New
Since I started using Claude Code, my motivation to create things has skyrocketed.
Previously, even if I wanted to build something, actually doing the coding felt like a hassle, so unless there was a very strong need, I rarely went as far as programming. But now, if I just jot down the specifications, Claude Code handles the rest automatically, resulting in a dramatic improvement in productivity.
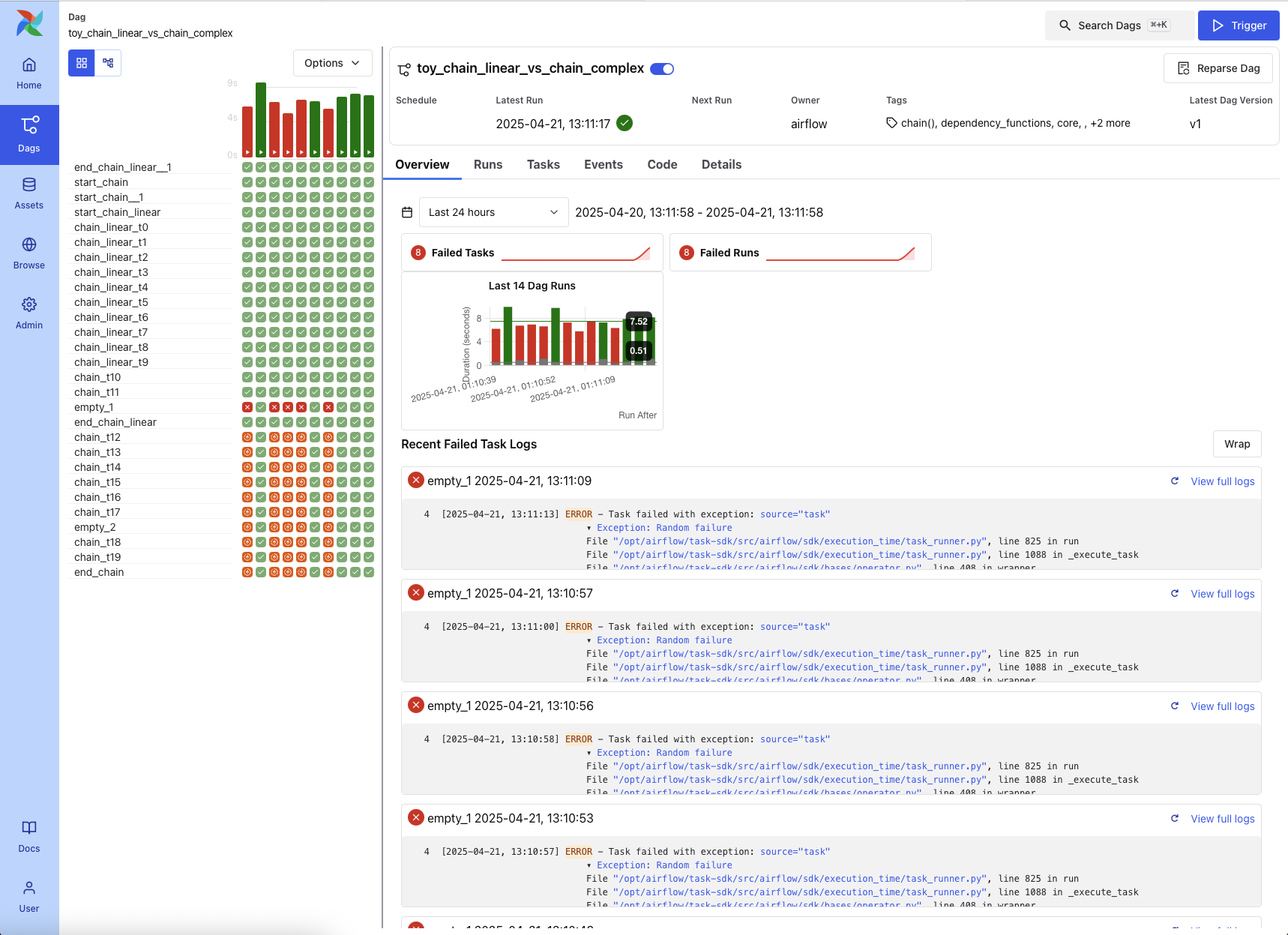
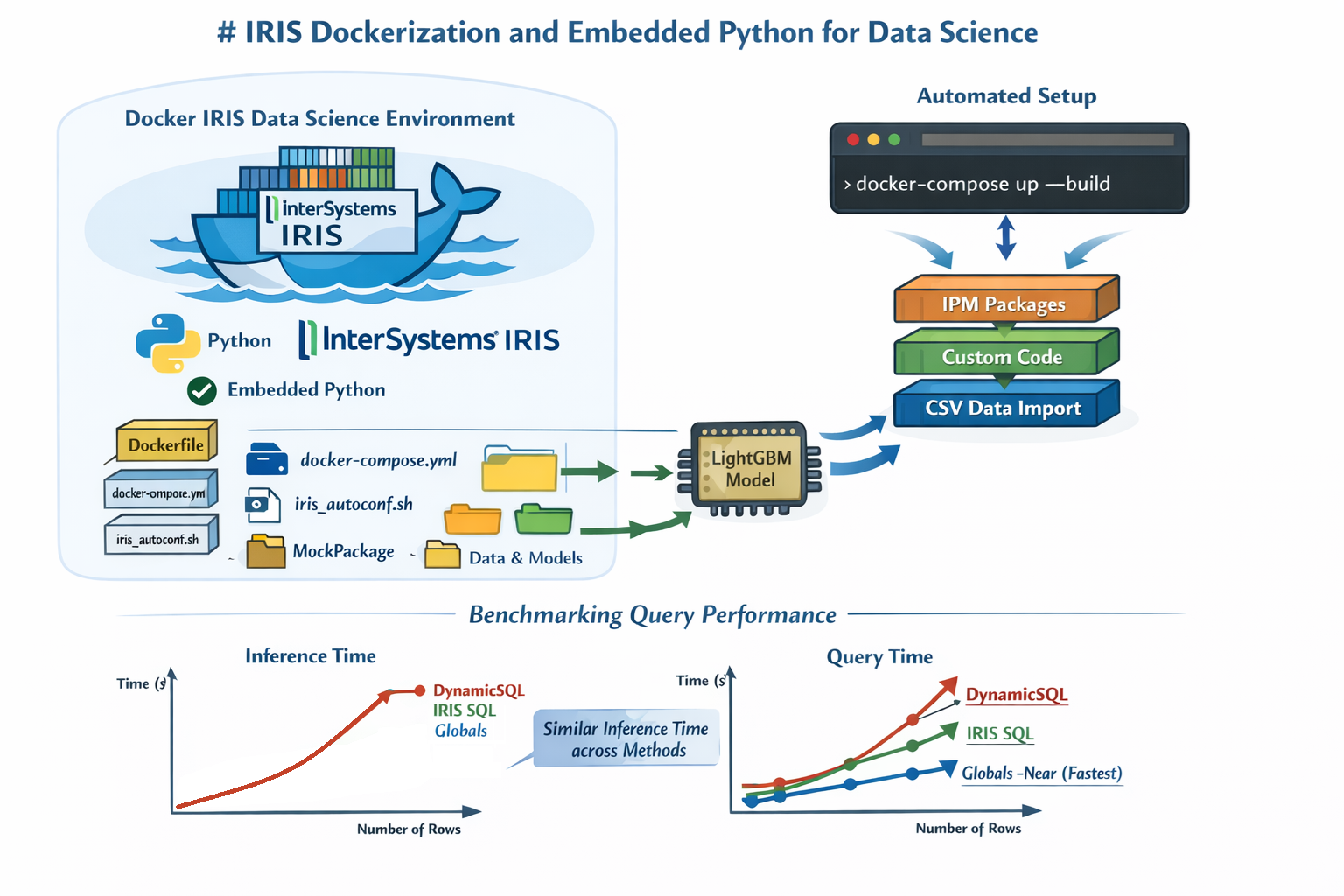
I come from a generation native to ObjectScript, so I used to feel some hesitation when it came to switching to Python.

.png)




.png)