 By replies
By replies
 Open Exchange app
Open Exchange app# IRIS-Intelligent Butler
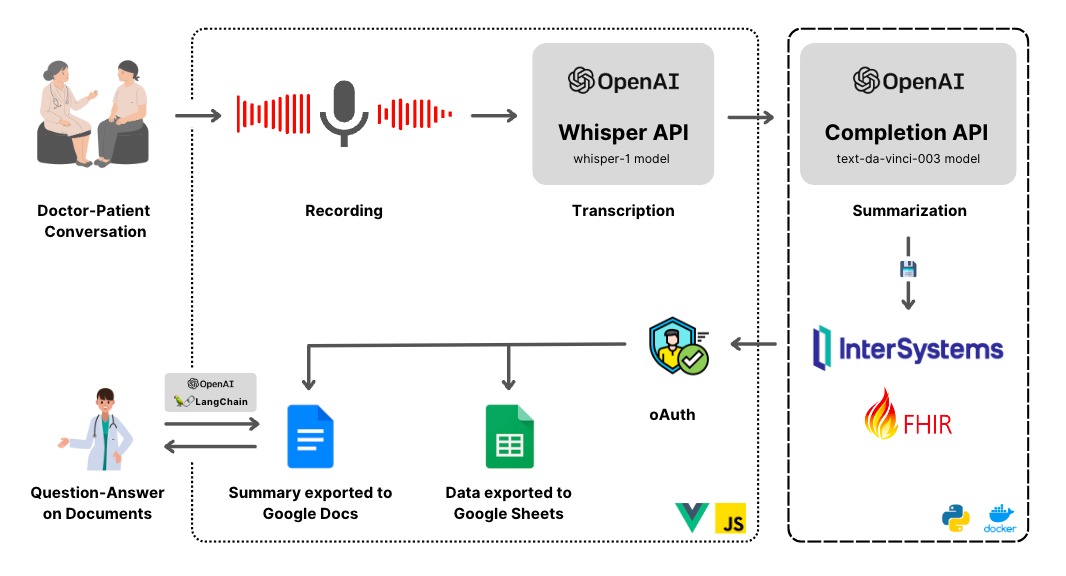
IRIS Intelligent Butler is an AI intelligent butler system built on the InterSystems IRIS data platform, aimed at providing users with comprehensive intelligent life and work assistance through data intelligence, automated decision-making, and natural interaction.
## Application scenarios
adding services, initializing configurations, etc. are currently being enriched
## Intelligent Butler



.png)

.png)
.png)
.png)