Hi All,
I trying to get the DisplayList data of the ValueLIst from Java using Springboot. when I try to get the DislayList data via java code but I'm getting the VALUELIST data. I don't get any idea to get that DisplayList data. Below is the example
Java Code:
public String PetName;
public List<Pet> getPet() {
return ser.findAll();
}
List<Pet> arrayList = getPet();
for (Patient list : arrayList) {
String pet= list.getPet();
System.out.

.png)
.png)
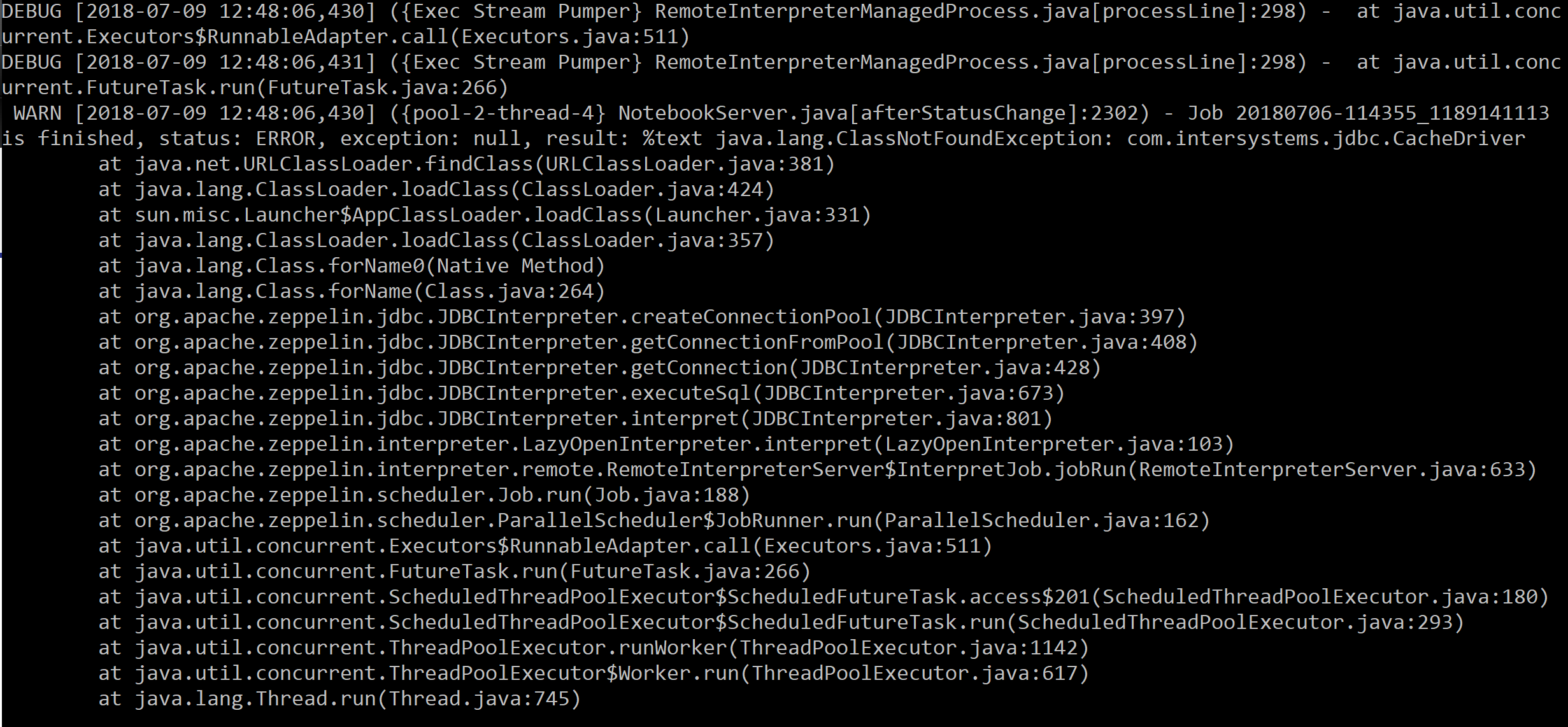
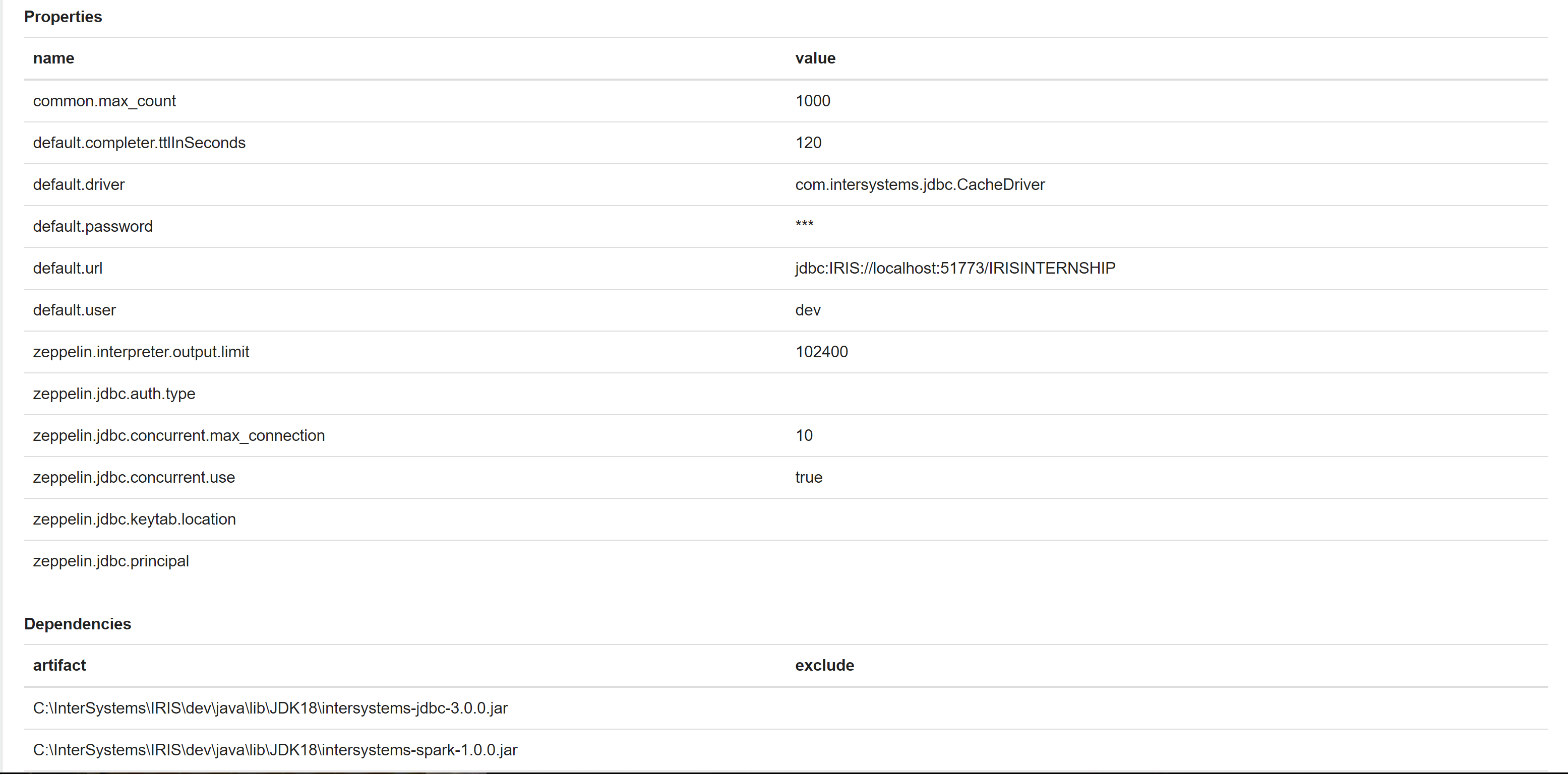
 This error appears:
This error appears: