Hi All,
I'm starting to use VSCode for most of my day to day stuff and there's something that has me stumped. Is there a way to override a method or property that's inherited from a superclass?
Hi All,
I'm starting to use VSCode for most of my day to day stuff and there's something that has me stumped. Is there a way to override a method or property that's inherited from a superclass?
When the started service component cannot be shut down correctly in the foreground, can you terminate the service by ending the task manager process? Will it affect the correct operation of the system
Episode 16 of Data Points features a conversation with Jeff Fried — Director of Product Management for Data Platforms at InterSystems — about what it means for InterSystems to have been named a visionary in Gartner's first-ever magic quadrant for Cloud Database Management Systems.
Hello fellow community members,
I would like to offer my services as an Intersystems Professional and am available to work on projects.
I have more than a decade experience into Intersystems stack of technologies including IRIS, Ensemble, Healthshare, Healthconnect, Cache Objectscript, Mumps, Zen, Analytics etc. with companies spread over US and UK involved in multiple domains.
How set (studio) drak theme?
There is no prompt for studio to write code
Hello,
We would need some help, please;
We would like to handle when we have a date with hours:
20201204090000
And when we have it without the hours part, as follows:
20201204
For the first case we used:
##class(Ens.Util.Time).ConvertDateTime(source.{ORCgrp(1).RXA:DateTimeStartofAdministratio},"%Y%m%d%H%M%S","%d/%m/%Y",,.tSC)For the second one we wrote:
##class(Ens.Util.Time).ConvertDateTime(source.{ORCgrp(1).RXA:DateTimeStartofAdministratio},"%Y%m%d","%d/%m/%Y",,.tSC)However each way only works for one case
How could we handle both cases with just a line of code?
We have read:
Hi Developers!
Here're the technology bonuses for the InterSystems Multi-Model Contest that will give you extra points in the voting:
See the details below.
The server activity and duration can query the message volume of a certain day or period according to the specified time. At the same time, it can query and count the message volume of BS service, BP service and Bo service by modules
Hi folks!
Just a very short note on if you want to add a cute Open Exchange shield like this:

in your GitHub repo you can do it by entering one line like this:
[](https://openexchange.intersystems.com/package/csvgen)
In the URL place the path to your OEX page.
Thanks to the participants of contest for such a neat shield )
What other helpful Github shields do you know? Please share in the comments?
编码中,zn “命名空间”这样跨命名空间使用操作会导致队列中具有很多 _sync:进程号,不知道这种情况是切换命名空间操作的问题还是使用的问题?对于这种跨命名空间有没有更好的应用方式?
In coding, the operation of Zn "namespace" across the namespace will lead to a lot of errors in the queue_ Sync: process number. I don't know if this is a problem of switching the namespace operation or using it? Is there a better way to apply this kind of cross namespace?
Hi,
I am very much a newbe on the subject of JWT, so please except my ignorance.
The Trust I am currently working for wish to create a framework whereby they can create REST API Services, within HealthConnect, and grant access to these using JSON Web Token Authorisation and Bearer Tokens. This would be similar to the way the Trust currently connects to other REST API's, i.e.: DocMan Connect and GOV.UK Notify.
Can anyone offer any advice / sample code and / or point me into the direct of suitable documentation to achieve this?
Hi colleagues!
Every day Johns Hopkins University publishes new data on coronavirus COVID-19 pandemic status.
I built a simple InterSystems IRIS Analytics dashboard using InterSystems IRIS Community Edition in docker deployed on GCP Kubernetes which shows key measures of the disease outbreak.
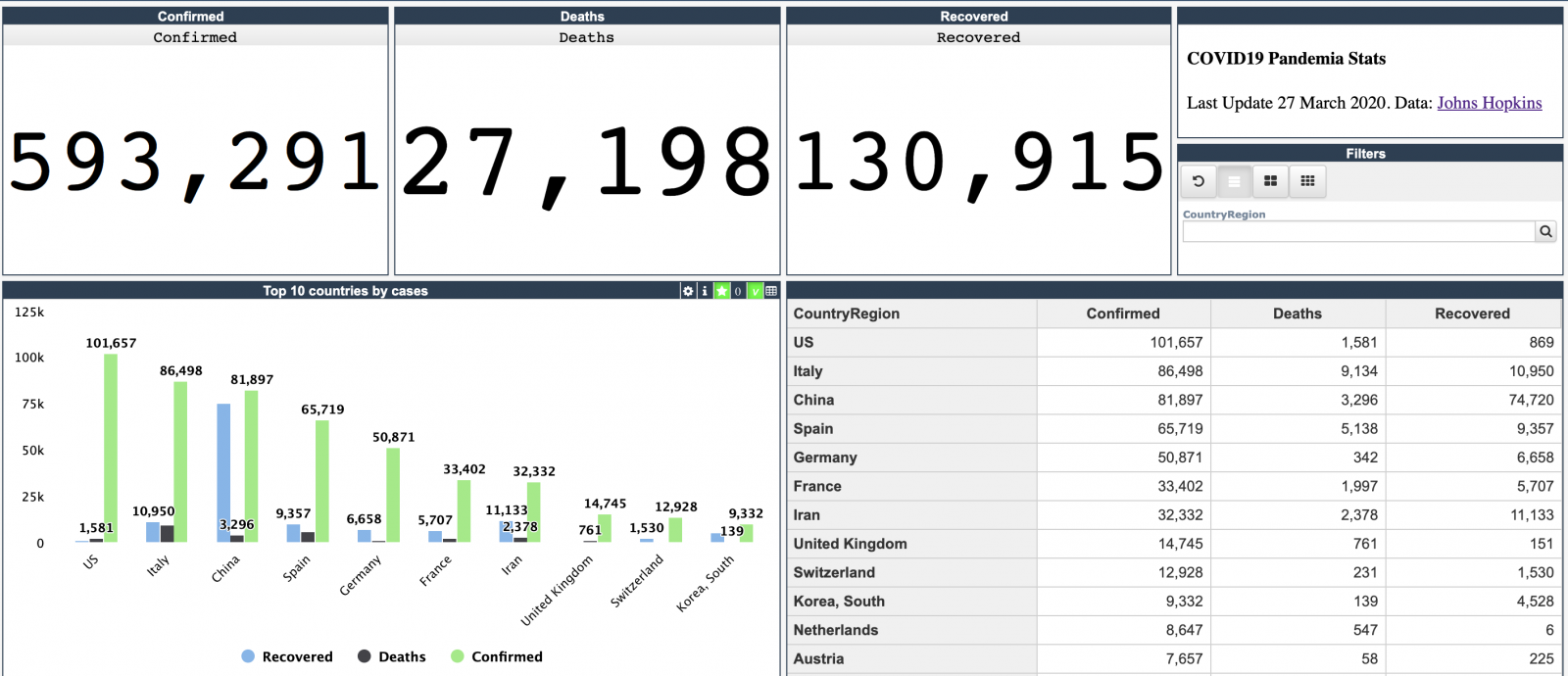
This dashboard is an example of how information from CSV could be analyzed with IRIS Analytics and deployed to GCP Kubernetes in a form of InterSystems IRIS Community Edition.
Added the interactive map of the USA:
Hello everyone :-)
I would like to grant access to the Event Log (below in French "Journal des événements") to a user, and more generally to an existing group of users (this group is named "Helpdesk").
Helpdesk has already access to the following tables:
.png)
...But still the Event Log remains inaccessible:
I see that the error message is about "SQL privileges" and indeed the Helpdesk group has no one for now. But it does not look familiar to me. Here is below those privileges that some other user (which has access to the Event Log) has got:
Artificial intelligence has solved countless human challenges – and medical coding might be next.
As organizations prepare for ICD-11, medical coding is about to become more complicated. Healthcare organizations in the United States already manage 140,000+ codes in ICD-10. With ICD-11, that number will rise.
Some propose artificial intelligence as a solution. AI could aid computer-based medical coding systems, identifying errors, enhancing patient care, and optimizing revenue cycles, among other benefits.
Hi Community,
In the past, technical documentation of the source code and software products was generated in chm, pdf files and documentation generators of the programming languages themselves. This old approach had the following limitations:
1. Outdated documentation;
2. Non-interactive and difficult to consult documentation;
3. Layout unresponsive, unfriendly and not adherent to HTML;
4. Inability to customize the layout of the documentation;
5. Inability to have HTML 5 documentation online and offline.
6. Lack of Markdown support.
Currently running on limited hardware, Online Backups are becoming a bottleneck for our system.
For now, we are exploring an option to backup individual databases, or groups of them, thus reducing RAM requirements per individual backup task. To do that, however, we'd need a separate Backup List for our Backup Tasks. We did not find an option to do so in web portal, so currently we are looking at inheriting from system backup tasks and Backup.General classes to generate Backup List before backing up and then performing the backup as normal.
Is this approach feasible?
Hi,
I don't like the default terminal very much because it can't change the window size freely.
How to use CMD or PowerShell?
Hi everyone, do you have any idea how to find this error or the meaning of this error
Hi Community,
Please welcome the new video on InterSystems Developers YouTube:
Developer Community: Help us help you!
We are trying to better understand how our users navigate through the Learning site. Would you like to share your thoughts?
If you're willing to participate in an in-depth interview over WebEx about your experiences, please fill out this quick survey by Feb 26, and you might be eligible for a Visa gift card! Indicate in the survey that you'd like to talk to us and we will be in touch soon!
Feedback from real users like you in invaluable to us and helps us create a better product.
Thank you so much! If you have any questions, contact me at michelle.spisak@intersystems.com.
Hi,
I need to create a Business Service that connects too and processes emails via IMAP.
Has anyone done a similar task and if so, can they provide advice?
There is inbuilt support for POP3 (POP3 adapter) but not for IMAP.
Thanks.
Anthony Breen
1) Does web service access consume license?
2) In web service program, we used a connection pool to reuse the session id, but it doesn’t work, the license consume increased quickly, it seems connection pool didn’t work, do you have any sample to do it?
Hello everyone!
I'm new with cache and I wold like to know if I can integrate cache with node.js and how I can do this?
Hi:
I'm looking for some help with JSON notation for a global structure. I need a way to represent a global structure in JSON where the global structure both has a value at a given node as well as sub-nodes.
Built in multi model integration using InterSystems iris data platform
Solution of hospital information inquiry business
Integration of hospital information query business solutions using InterSystems IRIS data platform with built-in multiple models
### Summary:
With the gradual improvement of hospital information construction, there are more and more hospital subsystems, and more and more interfaces between systems. At the same time, the interface cost is increasing, and the management work is becoming more and more complex.
Hi,
I'm a novice. I don't know much about object script. Can he write an(Windows10) EXE file?
I've been trying to figure out how to use an ObjectScript class to search other classes for specific strings. To be very specific, I want to be able to search business rules to see if a particular DTL is in the rule. We have some orphaned DTL's in our Ensemble productions and I want to make sure that they're not being used.
Thanks.
Hi:
I've looked on many of these examples and questions how to post the JSON body but all the posts are a little complexly worded for me to follow.
so i have an EnsLib.REST.Operation
The example in ENSDEMO Directory Request says
Set tSC=..Adapter.PostURL(tURL,.tHttpResponse,"",pRequest.Body)
What i can't see is how in Demo Rest Directory request it happens to get the value of the message fields into
/// For JSON content submission
Property Body As %GlobalCharacterStream;

