Hi @Myles Collins !
My question is more on new version deployments, which need schema changes and data conversion
- Log in to post comments
Hi @Myles Collins !
My question is more on new version deployments, which need schema changes and data conversion
Yes! This community :)
My personal biggest problem with %JSON.Adaptor that property names are case sensitive. That causes regular "why doesn't it working" while interactions with frontend.
Hi @Aziz Cotrim !
I know at least one extension of %JSON.Adaptor like isc.json by @Timothy Leavitt that helps e.g. with %List type JSON nesting and providing RowIDs which %JSON.Adaptor lacks. Perhaps there are more useful features that could all be found here.
How can developers try CCR?
Thank you, Yuri! Looks interesting!
Thanks @Ben Spead !
Should the conversion be written by a developer or there is some automation?
Do you have also a backward mechanism to "undone"/"convert back" the changes?
Try 'load' command instead of 'install'
Thank you, @David Hockenbroch !
It is not obvious at all.
There is a very interesting extension to this "feature" by @Vasiliy Bondar that allows navigation for non-unique-indexed properties as well.
@Thomas Dyar this is amazing! Do you want to share the skill on https://openexchange.intersystems.com?
It's OpenAI, currently) So, in addition to "thank you" for every good move I'll add "I'm sorry" :)
also empty records and csv export were introduced
Here is a small Loom video on how it works
if you want to play with test data there are several dataset apps, like the medical dataset from @Muhammad Waseem or the Health Dataset from @Yuri Marx
Hi @Jacinto Busquets !
I think your request is interesting, and I spent a vibecoding evening to introduce a sample that can help with the task.
So I've built a backend on IRIS that goes through persistent classes in a namespace and provides stats on the columns of every class how are they filled. And built a frontend for it. Here is the demo server:
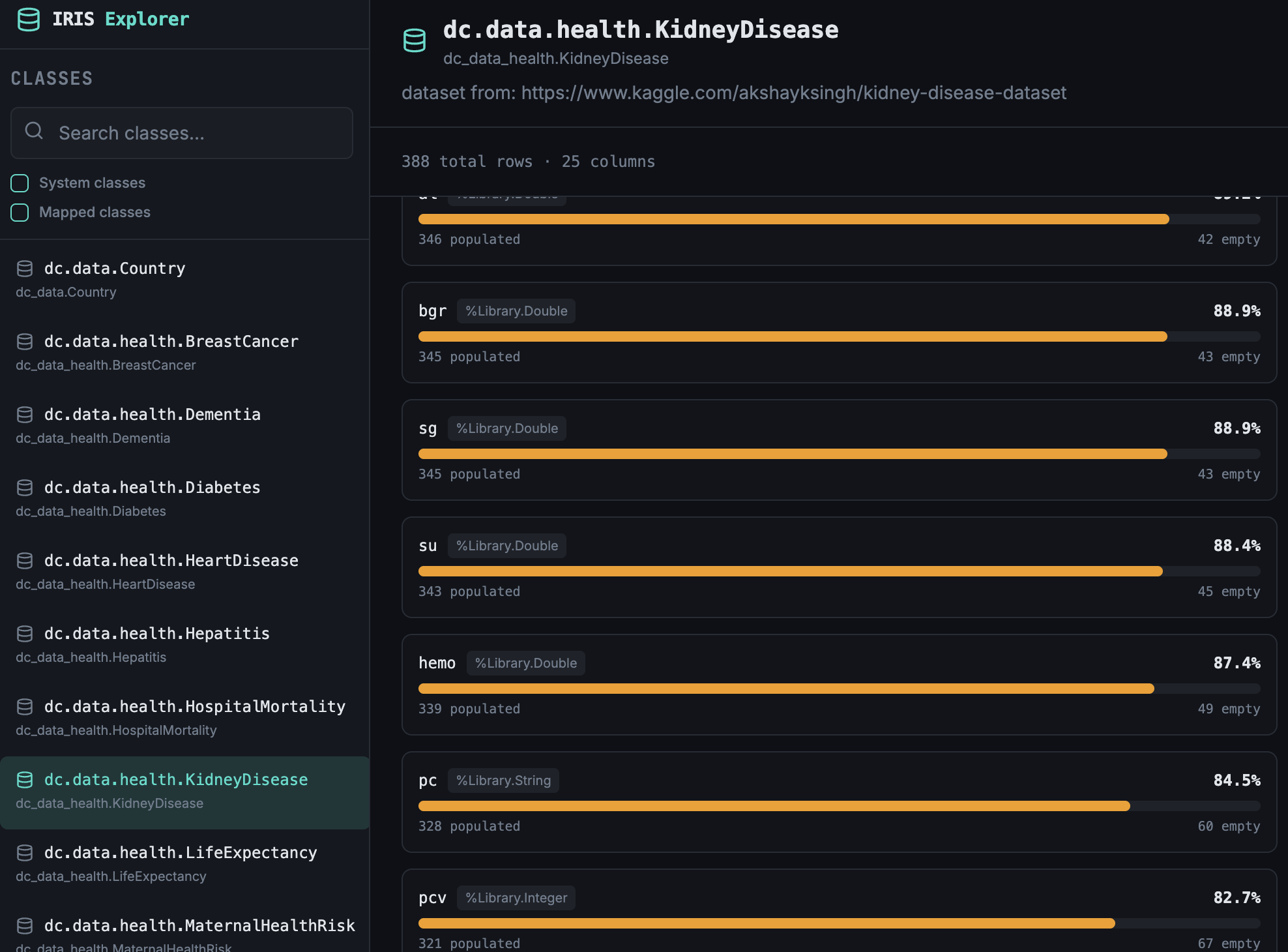
How to have it on your own server:
you should have IPM client installed, and then do:
USER> zpm "install iris-table-stats-frontend"
and
USER>zpm "install esh-iris-table-stats"
and open the UI at /iris-table-stats-ui/index.html endpoint of your IRIS server.
Wow. There are really many applications! Thank you, @Eduard Lebedyuk
Second for Codex with ObjectScript too! Plus a relevant Agent.md :)
Yes, every day - GPT-Codex and Claude Code.
Hi @Raef Youssef !
Thanks for sharing! But where is the app? May I try it on my local IRIS?
Great stuff, @Guillaume Rongier !
Could you please also publish at https://openexchange.intersystems.com ?
It's not a matter of ResultSet availability in another namespace; it's a matter of the data you have access to in one namespace and not in another.
if you need the access to data that is available in namespace A to namespace B, there are many ways to make it work:
But reconstructing the ResultSet, which is just an object in memory suitable to access the data that is still in Namespace A, I wouldn't follow the idea.
Well deserved, @Ashok Kumar Thangavel ! Thanks to all your contributions to this community!
Glad to see more ideas find its solutions! Thanks a lot to everyone involved!
Sure, @Flávio Lúcio Naves Júnior ! Glad you like it!
Also, never name the classmethod in disp or impl Login() or login() - it compiles, but the IRIS CSP/REST-API engine doesn't work with such names - it seems they are reserved ones.
Thank you, @Tani Frankel !
Very useful, didn't know that there was an SQL access to ^%ISCLOG
Also, make sure you DON'T change the method nomenclature in the impl class - spec compilation will change it (not touching the methods' implementation, though). It can cost you some time to investigate what's going on, as this will appear in the deployment phase only.
e.g. consider method in the impl class:
Classmethod foo (bar as %String) as %Status {
if bar="" write "bar is empty."
return $$$OK
}If you change nomenclature, e.g. introduce the default value
Classmethod foo (bar as %String ="" ) as %Status {
if bar="" write "bar is empty."
return $$$OK
}It will work on a dev stage, and you will have class with a default value in your GitHub repository, but once the solution is deployed, the spec file compilation will change the nomenclature back to the original "without default" stage, as it is stated according to specs:
Classmethod foo (bar as %String ) as %Status {
if bar="" write "bar is empty."
return $$$OK
}Thanks for sharing, @Lorenzo Scalese!
"Oh my god!" Thanks for sharing @Steven Hobbs !
And thanks god we don't have a need to use goto anymore, as it is quite a legal way to shoot yourself in both feet.