We have an OAuth server configured as an identity provider, and we have an external application (from another provider) that connects correctly with OAuth.
Due to the needs of the project, what we want to do is the following:
Is there a way to remote connect to IRIS terminal from my local machine?
I can remote connect to Studio & SMP from my locally windows installed IRIS cube to another IRIS installation in a Linux server, but not the case when trying to connect to the Terminal, is there a way to do so? I'm currently using ssh client but that one times out quickly
I deployed an IRIS REST application using Installer class. I think I created the namespace FEEDER database with %DB_Default resource and I used the same resource in Web Application roles. I allowed Unauthenticated Authentication method. I used ^%ISCLOG and reviewed ^ISCLOG. I do not understand why I get 403 Forbidden response.
I want to create a scheduler to montor the status of list of backend jobs ( say limit is 10). there going to be job queue. Need to pick a job form job queue when one of the current processing job is finished. What is the best way to implement this
Trying to start investigating an error we are seeing with multiple of the same messages getting sent to the same vendor. We receive an HL7 message with an RTF embedded from our EMR, send it through a DTL to just update the Patient Class, and then send it onto the Operation which is TCP.
I'm exploring this right now: given a bunch of types defined as Pydantic models, how can I come up with an equivalent %RegisteredObject/%SerialObject and convert to/from (e.g., to support persistence and match validation as much as possible)?
People who know Python better than I do (e.g., your average undergraduate from this decade): is this a stupid idea or a cool idea? Has anyone else done this before?
I've a list of running scheduled task in task manger and would to crate a tasks to monitor if any of my tasks has stopped running, is there a function to check tasks status?
I'd like to ask you for recommendations on how to properly use repository dependencies when using VSCode and Client-side editing.
Suppose I have projects A, B and C, with A being independent, B depending on A, and C depending on A and B.
I am currently working with the main project C, and I want to be able to contribute to all the other projects in a single VSCode window (instead of opening three instances). How do you solve this problem? Git submodules? ZPM? Something else?
We are receiving the report in text format and it has special characters like ', - like that in the text. Source system is using the UTF8 encoding format hence the text is showing as ' � ' . Is there a way to convert the utf8 to actual character in the DTL.
I'm working with routes for a rest service with intersystems iris. I have a working /test path, but I want to create a regex that accepts any path passed after /test. example /test/sdjklsbdk or /test/sdfkjgbskdbf/skjbksdb/ksdjbdks
I used <Route Url="/test/(.*)" Method="POST" Call="test"/> and <Route Url="/test/:path" Method="POST" Call="test"/> and I got the error <PARAMETER> what could it be?
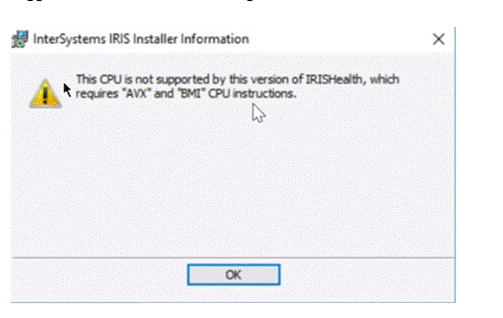
I’m looking for an API or command to determine if the supported CPU version exists on a Windows system.
Before installing IRIS, I would like to confirm whether the system/server has the supported CPU version. Do we have any API or command to check the details before starting the installation of IRIS 2024.1?
Is there a File Service (or a way to define a RecordMap) to intake a file that contains records that are JSON object?I would like to have my Service route each record(object) to a Process one at a time.
Been testing out the Production Validator toolkit, just to see what we can/not do with it. Seems really interesting and there seem to be some use cases for it that can really streamline some upgrades (or at least parts of upgrades) but I was running into so many hurdles with the documentation. I am curious if anyone else has used it.
I'm trying to create an indexed table with an vector field so I can search by the vector value. I've been investigating and found that to get the vector value based on the text (token), use a Python method like the following:
Is there a generic process for "walking" the structure of a virtual document - eg an HL7 message (EnsLib.HL7.Message) or an XML document (EnsLib.EDI.XML.Document).
At least we'd want to be able to visit all "nodes" (HL7 fields or sub-fields, XML nodes) in the virtual document and be able to work out/generate the Property Path (so we could call "GetValueAt").
We can just about come up with something generic for HL7, since it only nests down to 4 levels within each segment, though we're using numeric Property Path's at that point rather than symbolic ones (MSH:1.3 etc).
I need to make changes to OBX 5 which shows as immutable
I have tried ConstructClone, ThrowOnError, and Streams but I can't get the syntax correct
Example
OBX|1|TX|2000.02^REASON FOR REQUEST^AS4|142|REASON FOR REQUEST: Total Cost: 0.00||||||O ^^^^ remove "REASON FOR REQUEST" ^^ add cr/lf so down stream reports can be formatted more easily
I was using VSCode to edit a DTL because it seemed easier to copy/paste code from parts of the DTL I was editing. I tried to add <sql> tag and code to call a SELECT statement, but when I compiled I got the following error...
ERROR <Ens>ErrInvalidDTL: Invalid DTL
> ERROR #5490: Error running generator for method 'GetSourceDocType:osuwmc.Epic.MFN.DTL.EpicMFN949002Normalization'
I have a HL7 DTL in which I'm doing a lookup to a table based on a code value in the IN1:3 field. That incoming code may have a 1 to 1 mapping, or 1 to many mapping in a table. If it's a 1 to many, the values in the lookup table are comma delimited. If it's 1 to 1, that IN1 segment will map straight across. If it's one to many, I need to create additional IN1 segments. For example, if the incoming code maps to three, I need to map the original IN1 segment with one of the mapped codes, then create two additional IN1 segments with the other 2 codes for a total of 3 IN1 segments. I'd lik
I have two instances of IRIS, one is Production and another one is Staging (both managed by Docker) and I want to set up a full daily recover of the Staging server from a full backup of the Production server. I know how to do this manually using the DBREST utility, as well as how to make a copy of the database by making a full copy of the durable directory (however this option requires a full stop of the Production-database). What is the best way to automatically restore all databases from a full backup using scripting?
Hi Prasanth, I'm trying to convert SDA to FHIR and receiving the same error you mentioned above (ERROR #5770: Object open failed because 'ServiceIdIdx' key value of '' was not found) - how did you resolve your error?
 By date
By date
.png)
.png)
.png)
.png)
.png)