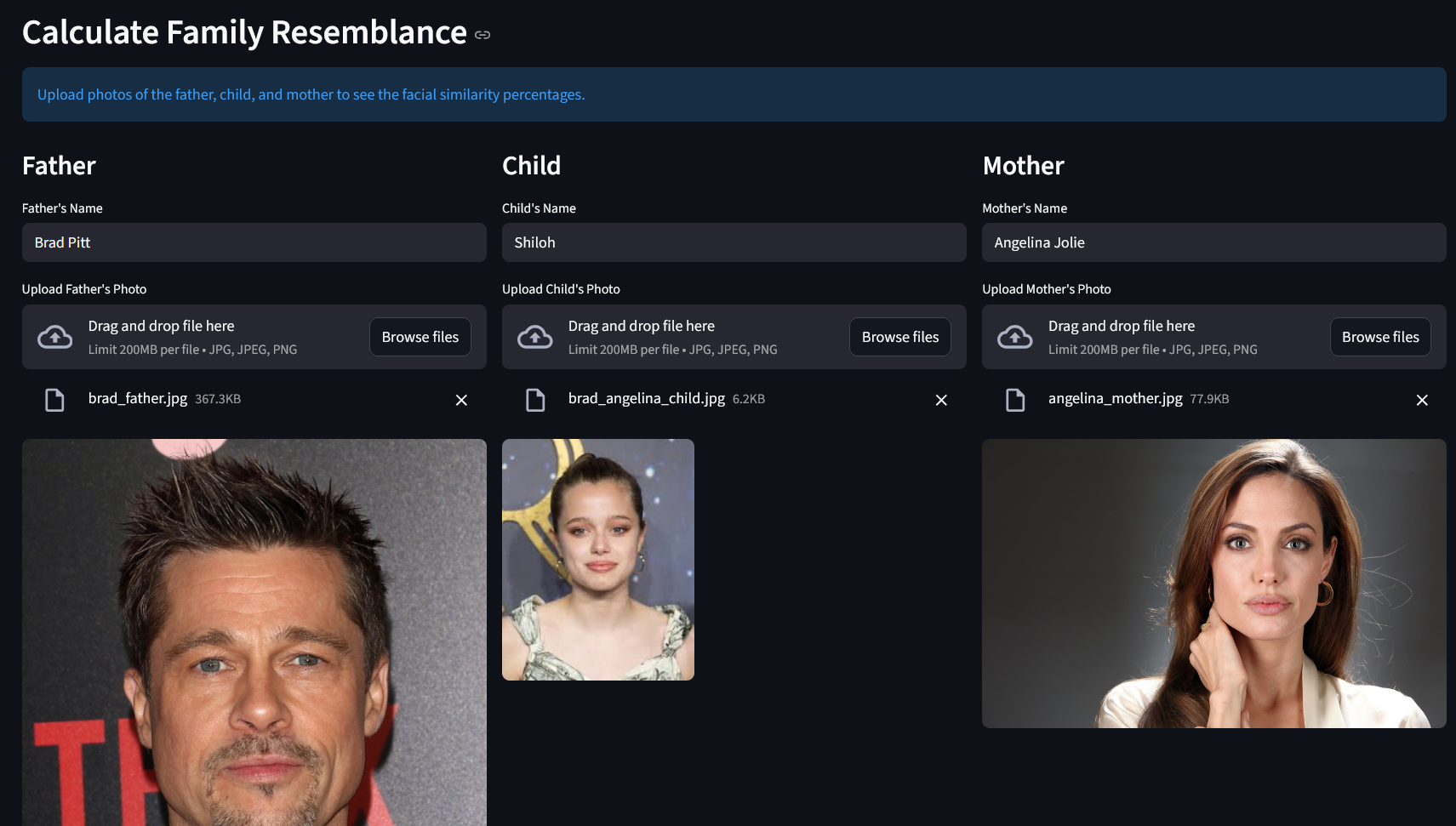
There are always those who say that their child looks more like their mother or their father. How about using math and Artificial Intelligence to be sure? The facial-matching application can answer you.
See these results:
The facial recognition has become the most popular method for validating people's identities, thus enabling access to systems, confirmation of personal and documentary data, and approval of actions and documents.
The challenges are related to performance when the database is very large, accuracy, and especially the privacy of biometric facial data. For these challenges, nothing is better than using InterSystems Vector Search, as it allows:
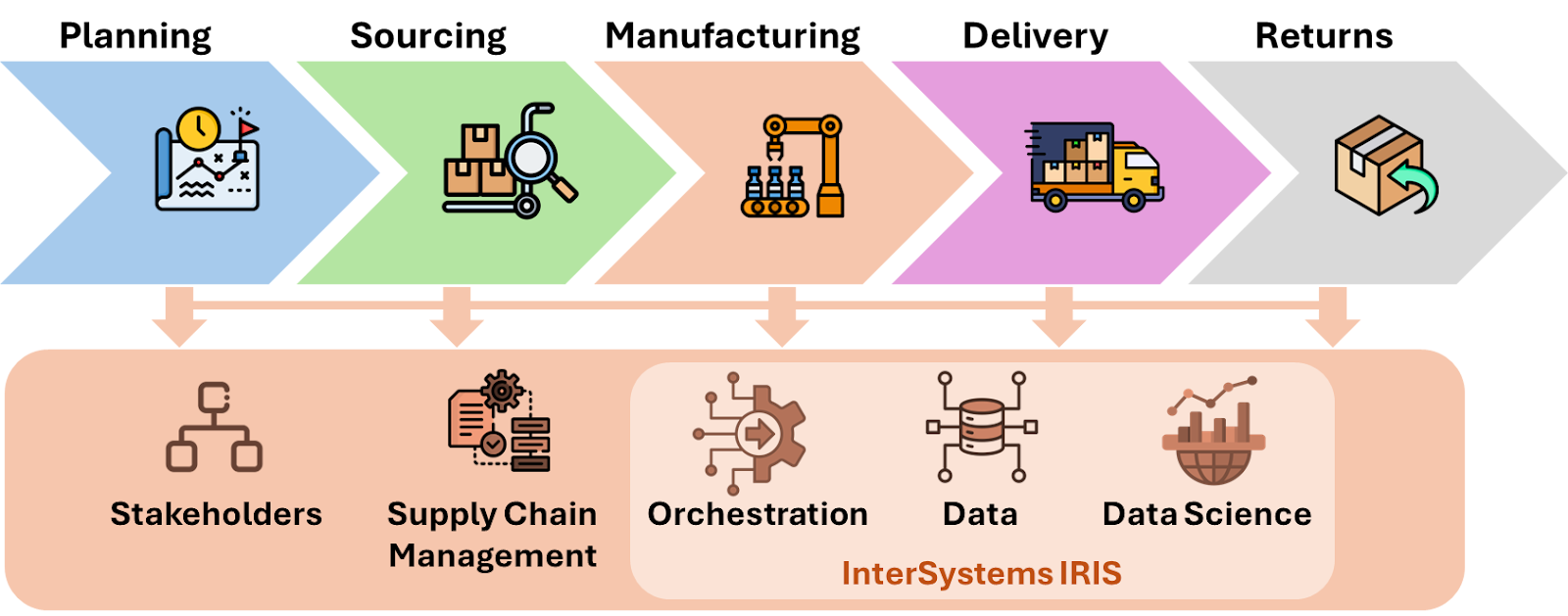
Supply Chain refers to a set of processes and activities performed by the company's business areas and its suppliers and partners (stakeholders), from the acquisition of raw materials, through production, to delivery to the end consumer. It can be better managed using SCM solutions with the orchestration of the InterSystems IRIS:
The Load Data utility it is an excellent tool to load data from CSV/TXT files into an IRIS SQL Table, but it is required send the target file to the IRIS server and write the Load Data sentence to ingest the file content. Now it is possible select a file in VSCode, set the table destination and submit the request. The vscode-load-data utility will send the file to the IRIS server and run the Load Data command to you! Very simple:
.png)
Modern data architectures utilize real-time data capture, transformation, movement, and loading solutions to build data lakes, analytical warehouses, and big data repositories. It enables the analysis of data from various sources without impacting the operations that use them. To achieve this, establishing a continuous, scalable, elastic, and robust data flow is essential. The most prevalent method for that is through the CDC (Change Data Capture) technique. CDC monitors for small data set production, automatically captures this data, and delivers it to one or more recipients, including analytical data repositories. The major benefit is the elimination of the D+1 delay in analysis, as data is detected at the source as soon as it is produced, and later is replicated to the destination.
This article will demonstrate the two most common data sources for CDC scenarios, both as a source and a destination. For the data source (origin), we will explore the CDC in SQL databases and CSV files. For the data destination, we will use a columnar database (a typical high-performance analytical database scenario) and a Kafka topic (a standard approach for streaming data to the cloud and/or to multiple real-time data consumers).
This article will provide a sample for the following interoperability scenario:

This anthropic article made me think of several InterSystems presentations and articles on the topic of data quality for AI applications. InterSystems is right that data quality is crucial for AI, but I imagined there would be room for small errors, but this study suggests otherwise. That small errors can lead to big hallucinations. What do you think of this? And how can InterSystems technology help?
The ObjectScript language has incredible JSON support through classes like %DynamicObject and %JSON.Adaptor. This support is due to the JSON format's immense popularity over the previous dominance of XML. JSON brought less verbosity to data representation and increased readability for humans who needed to interpret JSON content. To further reduce verbosity and increase readability, the YAML format was created. The very easy-to-read YAML format quickly became the most popular format for representing configurations and parameterizations, due to its readability and minimal verbosity.
This article outlines the process of utilizing the renowned Jaeger solution for tracing InterSystems IRIS applications. Jaeger is an open-source product for tracking and identifying issues, especially in distributed and microservices environments. This tracing backend that emerged at Uber in 2015 was inspired by Google's Dapper and Twitter's OpenZipkin. It later joined the Cloud Native Computing Foundation (CNCF) as an incubating project in 2017, achieving graduated status in 2019. This guide will demonstrate how to operate the containerized Jaeger solution integrated with IRIS.
Sometimes your client may request documentation of your BI or interoperability project in a formal document. In this case, MS Word is a good alternative, as it has an advanced editor that allows you to generate professional documentation. Now it's possible!
The iris4word app has this functionality!
| Final MS Word Document | Word Template |
.png) |
.png) |
.png) |
.png) |
the iris4word get BI asset list and metadata using the InterSystems IRIS BI REST API documented on (https://docs.intersystems.com/healthconnectlatest/csp/docbook/DocBook.UI.Page.cls?KEY=D2CLIENT_rest_api).
Word documents are widely used in the market. Users frequently create contracts, memos, resumes, reports, analyses, and other documents that may require data from or captured by InterSystems IRIS. However, IRIS does not have an API, SDK, library, or adapter for this. This limitation no longer exists.
The new Open Exchange library iris4word (https://openexchange.intersystems.com/package/iris4word) delivers an ObjectScript SDK where the developer passes any %DynamicObject as a parameter, a Word file template and then receives a ready document, with the structure and formatting defined in its template.
.png)
Any plans for ODBC 3.8 support?
Template engines are essential for producing customizable dynamic content, without the need for compilation and opening up great possibilities of extensibility for the template user. Especially if the template engine supports Python. A popular solution for template engine is Mko. It is is a template library written in Python. It provides a familiar, non-XML syntax which compiles into Python modules for maximum performance. Mako's syntax and API borrows from the best ideas of many others, including Django and Jinja2 templates, Cheetah, Myghty, and Genshi.
Google Forms is the most popular solution on the market for collecting data, answering questionnaires and quizzes. So, it is the ideal solution for collecting patient data and responses in a practical way, without the need to expand or develop systems. In this article, I will detail how to create an account on Google Cloud, register the application that will consume the Google Forms API, generate the service user necessary to consume the API and finally perform actions to create new forms and collect data filled in them in an automated way in embedded Python and IRIS.
What is the global ^Ens.AppData and is it secure kill it? These global is consuming many storage and need increase free space
RabbitMQ is a message broker that allows producers (those who send a data message) and consumers (those who receive a data message) to establish asynchronous, real-time, and high-performance massive data flows. RabbitMQ supports AMQP (Advanced Message Queuing Protocol), an open standard application layer protocol.
The main reasons to employ RabbitMQ include the following:
This year I will go to the READY 2025 event (https://community.intersystems.com/post/registration-open-intersystems-ready-2025). See my plans:
60% of my topics are covered by developer sessions and the other 40% I will reach using 1:1 meetings, tech exchange and focus groups. I know, it is not possible stay at all sessions, but I will to try 30-40% of sessions.
The "Ask Developer Community AI" tool is an excellent resource for studying for the certification. I asked it about each topic that will be covered in the test and the results are below.
Note: I classified each answer by the assertiveness that I consider as good, average and bad.
Note 2: The article has 4 parts, each one for an exam area.
The "Ask Developer Community AI" tool is an excellent resource for studying for the certification. I asked it about each topic that will be covered in the test and the results are below.
Note: I classified each answer by the assertiveness that I consider as good, average and bad.
Note 2: The article has 4 parts, each one for an exam area.
The "Ask Developer Community AI" tool is an excellent resource for studying for the certification. I asked it about each topic that will be covered in the test and the results are below.
Note: I classified each answer by the assertiveness that I consider as good, average and bad.
Note 2: The article has 4 parts, each one for an exam area.
The "Ask Developer Community AI" tool is an excellent resource for studying for the certification. I asked it about each topic that will be covered in the test and the results are below.
Note: I classified each answer by the assertiveness that I consider as good, average and bad.
Note 2: The article has 4 parts, each one for an exam area.
See the Langchain IRIS Tool in action on YouTube. You can see IRIS metrics, discover classes, generate fake data, and so on. Project using Ollama, IRIS VectorDB, Streamlit and Langchain.
If you want to know if a class about a topic already exists asking a simple natural language question, it is possible now. Download and run the application https://openexchange.intersystems.com/package/langchain-iris-tool to know all about your project classes in a Chat.
Now it is possible ask your IRIS server using an AI Chat or compose other agent applications to get:
To do it, get and install the new package langchain-iris-tool (https://openexchange.
The FHIR standard establishes a powerful but flexible data model that can smoothly adapt to the complexities of operational healthcare data management. This flexibility comes at the cost of a data model with many tables and relationships, even for simple data such as the patient's record of telephone numbers, addresses, and emails. It would easily require querying 4 different tables. However, FHIR SQL Builder eliminates this problem, allowing you to create visual projections (mappings) in web wizards.
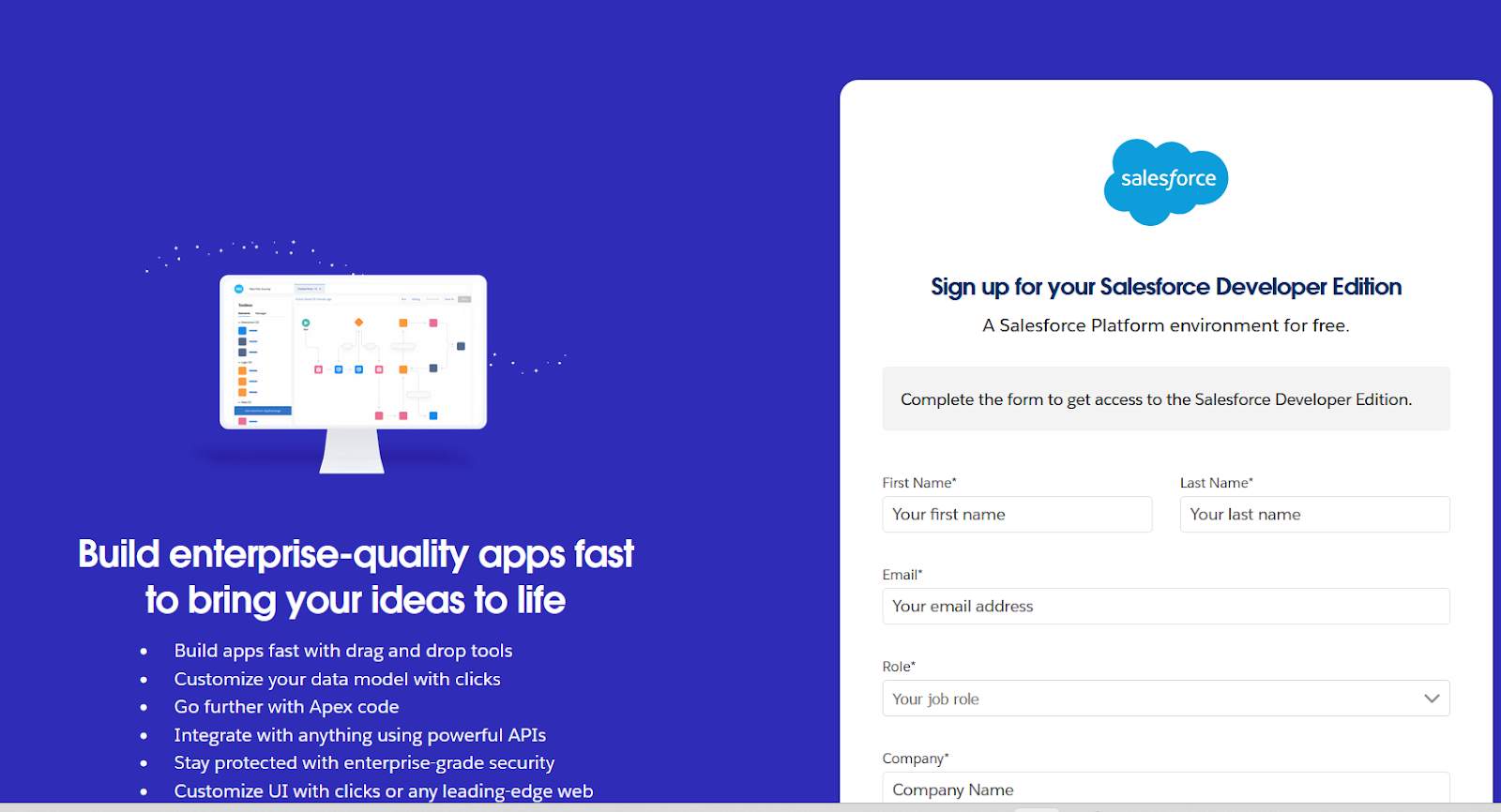
In 2023, according to IDC, Salesforce's market share in CRM reached 21.7%. This company owns a substantial amount of critical corporate business processes and data, so the InterSystems IRIS must have an interoperability connector to fetch data from the Salesforce data catalog. This article will show you how to get any data hosted by Salesforce and create an interoperation production to get data and send it to such targets as files and relational databases.
1. Go to https://developer.salesforce.com/signup: