Artificial Intelligence (AI) is the simulation of human intelligence processes by machines, especially computer systems. These processes include learning (the acquisition of information and rules for using the information), reasoning (using rules to reach approximate or definite conclusions) and self-correction.
Introducing Smart Clinical Sidechick — the intelligent, no-drama partner your EHR wishes it could be. She reads FHIR data in real time, interprets lab results without ghosting, and explains clinical alerts like she actually cares. Built with GPT-4 brains and YAML sass, she’s not here to replace your main EHR—just to make it look bad. Tired of irrelevant alerts and cryptic warnings? Sidechick serves up real, explainable insights, not vague “elevated risk” vibes. And when your backend crashes, she doesn’t panic—she self-heals.
Artificial Intelligence (AI) is getting a lot of attention lately because it can change many areas of our lives. Better computer power and more data have helped AI do amazing things, like improving medical tests and making self-driving cars. AI can also help businesses make better decisions and work more efficiently, which is why it's becoming more popular and widely used. How can one integrate the OpenAI API calls into an existing IRIS Interoperability application?
This will be a very short article as in April 2025 with Lovable and other Prompt-to-UI tools it becomes possible to build the frontend with prompting. Even to the folks like me who is not familiar with modern UI techics at all.
Well, I know at least the words javascript, typescript and ReactJS, so in this very short article we will be building the ReactJS UI to InterSystems FHIR server with Lovable.ai.
As you can see the new topic of the programming contest - AI Agents.
The topic was over-hyped recently on the Internet and has different meanings. You might get curious about what we mean by AI agents in regard to the InterSystems programming contest.
Traditional keyword-based search struggles with nuanced, domain-specific queries. Vector search, however, leverages semantic understanding, enabling AI agents to retrieve and generate responses based on context—not just keywords.
This article provides a step-by-step guide to creating an Agentic AI RAG (Retrieval-Augmented Generation) application.
Implementation Steps:
Create Agent Tools
Add Ingest functionality: Automatically ingests and index documents (e.g., InterSystems IRIS 2025.1 Release Notes).
# IRIS-Intelligent Butler IRIS Intelligent Butler is an AI intelligent butler system built on the InterSystems IRIS data platform, aimed at providing users with comprehensive intelligent life and work assistance through data intelligence, automated decision-making, and natural interaction. ## Application scenarios adding services, initializing configurations, etc. are currently being enriched ## Intelligent Butler
I just realized I never finished this serie of articles!
In today's article, we'll take a look at the production process that extracts the ICD-10 diagnoses most similar to our text, so we can select the most appropriate option from our frontend.
Looking for diagnostic similarities:
From the screen that shows the diagnostic requests received in HL7 in our application, we can search for the ICD-10 diagnoses closest to the text entered by the professional.
With the introduction of vector data types and the Vector Search functionality in IRIS, a whole world of possibilities opens up for the development of applications and an example of these applications is the one that I recently saw published in a public contest by the Ministry of Health from Valencia in which they requested a tool to assist in ICD-10 coding using AI models.
How could we implement an application similar to the one requested? Let's see what we would need:
In this article I will be discussing the use of an alternative LLM for generative IA. OpenIA is commonly used, in this article I will show you how to use it and the advantages of using Ollama
In the generative AI usage model that we are used to, we have the following flow:
InterSystems has been at the forefront of database technology since its inception, pioneering innovations that consistently outperform competitors like Oracle, IBM, and Microsoft.
The world of Generative AI has been pretty inescapable for a while, commercial models running on paid Cloud instances are everywhere. With your data stored securely on-prem in IRIS, it might seem daunting to start getting the benefit of experimentation with Large Language Models without having to navigate a minefield of Governance and rapidly evolving API documentation. If only there was a way to bring an LLM to IRIS, preferably in a very small code footprint....
We all know that having a set of proper test data before deploying an application to production is crucial for ensuring its reliability and performance. It allows to simulate real-world scenarios and identify potential issues or bugs before they impact end-users. Moreover, testing with representative data sets allows to optimize performance, identify bottlenecks, and fine-tune algorithms or processes as needed. Ultimately, having a comprehensive set of test data helps to deliver a higher quality product, reducing the likelihood of post-production issues and enhancing the overall user experience.
In this article, let's look at how one can use generative AI, namely Gemini by Google, to generate (hopefully) meaningful data for the properties of multiple objects. To do this, I will use the RESTful service to generate data in a JSON format and then use the received data to create objects.
🌍 Inclusion & Innovation in Education 🌍 Our project reimagines learning for all students, with a focus on accessibility and interactive experiences. Built with the goal of making education engaging and inclusive, the tool is designed to support students of all abilities in learning complex material in an intuitive way.
💡 What It Does This educational app transforms lesson presentations into interactive study sessions:
Generative artificial intelligence is artificial intelligence capable of generating text, images or other data using generative models, often in response to prompts. Generative AI models learn the patterns and structure of their input training data and then generate new data that has similar characteristics.
In today's data landscape, businesses encounter a number of different challenges. One of them is to do analytics on top of unified and harmonized data layer available to all the consumers. A layer that can deliver the same answers to the same questions irrelative to the dialect or tool being used.
In the previous article we presented the d[IA]gnosis application developed to support the coding of diagnoses in ICD-10. In this article we will see how InterSystems IRIS for Health provides us with the necessary tools for the generation of vectors from the ICD-10 code list using a pre-trained language model, its storage and the subsequent search for similarities on all these generated vectors.
The invention and popularization of Large Language Models (such as OpenAI's GPT-4) has launched a wave of innovative solutions that can leverage large volumes of unstructured data that was impractical or even impossible to process manually until recently.
We have a yummy dataset with recipes written by multiple Reddit users, however most of the information is free text as the title or description of a post. Let's find out how we can very easily load the dataset, extract some features and analyze it using features from OpenAI large language model within Embedded Python and the Langchain framework.
Continuing with the series of articles on voice file management, we are going to see how we can convert text into audio and receive the file with the chosen voice. We will also explore how a service from OpenAI can help us analyze a text and determine the mood expressed in it. Let's analyze how you can create your own voice file and how it can “read” your feelings.
 By update
By update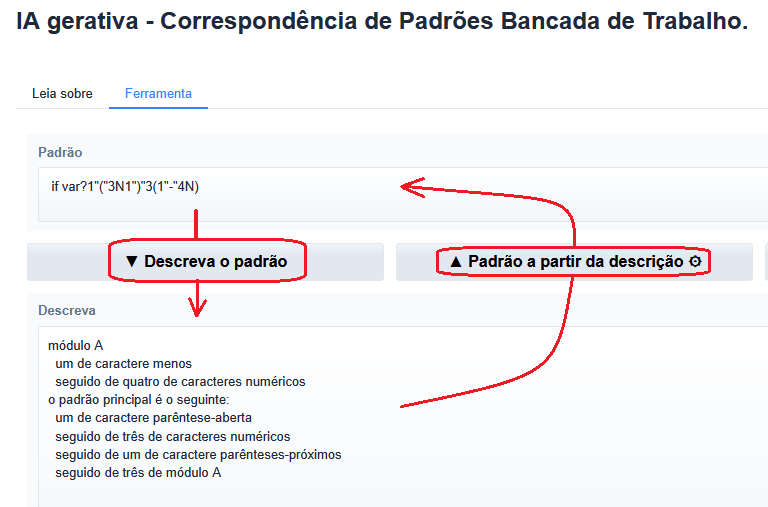
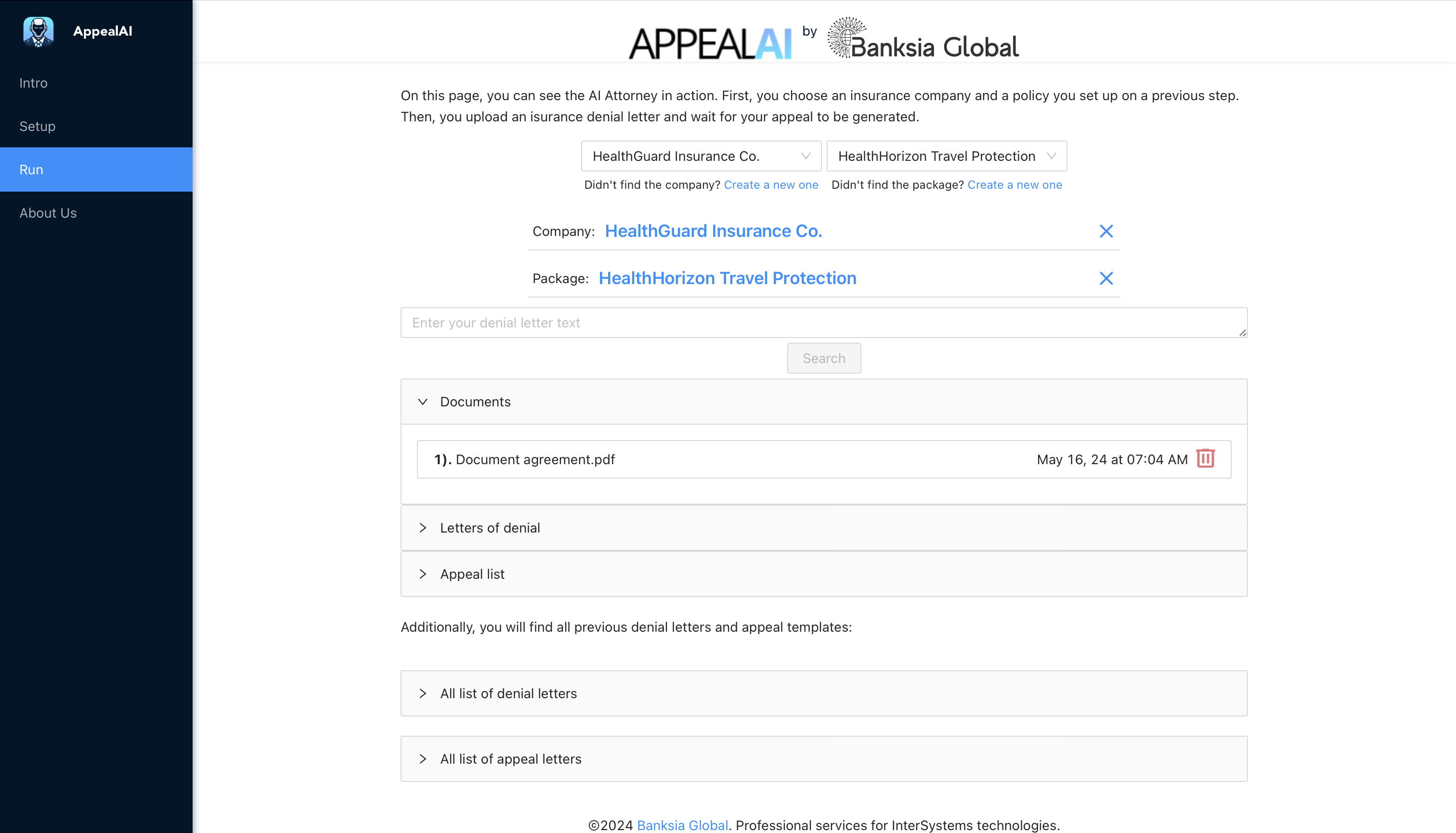
 Open Exchange app
Open Exchange app


.png)


.png)


.png)
.png)

.png)
