 By update
By updateIn this article, we’ll build a highly available IRIS configuration using Kubernetes Deployments with distributed persistent storage instead of the “traditional” IRIS mirror pair. This deployment would be able to tolerate infrastructure-related failures, such as node, storage and Availability Zone failures. The described approach greatly reduces the complexity of the deployment at the expense of slightly extended RTO.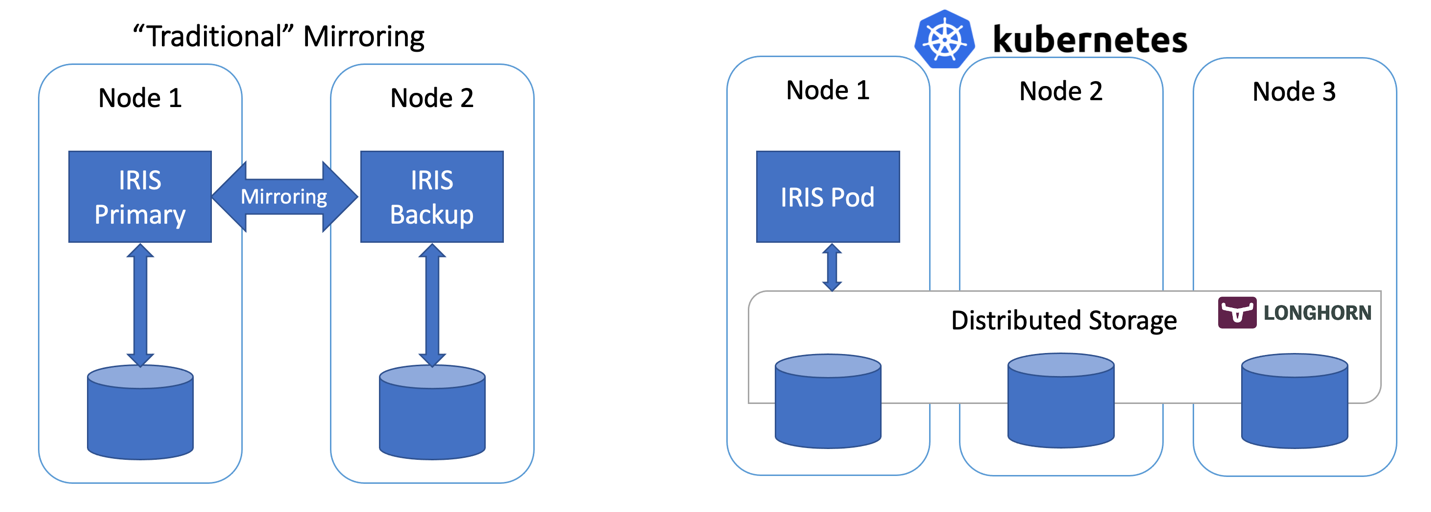
 Open Exchange app
Open Exchange app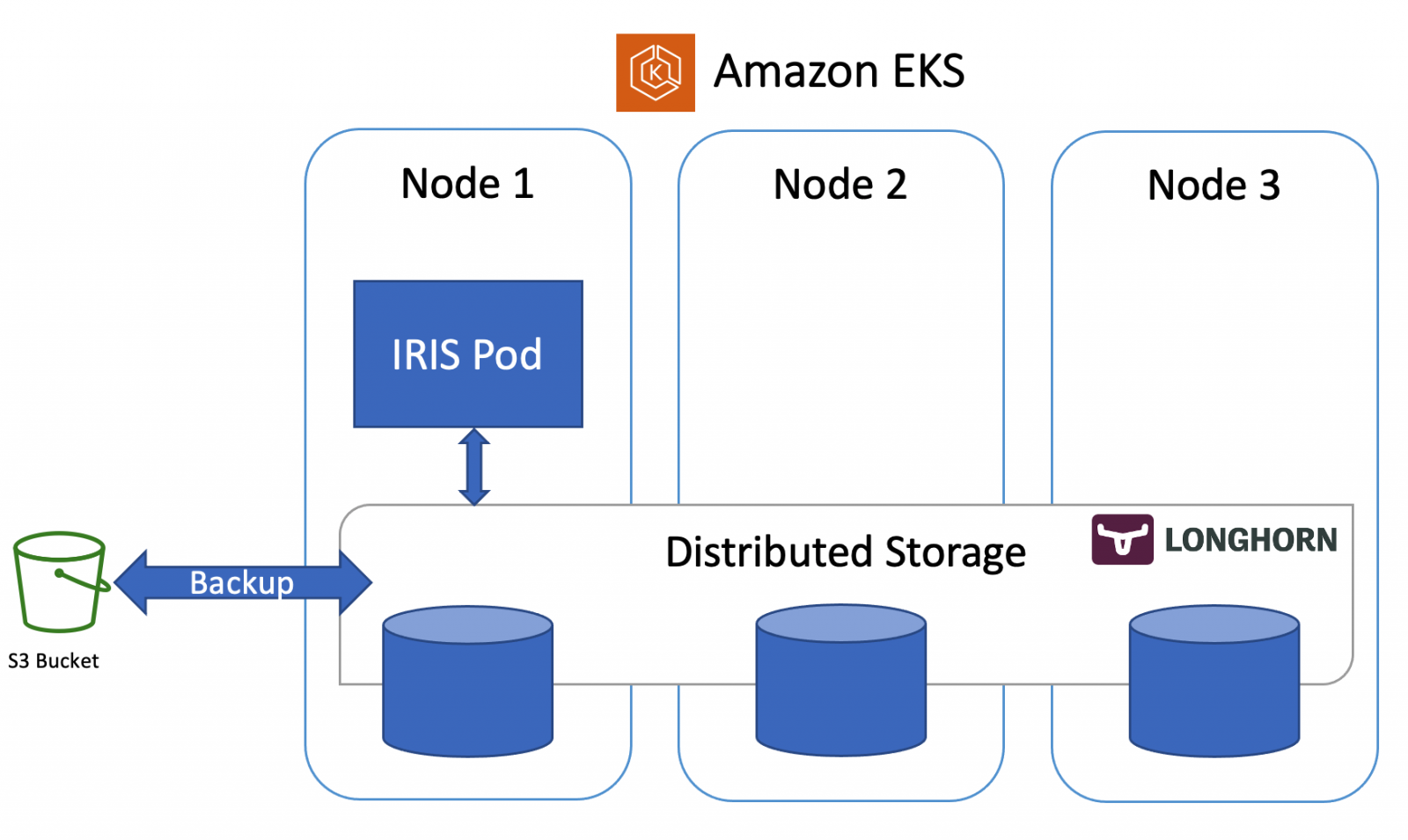


I was understanding the cluster configuration supported by the Cache. Have couple of queries around that:
1. In Cache version 2018.2, there is a shrading concept which splits the data of a Master Data server into multiple small data server which store shraded data.