Hello everyone!
I am writing a SQL CALL (using JDBC) to a stored procedure that outputs a structured object (Oracle Object).
Java Database Connectivity (JDBC) is an application programming interface (API) for the programming language Java, which defines how a client may access a database.
Currently could be downloaded from here.
Hello everyone!
I am writing a SQL CALL (using JDBC) to a stored procedure that outputs a structured object (Oracle Object).
We are planning to build a REST API with the Java Quarkus Framework.
This Caché instance already have COS applications running and consuming connections and licenses.
After doing this, we will migrate to IRIS.
Is there any pitfalls that we must be aware before taking this approach?
If you want to see some code the PoC can be found here.
Thanks.
Consider a Natural Key with an Identity (Serial) field.
I cannot seem to acquire the generated value after persisting my entity. That is, the returned entity by Spring Data's "save" does not have the generated value.
The value is generated by the database, and I can query it after repository.save(entity).
I have done some testing and created a Github repo with it...
https://github.com/jesjobom/iris-hibernate-key-test
Am I missing something?
I am using a Gradle Project for testing APIs, but I need to connect to the database.
I already put this on the dependencies:
.png)
And I'm trying to use this way:
.png)
But I'm keep getting this error: java.lang.ClassNotFoundException: com.intersys.jdbc.CacheDriver
Is there any place that I can put a JAR file? Because the project has no lib folder (I already tried to add it, but it doesn't work).
5 years ago, on December 19, 2013, the ESA launched an orbital telescope called Gaia. Learn more about the Gaia mission on the official website of the European Space Agency or in the article by Vitaly Egorov (Billion pixels for a billion stars).

However, few people know what technology the agency chose for storing and processing the data collected by Gaia. Two years before the launch, in 2011, the developers were considering a number of candidates (see “Astrostatistics and Data Mining” by Luis Manuel Sarro, Laurent Eyer, William O’Mullane, Joris De Ridder, pp. 111-112):
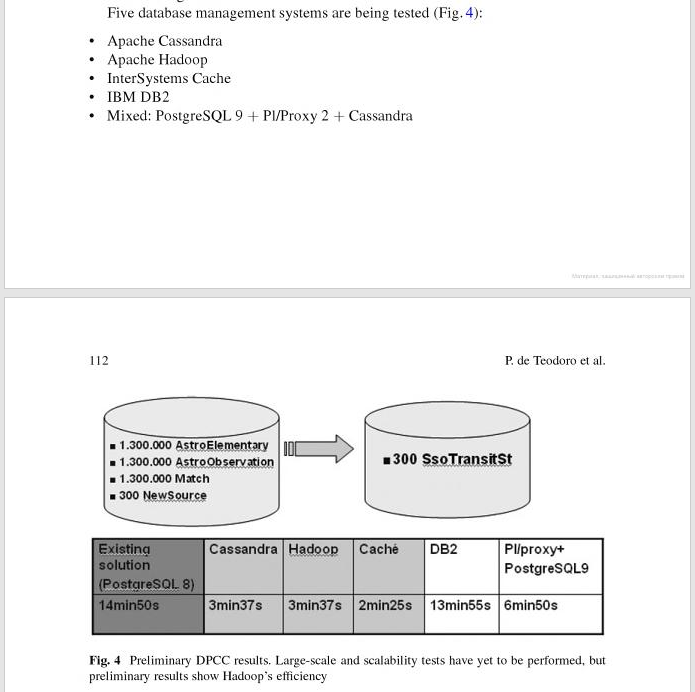
Comparing the technologies side-by-side produced the following results (source):
| Technology | Time |
|---|---|
| DB2 | 13min55s |
| PostgreSQL 8 | 14min50s |
| PostgreSQL 9 | 6min50s |
| Hadoop | 3min37s |
| Cassandra | 3min37s |
| Caché | 2min25s |
The first four will probably sound familiar even to schoolchildren. But what is Caché XEP?
One of our apps uses a class query to support a ZEN Report and works just fine in that report, producing the expected results every time. We’ve since migrated to InterSystems Reports and noticed that, for a report using the same class query, 100s of extra rows with the same column values appear at its bottom.
We eliminated InterSystems Reports as the source of the problem by recreating the same “extra rows” issue with an Excel spreadsheet calling the same class query as a stored procedure.
What was the issue?
I want to INSERT a record in a database using JDBC in OBJECTSCRIPT. At the same time, I want to obtain the insert ID. Is there a way to achieve this using the SQL Outbound adapter?
My code is something like this now:
Property Adapter As EnsLib.SQL.OutboundAdapter;
set sql = " INSERT INTO Prenotazioni_CUP "_
" (ID, cf
" VALUES (SEQTAB.NextVal, ?) "
set status = ..Adapter.ExecuteUpdate(.rs, sql, pRequest.cfAssistito)
Hello all,
I'm trying to setup the JDBC Gateway Server so customers can connect to IRIS remotely using JDBC and not ODBC. But I'm facing a problem connecting, as our system department tells me IRIS is using the loopback address (127.0.0.1) and that makes remote systems cannot connect to port 53773 (the default port for that).
So, I would like to change this 127.0.0.1 host for the hostname but I cannot see where to do it:
.png)
Anyone with experience here to help me? :-)
Thanks a lot
Once a week we are attempting to load an XML file from Workday into a MS SQL table using JDBC and Store Procedures. There is approx 102999 records in this XML file. We are struggling with processing the entire file within a reason amount of time. We feed the XML through a BPL to then populate values in a stored procedure then call the stored procedure through a Business Operation. I have tried splitting out the Business Operations to make two calls, but we still continue to see an issue loading the XML into MS SQL.
I'm using a JDBC driver to connect PGSQL -> Cache. I'm noticing when I run SELECT queries and COUNT(*) command against the same table, I get different result sets. I'm pretty new to Cache in general - so I'm trying to understand why these would be different.
Examples (TransID and InvNum should occur in every "row"):
SELECT COUNT(*) FROM ACCT.Services = 1,090,324 WHERE ACCT.Dept = 483
SELECT TransID FROM ACCT.Services = 1,085,776 WHERE ACCT.Dept = 483
SELECT InvNum FROM ACCT.Services = 586,023 WHERE ACCT.
Keyword: Pandas DataFrame, IRIS, Python, JDBC
Pandas DataFrame is popular tool for EDA (Exploratory Data Analysis). In ML tasks, the first thing we usually perform is to understand the data a bit more. Last week I was trying this Covid19 dataset in Kaggle Basically the data is a spreadsheet of 1925 encounter rows with 231 columns, and the task is simply to predict whether a patient (linked to 1 or more encounter records) would be admitted to ICU. So it's a normal classification task, and we would as usual use padas.DataFrame to take a quick look first.
Hi all,
I'm trying to access via JDBC my community installation but the connection is always rejected. The same code (python code) using the stand-alone version of Intersystems IRIS works fine.
Is the community edition limited in this case? I can't see it in the official documentation: https://irisdocs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Pag…
When using "IDENTITY" as my primary key, I can select the last inserted ID with
SELECT LAST_IDENTITY() FROM %TSQL_sys.snf;
Actually this is how Hibernate + Iris' Driver acquires the inserted ID when mapping with
@GeneratedValue(strategy = GenerationType.IDENTITY)
Now, considering that I am using the type "SERIAL" as my primary key instead, how can I get the last inserted ID?
Note that with "SERIAL" I can forcefully insert any value for this ID, from which Iris will continue generating values.
Built in multi model integration using InterSystems iris data platform
Solution of hospital information inquiry business
Integration of hospital information query business solutions using InterSystems IRIS data platform with built-in multiple models
### Summary:
With the gradual improvement of hospital information construction, there are more and more hospital subsystems, and more and more interfaces between systems. At the same time, the interface cost is increasing, and the management work is becoming more and more complex.
DataGrip is a multi-engine database environment targeting the specific needs of professional SQL developers, DataGrip makes working with databases an enjoyable and productive experience.
To work with InterSystems IRIS from DataGrip you'll need to add InterSystems JDBC driver first (once per DataGrip) and after that add all your InterSystems IRIS connections.
Part 1: Add InterSystems IRIS JDBC Driver
1. Go To File → DataSources
2. Go to + → Driver
.png)
3. Set Driver properties:
com.intersystems.jdbc.I have a case where I need to look up the NPI provider against an External MS SQL database to retrieve our Provider Identifier to send to a downstream system. In the past I would use a Business Process (BPL) to connect to the outside MS SQL via JDBC and get that information for me. But I was thinking instead of creating a BPL process to do this, would it be better just to link to the outside MS SQL database table to retrieve the information in a SQL statement within a DTL?
So it is better to link to an outside database via a Linked Table wizard?
Keywords: Python, JDBC, SQL, IRIS, Jupyter Notebook, Pandas, Numpy, and Machine Learning
This is another 5-minute simple note on invoking the IRIS JDBC driver via Python 3 within i.e. a Jupyter Notebook, to read from and write data into an IRIS database instance via SQL syntax, for demo purpose.
Last year I touched on a brief note on Python binding into a Cache database (section 4.7) instance.
Hi Cache team, I am in the need of listing all the user defined schemas that are present my Cache db and also the user defined tables and views and Columns of those tables and views through Queries. So that I can write some JDBC code to run the queries and fetch the above metadata. Any help is appreciated.
Thanks in Advance,
Kranthi kiran.
Hey Developers!
This week is a voting week for the InterSystems Full Stack Contest!
So, it's time to give your vote to the best solutions built with InterSystems IRIS.
🔥 You decide: VOTING IS HERE 🔥

How to vote? This is easy: you will have one vote, and your vote goes either in Experts Nomination or in Community Nomination.
Hey Developers!
We're pleased to announce the next competition of creating open-source solutions using InterSystems IRIS! Please welcome:
⚡️ InterSystems Full Stack Contest ⚡️
Duration: September 21 - October 11, 2020

Hi Community!
We are pleased to invite all the developers to the upcoming InterSystems Full Stack Contest Kick-off Webinar! The topic of this webinar is dedicated to the Full Stack Contest.
On this webinar, we’ll demo the IRIS Full Stack template and answer the questions on how to develop, build and deploy full stack applications in InterSystems IRIS.
Date & Time: Monday, September 21 — 11:00 AM EDT
Speakers:
🗣 @Evgeny Shvarov, InterSystems Developer Ecosystem Manager
🗣 @Raj Singh, InterSystems Product Manager - Developer Experience

Hi Developers!
Here're the technology bonuses for the Full Stack Contest that will give you extra points in the voting:
See the details below.
Hello,
Recently I tried to connect to JDBC on IRIS 2020.3+ and I came across the following error:
SQL Error [461] [08S01]: [InterSystems IRIS JDBC] Communication link failure: Communication error: Server closed communication device
This error implies that the port is not open.
Checking with the netstat command:
irisowner@78c3e30b7f41:/opt/irisapp$ netstat -a
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0 0.0.0.0:1972 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.11:38005 0.0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:52773 0.0.Many times it is necessary copy or send files to your docker container instance.
In my case was with IRIS JDBC driver.
Docker has this recipe for this (credits to https://docs.docker.com/engine/reference/commandline/cp/):
docker cp [OPTIONS] CONTAINER:SRC_PATH DEST_PATH|- docker cp [OPTIONS] SRC_PATH|- CONTAINER:DEST_PATH
But to copy you need your container name. Write this command for this:
docker ps
In my, my-iris is the container name.
If you need to know file location into your docker file system too, write:
1. To go to bash of your docker instance: docker exec -it my-iris /bin/bash.
2. Write cd .
Hi Guys,
I am trying to pull data from CacheDB and push into elasticsearch using logstash. In the configuration file i am giving the following. But it is throwing error No Suitable Driver Found for jdbc:Cache://ipaddress:port/namespace. Could anyone please help to resolve this ? I tried both JDK17 and JDK18 but no luck.
My Config file is as follows
input {
jdbc {
clean_run => true
jdbc_driver_library => "C:\InterSystems\Cache\dev\java\lib\JDK17\cache-jdbc-2.0.0.jar"
jdbc_driver_class => "com.intersys.jdbc.
The Caché System Management Portal includes a robust web-based SQL query tool, but for some applications it’s more convenient to use a dedicated SQL client installed on a user’s PC.
SQuirreL SQL is a well known open source SQL client built in Java, which uses JDBC to connect to a DBMS. As such, we can configure SQuirreL to connect to Caché using the Caché JDBC driver.
The JAR file containing the Caché JDBC driver is installed automatically by the Caché installer when installing a full Caché instance or when installing client components only.
I have a class that writes to an external SQL Server database. When the field is empty, it does not write the column and the column has the value NULL. In some cases, I want the column to be the value of the empty string instead of NULL.
{
Property MessageType As %String
}
The message that is passed to this class shows:
<MessageType></MessageType>
Which writes the field as NULL with:
tSQL = "insert into myTable (MessageType) values (?)"
set tSC = ..Adapter.ExecuteUpdate(.tNumberOfRowsUpdated,tSQL,myRequestClass
Everyone
There is a setQueryTimeout method in the% Net.Remote.Java.JDBCGateway class of IRIS, how to use Ensemble2016 to achieve this function?
Intersystems use JReport as their reporting framework.
Are there any free version available for developers to try it out? If yes, can I avail the link?
Is there any free trial version for 'DeepSee'? if yes, can I avail the link?
Thanks in advance for your feedback.
HI I am using below code to retrieve the last inserted ID of the table. It works when we do not set any custom column as IDKey. If we define any column as
IDKey below code does not return any IDKey. I know when i am defining any column as IDKey its not auto generated , but whats the best way to get the ID column value
String sql = "INSERT INTO TestFramework_UI_Data.Execution (TotalTestSteps) VALUES (0)";
//ResultSet rs = createExecutionSt.executeQuery("SELECT * FROM TestFramework_E2E_Data_TestData.TestCases");
int t = createExecutionSt.
{kind=link}