 By update
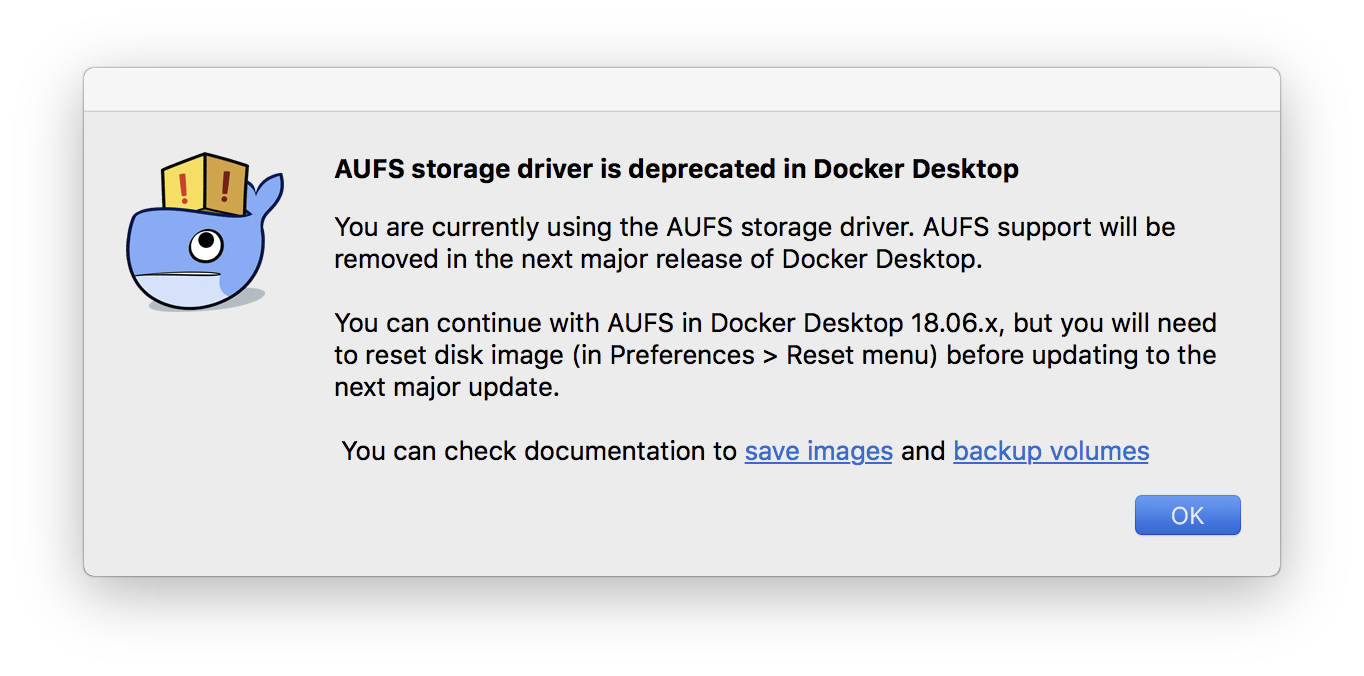
By updateJust got the new beta version of Docker, with depreciation warning of AUFS. It's so bad news when InterSystems does not support used by default storage driver overlay2. Recently I thought to play with Google Kubernetes Engine, and realized that I can't work with InterSystems products there due to incompatibility with Storage Driver. Maybe it's already time to think about support?

I was understanding the cluster configuration supported by the Cache. Have couple of queries around that:
1. In Cache version 2018.2, there is a shrading concept which splits the data of a Master Data server into multiple small data server which store shraded data.