By likes
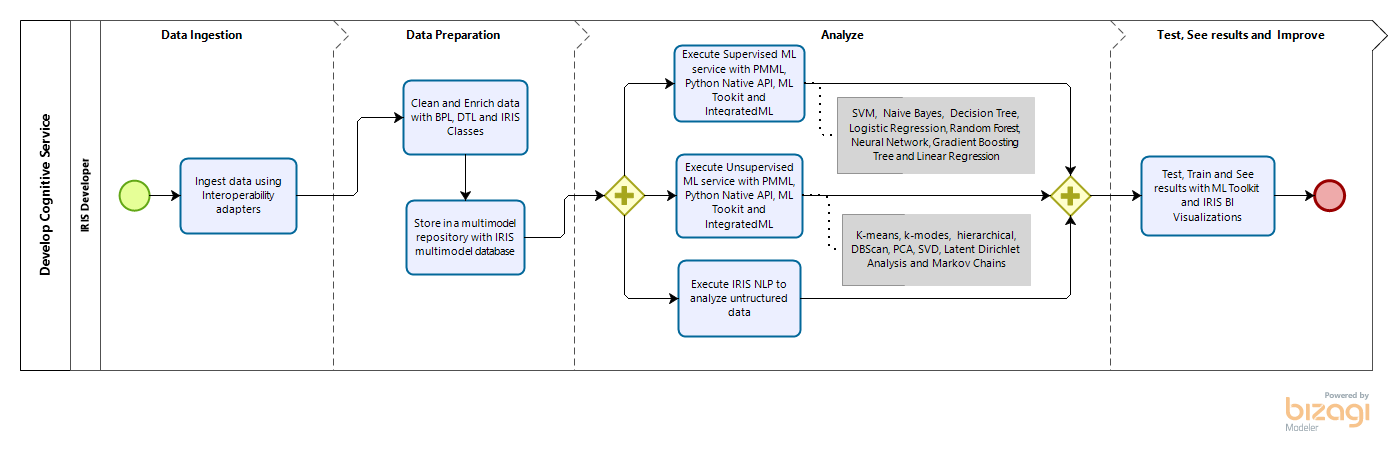
By likesCurrently, the process of using machine learning is difficult and requires excessive consumption of data scientist services. AutoML technology was created to assist organizations in reducing this complexity and the dependence on specialized ML personnel.
AutoML allows the user to point to a data set, select the subject of interest (feature) and set the variables that affect the subject (labels). From there, the user informs the model name and then creates his predictive or data classification model based on machine learning.
 Open Exchange app
Open Exchange app.png)
.png)
.png)