DeDupe an InterSystems® FHIR® Server With FHIR SQL Builder and Zingg
|
This post backs the demonstration at Global Summit 2023 "Demos and Drinks" with details most likely lost in the noise of the event. This is a demonstration on how to use the FHIR SQL Capabilities of InterSystems FHIR Server along side the Super Awesome Identity and Resolution Solution, Zingg.ai to detect duplicate records in your FHIR repository, and the basic idea behind remediation of those resources with the under construction PID^TOO|| currently enrolled in the InterSystems Incubator program. If you are into the "Compostable CDP" movement and want to master your FHIR Repository in place you may be in the right spot.
|
 |
Let's get on with it as they say...
FHIR SQL
We were awarded a full trial of the Health Connect Cloud suite for the duration of the incubator, included in that was the FHIR Server with FHIR SQL Enabled.
 The FHIR SQL Builder (abbreviated “builder”) is a sophisticated projection tool to help developers create custom SQL schemas using data in their FHIR (Fast Healthcare Interoperability Resources) repository without moving the data to a separate SQL repository. The objective of the builder is to enable data analysts and business intelligence developers to work with FHIR using familiar analytic tools, such as ANSI SQL, Power BI, or Tableau, without having to learn a new query syntax.
The FHIR SQL Builder (abbreviated “builder”) is a sophisticated projection tool to help developers create custom SQL schemas using data in their FHIR (Fast Healthcare Interoperability Resources) repository without moving the data to a separate SQL repository. The objective of the builder is to enable data analysts and business intelligence developers to work with FHIR using familiar analytic tools, such as ANSI SQL, Power BI, or Tableau, without having to learn a new query syntax.
I know right? Super great, now our "builder" is going to go to work projecting the fields weed need to identify the duplicate the records with Zingg.
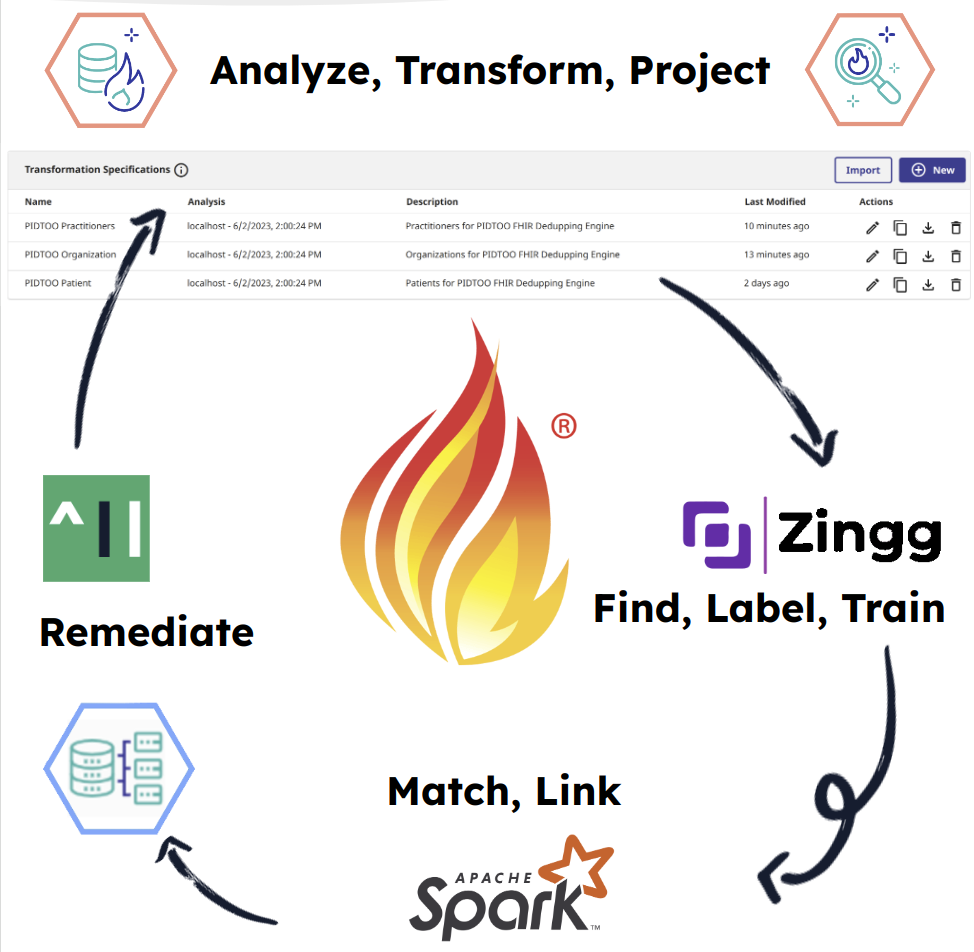
First step is the analysis, which you can hardly go wrong clicking this one into submission, simply point the analysis to "localhost" which is essentially the InterSystems FHIR Server underneath.
 The transforms are the critical piece to get right, you need to build these fields out to flatten the FHIR resources so they can be read to make some decisions over the SQL super server. These most likely will need some thought as the more fields you transform to sql, the better your machine learning model will end up when prospecting for duplicates.
The transforms are the critical piece to get right, you need to build these fields out to flatten the FHIR resources so they can be read to make some decisions over the SQL super server. These most likely will need some thought as the more fields you transform to sql, the better your machine learning model will end up when prospecting for duplicates.
 Now, a data steward type should typically be building these, but I whooped up a few for the demo with questionable simplicity, this was done by using the "clown suit" by hitting the pencil to generate them, but considering the sophistication that may go into them, you can import and export them as well. Pay special attention to the "Package" and "Name" as this will be the source table for your sql connection.
Now, a data steward type should typically be building these, but I whooped up a few for the demo with questionable simplicity, this was done by using the "clown suit" by hitting the pencil to generate them, but considering the sophistication that may go into them, you can import and export them as well. Pay special attention to the "Package" and "Name" as this will be the source table for your sql connection.
 This transform is essentially saying we want to use name and gender to detect duplicates.
This transform is essentially saying we want to use name and gender to detect duplicates.
Patient Transform example
Now, the last part is essentially scheduling the job to project the data to a target schema. I think you will be presently surprised that as data is added to the FHIR Server, the projections fill automatically, phew.

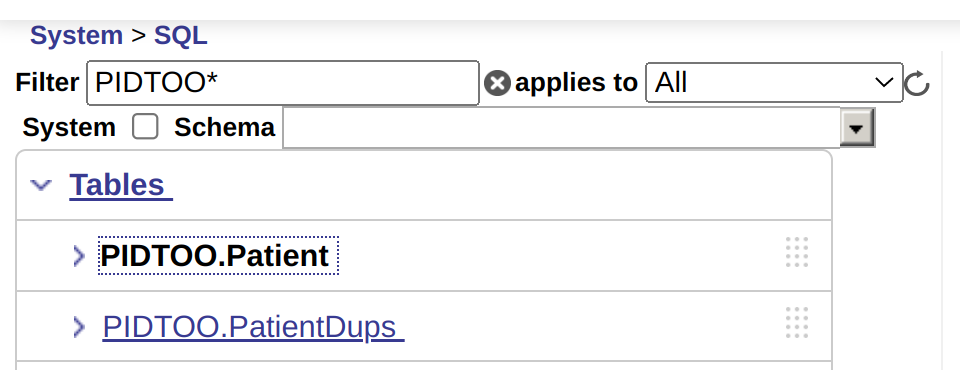
| Now to seal the deal with the setup of FHIR SQL, you can see the projection for Patient (PIDTOO.Patient) being visible, then you create another table to store the output from the dedupe run (PIDTOO.PatientDups). |
|
Another step you will need to complete is enabling the Firewall so that external connections are enabled for your deployment, and you have allowed access for the source CIDR block connecting to the super server.

Mentally bookmark the overview page, as it has the connectivity information and credentials needed to connect before moving to the next step.


DeDupe with Zingg
Zingg is super powerful, OSS, runs on Spark and scales to your wallet when it comes to de-duplication of datasets large and small. I don't want to oversimplify the task, but the reality is the documentation, functional container are enough to get up and running very quickly. We will keep this to the brass tacks though to minimally point out what needs to be completed to execute your first de-duplication job fired off against an IRIS Database.
Install
Clone the zingg.ai repo: https://github.com/zinggAI/zingg
We also need the JDBC driver for Zingg to connect with IRIS. Download the IRIS JDBC driver and add the path of the driver to spark.jars property of zingg.conf... organize this jar in the `thirdParty/lib` directory.
spark.jars=/home/sween/Desktop/PIDTOO/api/zingg/thirdParty/lib/intersystems-jdbc-3.7.1.jar
Match Criteria
This step takes some thought and can be fun if you are into this stuff or enjoy listening to black box recordings of plane crashes on YouTube. To demonstrate things, recall the fields we projected from "builder" to establish the match criteria. All of this is done in our python implementation that declares the PySpark job, which will be revealed in its entirety down a ways.
# FHIRSQL Source Object FIELDDEFS
# Pro Tip!
# These Fields are included in FHIRSQL Projections, but not specified in the Transform
fhirkey = FieldDefinition("Key", "string", MatchType.DONT_USE)
dbid = FieldDefinition("ID", "string", MatchType.DONT_USE)
# Actual Fields from the Projection
srcid = FieldDefinition("IdentifierValue", "string", MatchType.DONT_USE)
given = FieldDefinition("NameFamily", "string", MatchType.FUZZY)
family = FieldDefinition("NameGiven", "string", MatchType.FUZZY)
zip = FieldDefinition("AddressPostalCode", "string", MatchType.ONLY_ALPHABETS_FUZZY)
gender = FieldDefinition("Gender", "string", MatchType.FUZZY)
fieldDefs = [fhirkey, dbid, srcid, given, family,zip, gender]So the fields match the attributes in our IRIS project and the MatchTypes we set for each field type. You'll be delighted with what is available as you can immediately put them to good use with clear understanding.
Three common ones are here:
- FUZZY: Generalized matching with strings and stuff
- EXACT: No variations allowed, deterministic value, guards against domain conflicts sorta.
- DONT_USE: Fields that have nothing to do with the matching, but needed in the remediation or understanding in the output.
Some other favorites of mine are here, as they seem to work on dirty data a little bit better and make sense of multiple emails.
- EMAIL: Hacks off the domain name and the @, and uses the string.
- TEXT: Things between two strings
- ONLY_ALPHABETS_FUZZY: Omits integers and non-alphas where they clearly do not belong for match consideration
The full list is available here for the curious.
Model
Create a folder to build your model... this one follows the standard in the repo, create folder `models/700`.
# Object MODEL
args = Arguments()
args.setFieldDefinition(fieldDefs)
args.setModelId("700")
args.setZinggDir("/home/sween/Desktop/PIDTOO/api/zingg/models")
args.setNumPartitions(4)
args.setLabelDataSampleSize(0.5)Input
These values are represented in what we setup in the previous steps on "builder"
# "builder" Projected Object FIELDDEFS
InterSystemsFHIRSQL = Pipe("InterSystemsFHIRSQL", "jdbc")
InterSystemsFHIRSQL.addProperty("url","jdbc:IRIS://3.131.15.187:1972/FHIRDB")
InterSystemsFHIRSQL.addProperty("dbtable", "PIDTOO.Patient")
InterSystemsFHIRSQL.addProperty("driver", "com.intersystems.jdbc.IRISDriver")
InterSystemsFHIRSQL.addProperty("user","fhirsql")
# Use the same password that is on your luggage
InterSystemsFHIRSQL.addProperty("password","1234")
args.setData(InterSystemsFHIRSQL)Output
Now this table is not a projected table by "builder", it is an empty table we created to house the results from Zingg.
# Zingg's Destination Object on IRIS
InterSystemsIRIS = Pipe("InterSystemsIRIS", "jdbc")
InterSystemsIRIS.addProperty("url","jdbc:IRIS://3.131.15.187:1972/FHIRDB")
InterSystemsIRIS.addProperty("dbtable", "PIDTOO.PatientDups")
InterSystemsIRIS.addProperty("driver", "com.intersystems.jdbc.IRISDriver")
InterSystemsIRIS.addProperty("user","fhirsql")
# Please use the same password as your luggage
InterSystemsIRIS.addProperty("password","1234")
args.setOutput(InterSystemsIRIS)If you are trying to understand the flow here, hopefully this will clarify things.
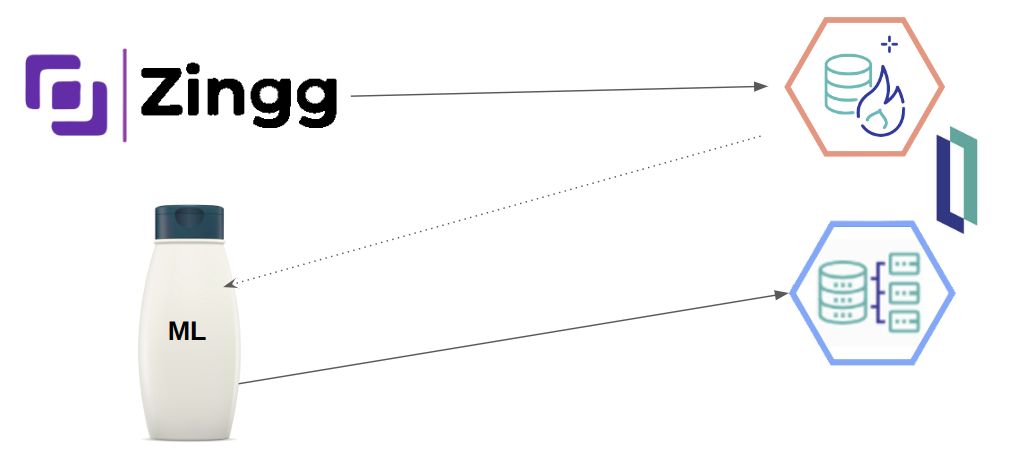
1. Zingg reads the projected data from builder (PIDTOO.Patient)
2. We do some "ML Shampoo" against the data.
3. Then we write the results back to builder (PIDTOO.PatientDups)
Thanks to @Sergei Shutov for the icons!
ML Shampoo
Now, Zingg is a supervised machine learning implementation, so you are going to have to train it up front, and at an interval to keep the model smart. Its the "rinse and repeat" part of the analogy if you havent gotten the shampoo reference from above.
- Find - Go get some data
- Label - Prompt the human to help us out
- Train - Once we have enough labelled data
- Match - Zingg writes out the results
- Link
bash scripts/zingg.sh --properties-file config/zingg-iris.conf --run pidtoo-iris/FHIRPatient-IRIS.py findTrainingData
bash scripts/zingg.sh --properties-file config/zingg-iris.conf --run pidtoo-iris/FHIRPatient-IRIS.py label
bash scripts/zingg.sh --properties-file config/zingg-iris.conf --run pidtoo-iris/FHIRPatient-IRIS.py train
For the find, you will get something a little bit like the below if things are working correctly.
findTrainingData
2023-06-07 16:20:03,677 [Thread-6] INFO zingg.ZinggBase - Start reading internal configurations and functions
2023-06-07 16:20:03,690 [Thread-6] INFO zingg.ZinggBase - Finished reading internal configurations and functions
2023-06-07 16:20:03,697 [Thread-6] WARN zingg.util.PipeUtil - Reading input jdbc
2023-06-07 16:20:03,697 [Thread-6] WARN zingg.util.PipeUtil - Reading Pipe [name=InterSystemsFHIRSQL, format=jdbc, preprocessors=null, props={password=1234luggage, driver=com.intersystems.jdbc.IRISDriver, dbtable=PIDTOO.Patient, user=fhirsql, url=jdbc:IRIS://3.131.15.187:1972/FHIRDB}, schema=null]
2023-06-07 16:20:38,708 [Thread-6] WARN zingg.TrainingDataFinder - Read input data 71383
2023-06-07 16:20:38,709 [Thread-6] WARN zingg.util.PipeUtil - Reading input parquet
2023-06-07 16:20:38,710 [Thread-6] WARN zingg.util.PipeUtil - Reading Pipe [name=null, format=parquet, preprocessors=null, props={location=/home/sween/Desktop/PIDTOO/api/zingg/models/700/trainingData//marked/}, schema=null]
2023-06-07 16:20:39,130 [Thread-6] WARN zingg.util.DSUtil - Read marked training samples
2023-06-07 16:20:39,139 [Thread-6] WARN zingg.util.DSUtil - No configured training samples
2023-06-07 16:20:39,752 [Thread-6] WARN zingg.TrainingDataFinder - Read training samples 37 neg 64
2023-06-07 16:20:39,946 [Thread-6] INFO zingg.TrainingDataFinder - Preprocessing DS for stopWords
2023-06-07 16:20:40,275 [Thread-6] INFO zingg.util.Heuristics - **Block size **35 and total count was 35695
2023-06-07 16:20:40,276 [Thread-6] INFO zingg.util.Heuristics - Heuristics suggest 35
2023-06-07 16:20:40,276 [Thread-6] INFO zingg.util.BlockingTreeUtil - Learning indexing rules for block size 35
2023-06-07 16:20:40,728 [Thread-6] WARN org.apache.spark.sql.execution.CacheManager - Asked to cache already cached data.
2023-06-07 16:20:40,924 [Thread-6] INFO zingg.util.ModelUtil - Learning similarity rules
2023-06-07 16:20:41,072 [Thread-6] WARN org.apache.spark.sql.catalyst.util.package - Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.sql.debug.maxToStringFields'.
2023-06-07 16:20:41,171 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] Stage class: LogisticRegression
2023-06-07 16:20:41,171 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] Stage uid: logreg_d240511c93be
2023-06-07 16:20:41,388 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] training: numPartitions=1 storageLevel=StorageLevel(1 replicas)
2023-06-07 16:20:41,390 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"featuresCol":"z_feature","fitIntercept":true,"labelCol":"z_isMatch","predictionCol":"z_prediction","probabilityCol":"z_probability","maxIter":100}
2023-06-07 16:20:41,752 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"numClasses":2}
2023-06-07 16:20:41,752 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"numFeatures":164}
2023-06-07 16:20:41,752 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"numExamples":101}
2023-06-07 16:20:41,753 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"lowestLabelWeight":"37.0"}
2023-06-07 16:20:41,753 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"highestLabelWeight":"64.0"}
2023-06-07 16:20:41,755 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"sumOfWeights":101.0}
2023-06-07 16:20:41,756 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [06bfeecf] {"actualBlockSizeInMB":"1.0"}
2023-06-07 16:20:42,149 [Executor task launch worker for task 0.0 in stage 29.0 (TID 111)] WARN com.github.fommil.netlib.BLAS - Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS
2023-06-07 16:20:42,149 [Executor task launch worker for task 0.0 in stage 29.0 (TID 111)] WARN com.github.fommil.netlib.BLAS - Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS
2023-06-07 16:20:44,470 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [5a6fd183] training finished
2023-06-07 16:20:44,470 [Thread-6] INFO zingg.model.Model - threshold while predicting is 0.5
2023-06-07 16:20:44,589 [Thread-6] INFO org.apache.spark.ml.util.Instrumentation - [aa3d8dc3] training finished
2023-06-07 16:20:44,600 [Thread-6] INFO zingg.TrainingDataFinder - Writing uncertain pairs
2023-06-07 16:20:47,788 [Thread-6] WARN zingg.util.PipeUtil - Writing output Pipe [name=null, format=parquet, preprocessors=null, props={location=/home/sween/Desktop/PIDTOO/api/zingg/models/700/trainingData//unmarked/}, schema=null]
Now, we train the Cylon with supervised learning, lets give it a go.
Label
2023-06-07 16:24:06,122 [Thread-6] INFO zingg.Labeller - Processing Records for CLI Labelling
Labelled pairs so far : 37/101 MATCH, 64/101 DO NOT MATCH, 0/101 NOT SURE
Current labelling round : 0/20 pairs labelled
+----------------+------+---------------+----------+---------+-----------------+------+-------------------+
|Key |ID |IdentifierValue|NameFamily|NameGiven|AddressPostalCode|Gender|z_source |
+----------------+------+---------------+----------+---------+-----------------+------+-------------------+
|Patient/05941921|303302|null |davis |derek |28251 |male |InterSystemsFHIRSQL|
|Patient/05869254|263195|null |davis |terek |27|07 |male |InterSystemsFHIRSQL|
+----------------+------+---------------+----------+---------+-----------------+------+-------------------+
Zingg predicts the above records MATCH with a similarity score of 0.51
What do you think? Your choices are:
No, they do not match : 0
Yes, they match : 1
Not sure : 2
To exit : 9
Please enter your choice [0,1,2 or 9]:
Now, do what the cylon says, and do this a lot, maybe during meetings or on the Red Line on your way or heading home from work (Get it? Train). You'll need enough labels for the train phase, where Zingg goes to town and works its magic finding duplicates.
bash scripts/zingg.sh --properties-file config/zingg-iris.conf --run pidtoo-iris/FHIRPatient-IRIS.py trainOk, here we go, lets get our results:
bash scripts/zingg.sh --properties-file config/zingg-iris.conf --run pidtoo-iris/FHIRPatient-IRIS.py matchWe now have some results back in the PIDTOO.PatientDups table that gets us to the point of things. We are going to use @Dmitry Maslennikov 's sqlalchemy sorcery to connect via the notebook and inspect our results.
from sqlalchemy import create_engine
# FHIRSQL Builder Cloud Instance
engine = create_engine("iris://fhirsql:1234@3.131.15.187:1972/FHIRDB")
conn = engine.connect()
query = '''
SELECT
TOP 20 z_cluster, z_maxScore, z_minScore, NameGiven, NameFamily, COUNT(*)
FROM
PIDTOO.PatientDups
GROUP BY
z_cluster
HAVING
COUNT(*) > 1
'''
result = conn.exec_driver_sql(query)
print(result)It takes a little bit to interpret the results, but, here is the result of the brief training on loading the NC voters data into FHIR.
loadncvoters2fhir.py ©
import os
import requests
import json
import csv
'''
recid,givenname,surname,suburb,postcode
07610568,ranty,turner,statesvikle,28625
'''
for filename in os.listdir("."):
print(filename)
if filename.startswith("ncvr"):
with open(filename, newline='') as csvfile:
ncreader = csv.reader(csvfile, delimiter=',')
for row in ncreader:
patid = row[0]
given = row[1]
family = row[2]
postcode = row[4]
patientpayload = {
"resourceType": "Patient",
"id": patid,
"active": True,
"name": [
{
"use": "official",
"family": family,
"given": [
given
]
}
],
"gender": "male",
"address": [
{
"postalCode": postcode
}
]
}
print(patientpayload)
url = "https://fhir.h7kp7tr48ilp.workload-nonprod-fhiraas.isccloud.io/Patient/" + patid
headers = {
'x-api-key': '1234',
'Content-Type': 'application/fhir+json'
}
response = requests.request("PUT", url, headers=headers, data=json.dumps(patientpayload))
print(response.status_code)
The output Zingg gave us is pretty great for the minimal effort I put in training things in between gas lighting.
z_cluster is the id Zingg assigns to the duplicates, I call it the "dupeid", just understand that is the identifier of the you want to query to examine the potential duplicates... Im accustomed to trusting a minScore of 0.00 and anything over 0.90 for a score for examination.
(189, 0.4677305247393828, 0.4677305247393828, 'latonya', 'beatty', 2)
(316, 0.8877195988867068, 0.7148998161578, 'wiloiam', 'adams', 5)
(321, 0.5646965557084127, 0.0, 'mar9aret', 'bridges', 3)
(326, 0.5707960437038071, 0.0, 'donnm', 'johnson', 6)
(328, 0.982044685998597, 0.40717509762282955, 'christina', 'davis', 4)
(333, 0.8879795543643093, 0.8879795543643093, 'tiffany', 'stamprr', 2)
(334, 0.808243240184001, 0.0, 'amanta', 'hall', 4)
(343, 0.6544295790716498, 0.0, 'margared', 'casey', 3)
(355, 0.7028336885619522, 0.7028336885619522, 'dammie', 'locklear', 2)
(357, 0.509141927875999, 0.509141927875999, 'albert', 'hardisfon', 2)
(362, 0.5054569794103886, 0.0, 'zarah', 'hll', 6)
(366, 0.4864567456390275, 0.4238040425261962, 'cara', 'matthews', 4)
(367, 0.5210329255531461, 0.5210329255531461, 'william', 'metcaif', 2)
(368, 0.6431091575056218, 0.6431091575056218, 'charles', 'sbarpe', 2)
(385, 0.5338624802449684, 0.0, 'marc', 'moodt', 3)
(393, 0.5640435106505274, 0.5640435106505274, 'marla', 'millrr', 2)
(403, 0.4687497402769476, 0.0, 'donsna', 'barnes', 3)
(407, 0.5801171648347092, 0.0, 'veronicc', 'collins', 35)
(410, 0.9543673811569922, 0.0, 'ann', 'mason', 7)
(414, 0.5355771790403805, 0.5355771790403805, 'serry', 'mccaray', 2)Let's pick the "dupeid" 410 and see how we did, the results seem to think there are 7 duplicates.
 Ok, so there are the 7 records, with variable scores... Lets dial it in a little bit more and only report back a score of higher than .90.
Ok, so there are the 7 records, with variable scores... Lets dial it in a little bit more and only report back a score of higher than .90.
.png)
Wooo!
So now, if you recall, we have the `MatchType.DONT_USE` for `Key` in our match criteria showing up in our output, but you know what?
USE IT!
- https://fhir.h7kp7tr48ilp.workload-nonprod-fhiraas.isccloud.io/Patient/…
- https://fhir.h7kp7tr48ilp.workload-nonprod-fhiraas.isccloud.io/Patient/…
These are the FHIR patient resource ids in the FHIR repository we have identified as duplicates and require remediation.
🔥