As you know in Caché / IRIS you have the possibility to define a property as Multidimensional as documented here:
https://docs.intersystems.com/iris20201/csp/docbook/DocBook.UI.Page.cls?KEY=GOBJ_proplit#GOBJ_proplit_multidim
and the explanation of how to use it
https://docs.intersystems.com/iris20201/csp/docbook/Doc.View.cls?KEY=GOBJ_proplit#GOBJ_proplit_multidim_values
Though the access is quite comfortable (in traditional COS sense) there are 2 main restrictions that hurt:
#1) It is not saved to disk unless your application includes code to save it specifically.
#2) It cannot be stored in or exposed through SQL tables
there are some more
I'll show how to overcome these limits
 Jupyter Notebook is an interactive environment consisting of cells that allow executing code in a great number of different markup and programming languages.
Jupyter Notebook is an interactive environment consisting of cells that allow executing code in a great number of different markup and programming languages.
To do this Jupyter has to connect to an appropriate kernel. There was no ObjectScript Kernel, that is why I decided to create one.
You can try it out here.
Here's a sneak peek of the results:

Jupyter Kernels 101
There are several ways to create a Jupyter Kernel. I decided to make a Python wrapper kernel.
We have to create a subclass of ipykernel.kernelbase.
What is the OData
OData (Open Data Protocol) is an ISO/IEC approved, OASIS standard that defines a set of best practices for building and consuming RESTful APIs. OData helps you focus on your business logic while building RESTful APIs without having to worry about the various approaches to define request and response headers, status codes, HTTP methods, URL conventions, media types, payload formats, query options, etc. OData also provides guidance for tracking changes, defining functions/actions for reusable procedures, and sending asynchronous/batch requests (source: OData.org).
Over the past year or so, my team (Application Services at InterSystems - tasked with building and maintaining many of our internal applications, and providing tools and best practices for other departmental applications) has embarked on a journey toward building Angular/REST-based user interfaces to existing applications originally built using CSP and/or Zen. This has presented an interesting challenge that may be familiar to many of you - building out new REST APIs to existing data models and business logic.
Say I have an ObjectScript object called Book. It has 2 properties title and author. It extends JSON.%Adaptor, so I can call book.
If you need write your organization Data Architecture and map to the InterSystems IRIS, consider following Data Architecture Diagram and references to the intersystems iris documentation, see:
.png)
Architecture mapping:
- SQL Database: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GSQL
- Managed Files: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=AFL_mft and https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=SETEDIGuides
- IoT Broker, Events and Sensors: https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?
Hi Devs!
Last weekend I had been testing the newborn csvgen module and was looking for a CSV file to test - thus I came across an interesting datafile on Data.World with Game of Throne episodes statistics. Death statistics. These folks documented all the murders through all the 8 seasons and noted where, who, from what clan with what weapon had killed another one.
So I imported it and made an IRIS Analytics dashboard.

Don't worry, Jon, with this dashboard we can figure out something ). See the details below.
Hi Developers!
Suppose you have a persistent class with data and you want to have a simple Angular UI for it to view the data and make CRUD operations.
Recently @Alberto Fuentes described how to build Angular UI for your InterSystems IRIS application using RESTForms2.
In this article, I want to tell you how you can get a simple Angular UI to CRUD and view your InterSystems IRIS class data automatically in less than 5 minutes.
Let's go!
Inter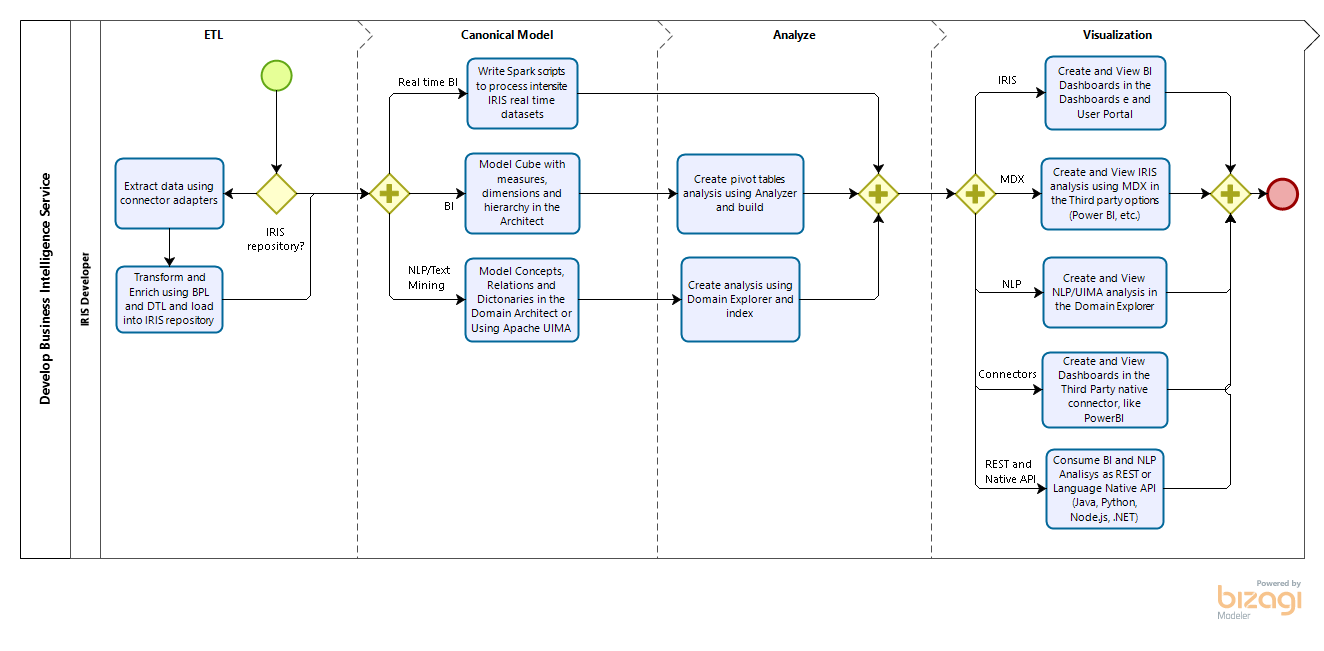
Intersystems IRIS is a complete platform to get insights from SQL and NoSQL data. It is possible get data from Interoperability adapters or using a set of IRIS tables as data sources and model BI or NLP Cubes, covering all type of data (other tools are limited to SQL). There are the option to enable intensive analytics processing using Spark too. So you can model your analysis using IRIS web analyzers (many tools use desktop tools) and than visualize and produce insights using IRIS Dashboards and IRIS User Portal or your third party options, using open options like MDX and REST.
Currently, the process of using machine learning is difficult and requires excessive consumption of data scientist services. AutoML technology was created to assist organizations in reducing this complexity and the dependence on specialized ML personnel.
AutoML allows the user to point to a data set, select the subject of interest (feature) and set the variables that affect the subject (labels). From there, the user informs the model name and then creates his predictive or data classification model based on machine learning.
This is my introduction to a series of posts explaining how to create an end-to-end Machine Learning system.
Starting with one problem
Our IRIS Development Community has several posts without tags or wrong tagged. As the posts keep growing the organization of each tag and the experience of any community member browsing the subjects tends to decrease.
First solutions in mind
We can think some usual solutions for this scenario, like:
- Take a volunteer to read all posts and fix the mistakes.
- Pay a company to fix all mistakes.
- Send an email to each post writer to review the texts from past.
This is the third post of a series explaining how to create an end-to-end Machine Learning system.
Training a Machine Learning Model
When you work with machine learning is common to hear this work: training. Do you what training mean in a ML Pipeline? Training could mean all the development process of a machine learning model OR the specific point in all development process that uses training data and results in a machine learning model.

So Machine Learning Models are not equal Common Applications?
In the very last point it looks like a normal application.
I'm working with clients planning migrate from Caché to IRIS and I want to summary advantages to go to IRIS. I think is:
- IntegratedML - AutoML - Agile machine learning
- IAM - InterSystems API Manager
- Interoperability
- Advanced Reports (JReport)
- Cloud Manager/Docker and DevOps support
- ZPM - Package manager
- Native API - Node.js, Python, Java and .NET interoperability
- Core based license x user based license
- InterSystems Support and new features
- Improved management and monitoring features
Can you help me to think or detail these 10 topics?
In most cases, a global used by default storage has just 1 subscript level that represents the IDKEY.
For an index-globals we may see 2 or more subscript levels.
Arrays, or parent-child relationships or persistent classes extending a base data class
are examples where we see more levels. Though all these globals are quite uniform.

PDF version: https://github.com/yurimarx/iris-periodic-table/raw/master/periodic%20table%20iris.pdf
GIT sources: https://github.com/yurimarx/iris-periodic-table
InterSystems IRIS is a Data Platform with a lot of features. These features and relevant topics about IRIS is represented in the periodic table elements.
I am pleased to announce the availability of InterSystems Container Registry. This provides a new distribution channel for customers to access container-based releases and previews. All Community Edition images are available in a public repository with no login required. All full released images (IRIS, IRIS for Health, Health Connect, System Alerting and Monitoring, InterSystems Cloud Manager) and utility images (such as arbiter, Web Gateway, and PasswordHash) require a login token, generated from your WRC account credentials.
While the integrity of Caché and InterSystems IRIS databases is completely protected from the consequences of system failure, physical storage devices do fail in ways that corrupt the data they store. For that reason, many sites choose to run regular database integrity checks, particularly in coordination with backups to validate that a given backup could be relied upon in a disaster. Integrity check may also be acutely needed by the system administrator in response to a disaster involving storage corruption.
It seems to me that for some reason this didn't make its way to the official documentation
and seems to be rather unknown though implemented already in IRIS 2020.1
Thanks to @Dan Pasco I got a hint on the classes involved.
I used the recommended sequence of how to use it.
it is all directly taken from Class Reference and I just collected it to create a first overview.
Doing a new project with %JSON.Adaptor, unexpectedly realized that %JSON.Adaptor does not support export to native JSON. %JSONExport just outputs directly to the current device, and there are two more methods %JSONExportToString, and %JSONExportToStream.
In conjunction with generating REST from swagger specification, where any generated method accepts as a result %DynamicObject, which is good.
I have multiple places in my REST where I have to return JSON for an object, but I have to modify the result a bit, just extend it with some other way.
FHIR Terminology Service specification describes a set of operations on CodeSystem, ValueSet and ConceptMap resources. Among those operations, the following four operations appear to be the most widely adopted ones:
| CodeSystem | ValueSet |
|---|---|
| $lookup $validate-code |
$expand $validate-code |
Developing a partial implementation of the specification has been an effective way to explore the new FHIR framework introduced in IRIS for Health 2020.1. The implementation includes four operations listed above, and supports read and search interactions for CodeSystem and ValueSet resources.
It's important to note that the implementation uses plain ObjectScript persistent classes as source terminology tables.