The forth in the trilogy, anyone a Hitchhikers Guide to the Galaxy fan?
If you are looking to breathe new life into an old MUMPS application follow these steps to map your globals to classes and expose all that beautiful data to Objects and SQL.
If the above does not sound familiar to you please start at the beginning with the following:
So, I played with row level security and was unable to find a way to get to work it dynamically. I want to determine if the user can access the row in runtime based on a state of external system, but it seems that row level access is calculated during INSERT/UPDATE and stored in %RLI index. Is there a way to achieve runtime access calculation?
The purpose of this post is to ask for everyone's thoughts and input around the use of transient, SQLCalculated/Computed properties within persistent classes.
This approach allows for extra data values needed in SQL queries to be available without having to join to other tables.
Very simple/basic example to illustrate the topic:
Let's say I have a persistent class named ICDAutoCodeDefn to hold ICD Auto-Coding definitions, such as:
If you are looking to breathe new life into an old MUMPS application follow these steps to map your globals to classes and expose all that beautiful data to Objects and SQL.
If the above does not sound familiar to you please start at the beginning with the following:
I have a class which defines a property as array of %String. Is it possible to index values of this property and use this property in SQL?
I have tried 'Index idx On prop(ELEMENTS)' and then a select from the generated collection table, but this is still orders of magnitude slower than queries to the containing class.
I would like to integrate SQL into our ObjectScript routines in order to illustrate how SQL can be used to minimize development time. However, there are two questions I have.
How does one iterate through the results of a SELECT statement?
I get this on some queries in some namespaces. For instance, this query:
SELECT TOP 10 SessionId, datediff(s,min(TimeCreated),max(TimeCreated)) as ResponseTime FROM ens.messageheader GROUP BY SessionId ORDER BY ResponseTime DESC
It works fine in HSBUS but in HSREG it throws the error.
Server closed communication device
Does anyone know what would cause this? Would it log something more useful somewhere?
perhaps i have the possibility of Deleting all history queries, but i think better to check the table where last queries were stored and solve it by deleting wrong registries. anybody knows where is the table 'QueryHistory'.
Since now i have been working from external connection but i want to work with the SQL utility of Management Portal
i dont know how to do with several instructions like in other editors like this example
update Prod.Articulos set Alto = 1646, Ancho = 16, Fondo = 80 where CodigoNum = '100' and Empresa = 'CO'
update Prod.Articulos set Alto = 1646, Ancho = 16, Fondo = 400 where CodigoNum = '101' and Empresa = 'CO'
update Prod.Articulos set Alto = 1646, Ancho = 16, Fondo = 400 where CodigoNum = '102' and Empresa = 'CO'
As we all know, Caché is a great database that accomplishes lots of tasks within itself. However, what do you do when you need to access an external database? One way is to use the Caché SQL Gateway via JDBC. In this article, my goal is to answer the following questions to help you familiarize yourself with the technology and debug some common problems.
Embedded SQL is a tool that allows us to execute SQL statements in Caché Object Script. For example, to select the name of a person with a particular SSN from the Sample.Person class we can do the following:
Running TuneTable accounts among other the parameter named Block Count. In documentation, we see that this is an approximate numbers of 2K-blocks in which SQL-maps are stored. Databases in recent Cache doesn't support 2K-physical blocks so SQL-blocks are not physical blocks as it seems. So two questions:
- what are these blocks?
- how knowledge about count of blocks can help in SQL optimization?
Beginning in Caché 2013.1, InterSystems introduced Outlier Selectivity to improve query plan selection involving fields with one atypical value.
In this article, I hope to use an example 'Projects' table to demonstrate what Outlier Selectivity is, how it helps SQL performance and a few considerations for writing queries.
I've asked a lot of questions leading up to this, so I wanted to share some of my progress.
The blue line represents the number of messages processed. The background color represents the average response time. You can see ticks for each hour (and bigger ticks for each day). Hovering over any point in the graph will show you the numbers for that period in time.
This is super useful for "at a glance" performance monitoring as well as establishing patterns in our utilization.
I have a general query in regards to developers experience on extracting data from cache databases and the most efficient way to do so. I work with a number of clients who have applications with cache databases and require the data off the host system and onto data warehouse platforms for research and analysis. Often they require the data in source state which means the extracts are often simply a table scan of the entire database table without any aggregation or manipulation.
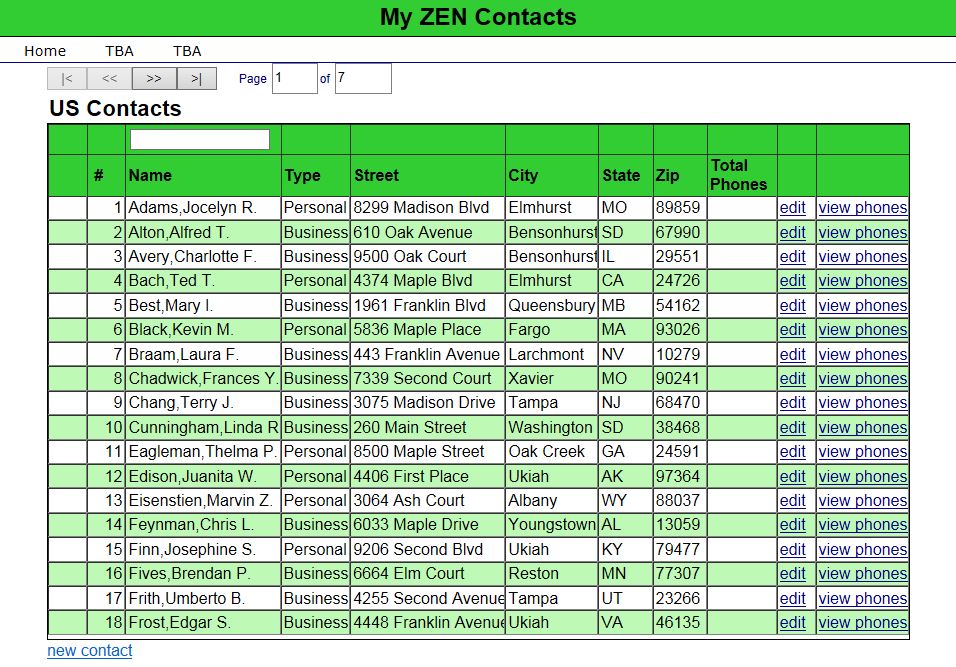
I have been following the online Zen Quickstart Tutorial using the lastest release documentation. In addition to playing around with the styling and making a few minor functionality tweaks, I wanted to add an additional column that shows a count of the number of phone numbers for that Contact (as shown in the image below).
I have a list of about 100 MPI IDs that I would like to run a report on. I want to list times that any data for these patients were accessed. Currently in "Managed Reports" we have a "Disclosure Report" which I think was a custom development effort, but it is per-patient.
I have a SQL query for the ATNA log but I'm not confident in its accuracy, so I thought I'd reach out and see how other Information Exchange's might get this data.
 By date
By date