By update
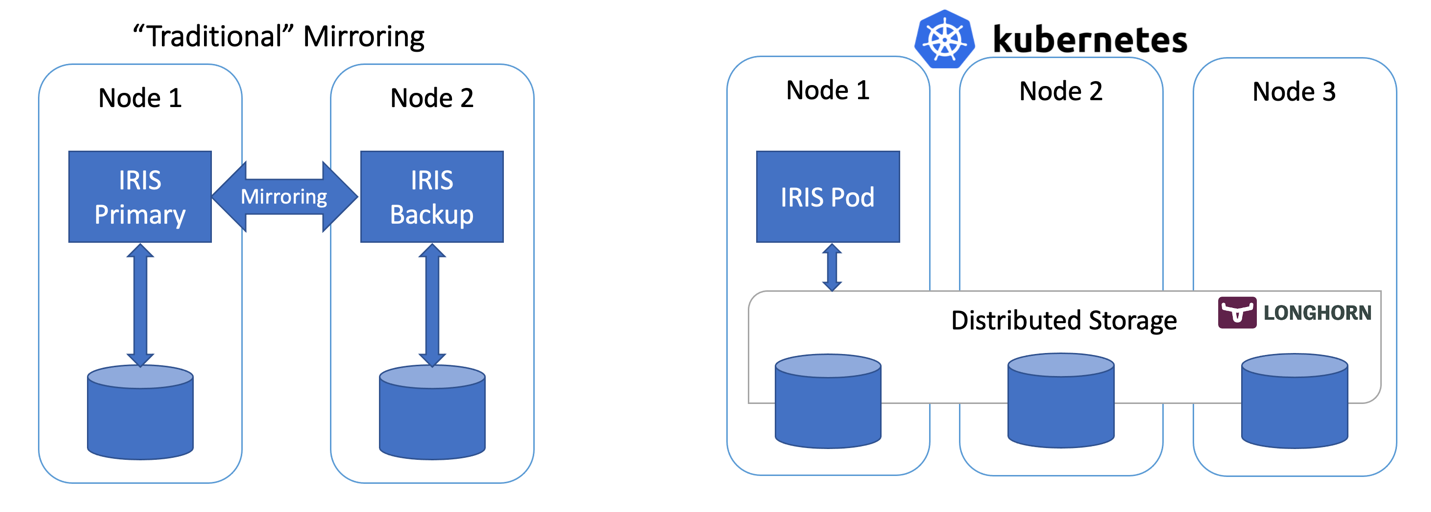
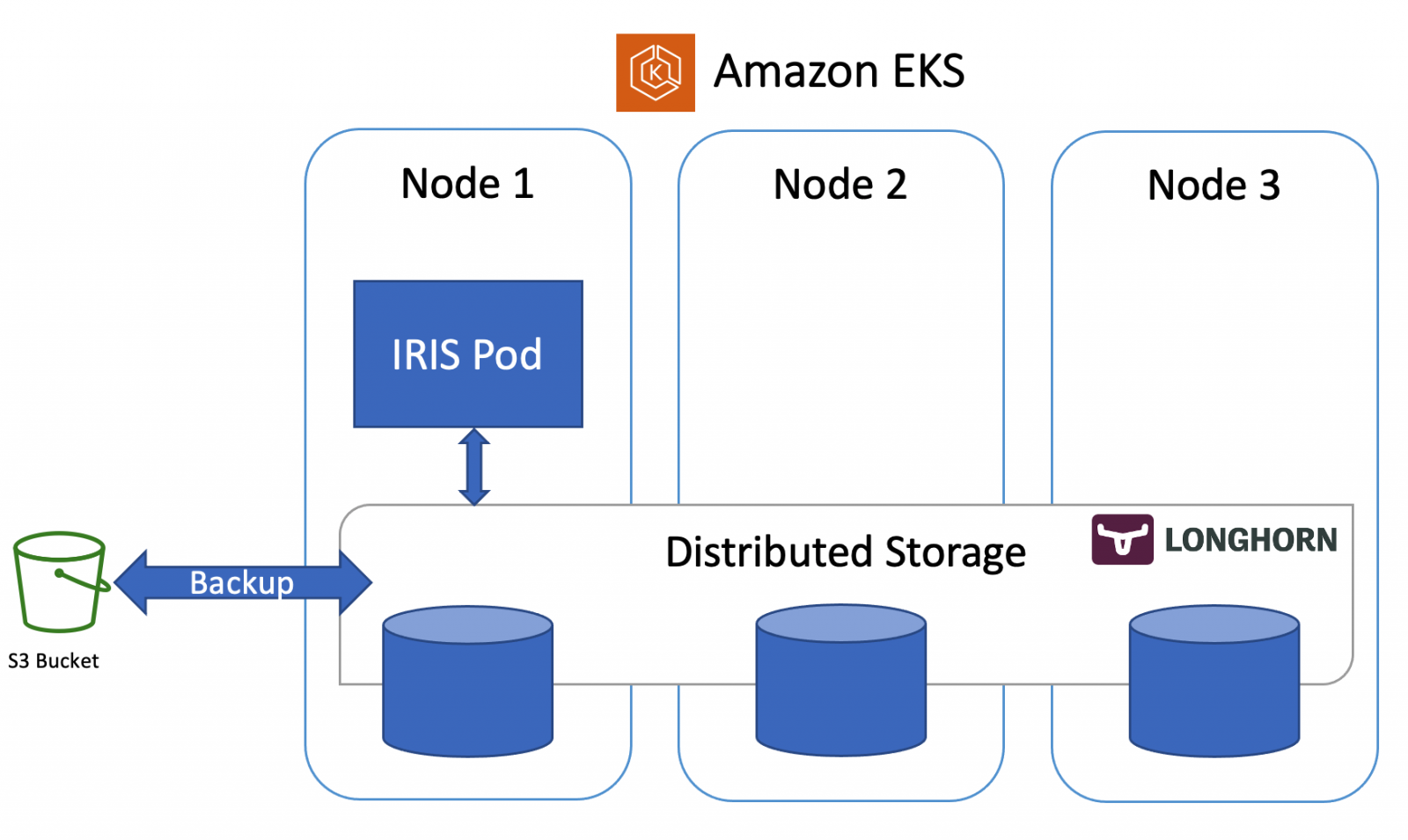
By updateAs an IT and cloud team manager with 18 years of experience with InterSystems technologies, I recently led our team in the transformation of our traditional on-premises ERP system to a cloud-based solution. We embarked on deploying InterSystems IRIS within a Kubernetes environment on AWS EKS, aiming to achieve a scalable, performant, and secure system. Central to this endeavor was the utilization of the AWS Application Load Balancer (ALB) as our ingress controller.
 Open Exchange app
Open Exchange app