Using AI to Simplify Clinical Documents Storage, Retrieval and Search
Problem
In a fast-paced clinical environment, where quick decision-making is crucial, the lack of streamlined document storage and access systems poses several obstacles. While storage solutions for documents exist (e.g, FHIR), accessing and effectively searching for specific patient data within those documents meaningfully can be a significant challenge.
Motivation
AI has made document search remarkably powerful. Question and answering over docs has never been easier with open-source tools like Chroma and Langchain to store and use vector embeddings to query across Generative AI APIs. With more dedicated effort, organizations are indexing their existing documents and building fine-tuned versions of GPT for enterprise purposes. Andrej Karpathy’s talk on State of GPT provides an excellent overview on this topic.
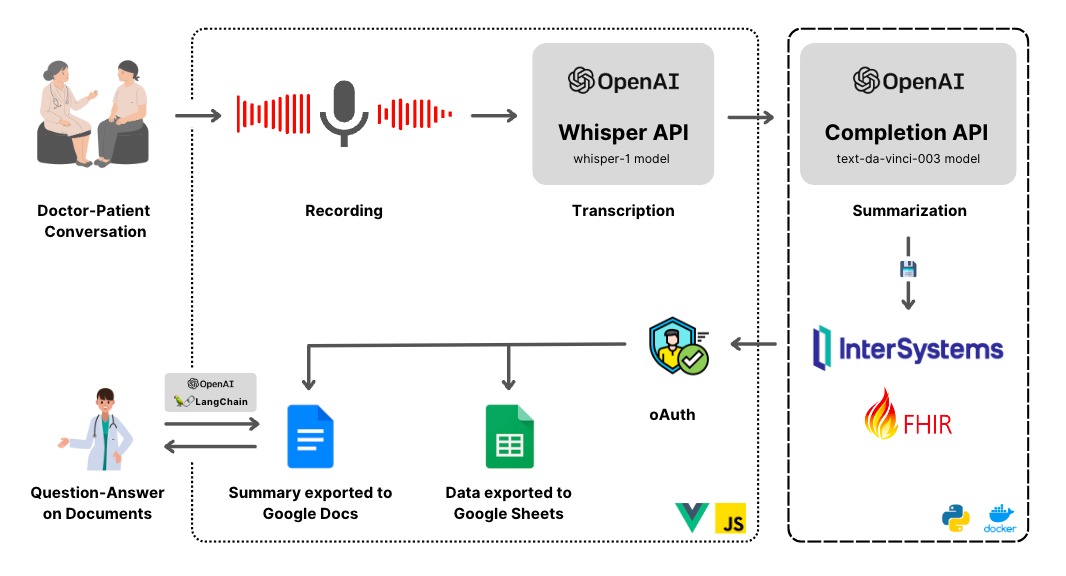
This project was our attempt at trying to reduce friction across all touch points where a clinician might interact with documents. From input and processing to storage and retrieval, we’ve leveraged IRIS FHIR and AI to make help store and find the information they need effortlessly.
Solution
We’ve built a full-stack web-app that allows clinicians to record voice notes. These notes can then be transcribed and summarized using Open AI and stored into FHIR servers. The stored documents are then indexed and made available for semantic search.
Demo Video
Key Features
- Web app - To view clinical information about patients, observations and encounters. This is built using Vue.js.
- Voice transcription - Open AI Whisper API is used to transcribe voice recordings accurately to text.
- Text summarization - The transcribed content can then be summarized and given a title in the required format. Like specific sections like symptoms, diagnosis, and so on. This is achieved using Open AI text completion API using the text-da-vinci-003 model.
- Document storage - The summarized documents are then stored in FHIR using the Document Reference artifact.
- Semantic document search - The stored documents are indexed and stored in Chroma as chunks. This is then used to limit the search space and use GPT tokens sparingly for semantic search using Langchain. Currently, we load the documents at the time of search due to the smaller number of documents available. This can be modified to index in the background in an async manner.
- Documents export - Finally, there is an option to export documents to Google Docs and other data to Google Sheets. Users can log in with their specific accounts using OAuth and export the documents for easier collaboration and communication with other clinicians or patients.
Try it out
Clone the project repository from the following GitHub link: https://github.com/ikram-shah/iris-fhir-transcribe-summarize-export. Follow the provided instructions to set up the project locally on your machine. Let us know if something doesn’t work as expected.
Thoughts and Feedback
Advanced language models available today combined with the massive volume of data available hold immense potential to revolutionize healthcare, especially in the documents space. Let us know your thoughts and any feedback below. We will follow up with more posts on the technical details behind this project.
Vote for our app in the Grand Prix contest if you find it promising!