.png)
ISC Developers, I 👑 you.
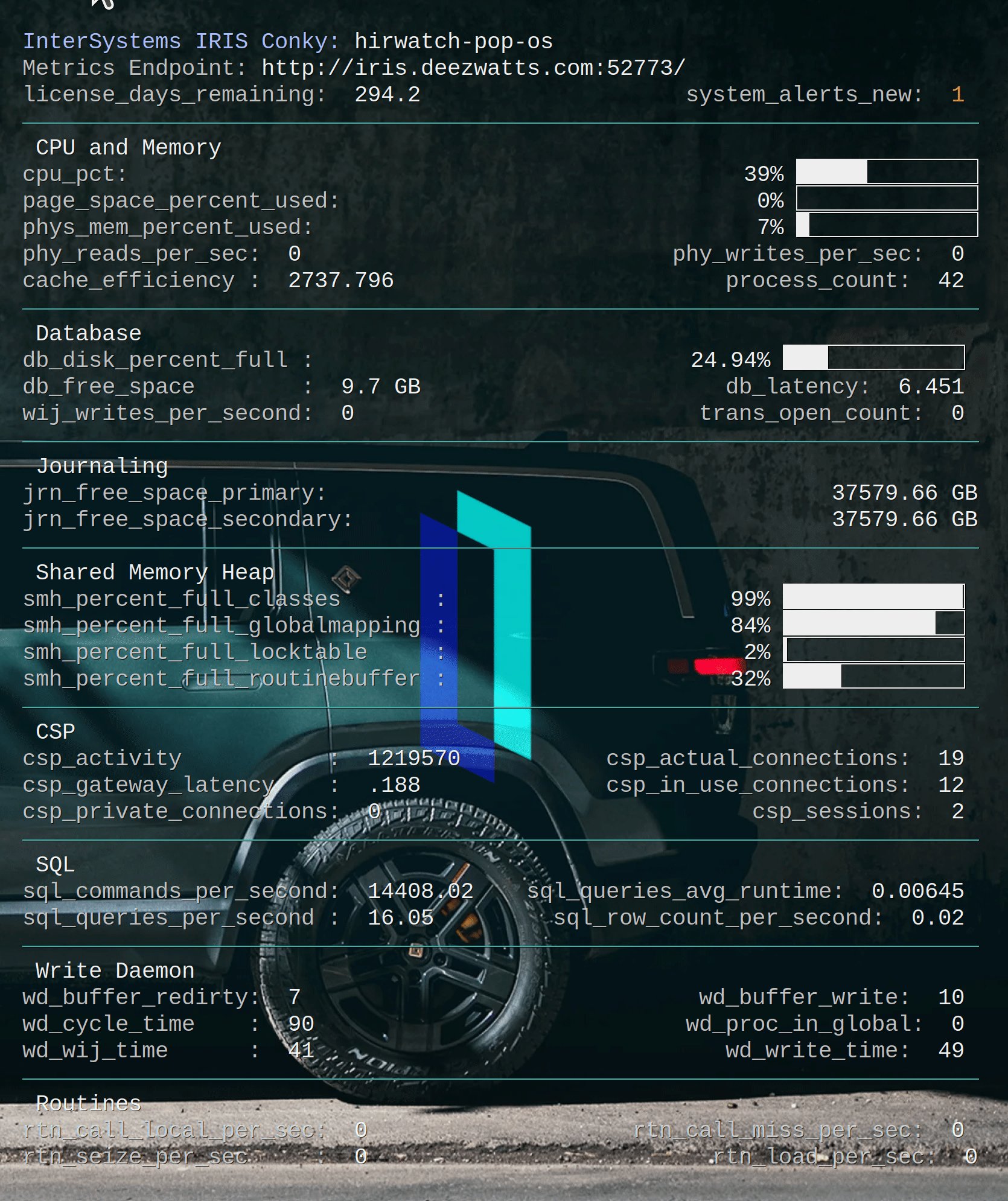
Have written several worthless Conky's in my day, and this one is no exception, but it was fun.
.png)
IRIS makes SIEM systems integration simple with Structured Logging and Pipes!
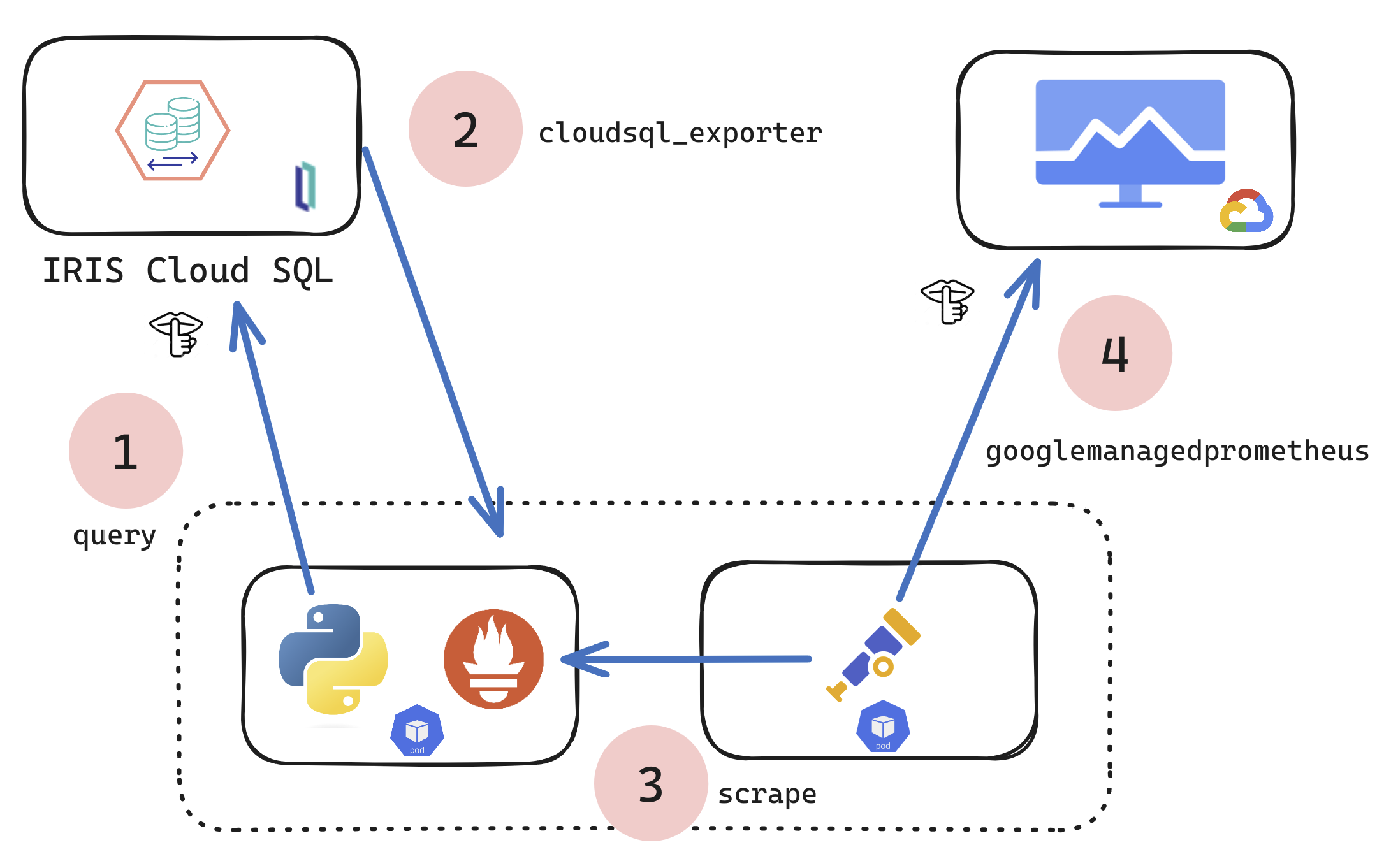
If you are a customer of the new InterSystems IRIS® Cloud SQL and InterSystems IRIS® Cloud IntegratedML® cloud offerings and want access to the metrics of your deployments and send them to your own Observability platform, here is a quick and dirty way to get it done by sending the metrics to Google Cloud Platform Monitoring (formerly StackDriver).
K9s is a terminal-based UI (aka kubectl clown suit), to manage Kubernetes clusters that drastically simplifies navigating, observing, and managing your applications in K8s, including Custom Resources like the InterSystems Kubernetes Operator (IKO) and ArgoCD Applications. If you are about to take your CKD, CKA, or CKS, leave k9s well enough alone for awhile as the abstraction to kubectl will become the standard for navigating the cluster and you will undoubtedly become estranged to the extended flags of kubectl and bomb the exam.
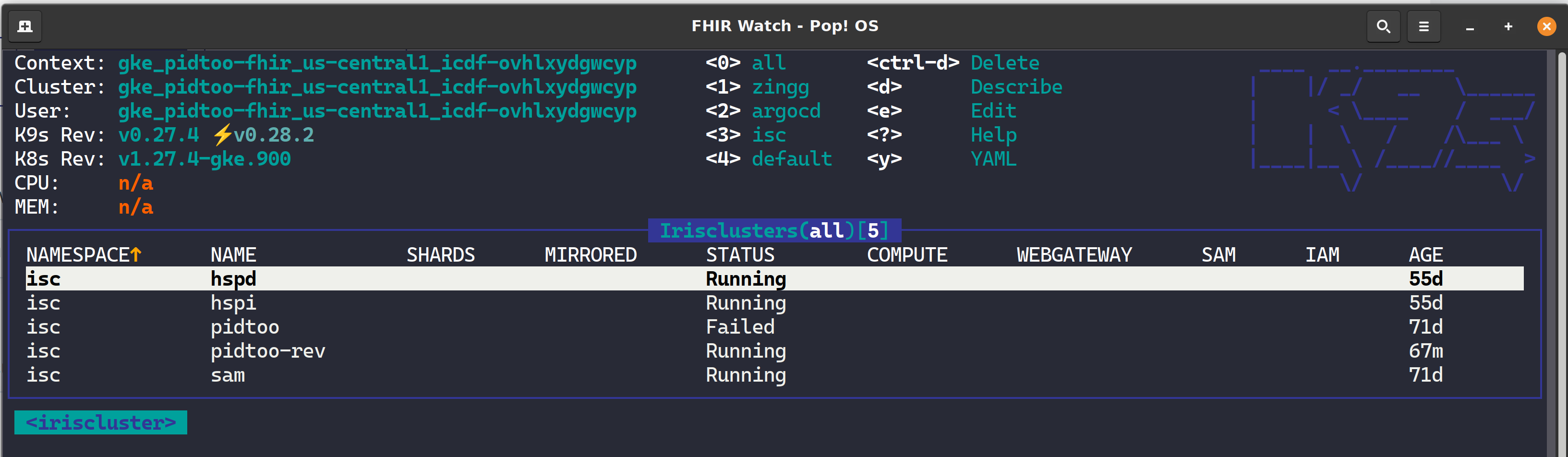
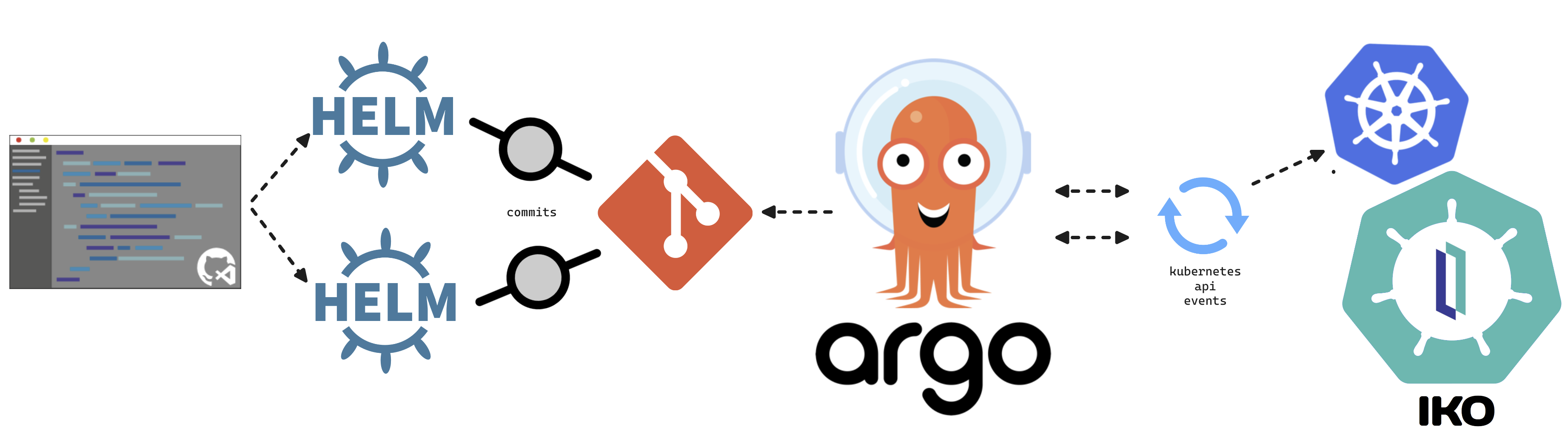
This article will cover turning over control of provisioning the InterSystems Kubernetes Operator, and starting your journey managing your own "Cloud" of InterSystems Solutions through Git Ops practices. This deployment pattern is also the fulfillment path for the PID^TOO||| FHIR Breathing Identity Resolution Engine.
Git Ops
I encourage you to do your own research or ask your favorite LLM about Git Ops, but I can paraphrase it here for you as we understand it.

Summary
A Quick start to include InterSystems IRIS Tables in Data Build Tool using Python.
It uses the sqlalchemy plugin with sqlalchemy-iris which enables the iris strategy for duckdb as a source for a project.
EDIT: If you stumbled here on Google Geuse for "iris dbt", your best bet is to checkout dbt-iris for the native adapter implementation that follows guidelines.
Im out of town for the Python meetup in Cambridge, but will submit to the InterSystems Python Programming Contest starting in September.
|
This post backs the demonstration at Global Summit 2023 "Demos and Drinks" with details most likely lost in the noise of the event. This is a demonstration on how to use the FHIR SQL Capabilities of InterSystems FHIR Server along side the Super Awesome Identity and Resolution Solution, Zingg.ai to detect duplicate records in your FHIR repository, and the basic idea behind remediation of those resources with the under construction PID^TOO|| currently enrolled in the InterSystems Incubator program |
Hello, Is there an equivelant to HS.FHIRServer.Tools.DataLoader.SubmitResourceFiles for bulk fhir data (.ndjson) that exists to import from a local directory in I4H ?
Anybody willing to share a method form the ZPM cli (or othewise) where zpm will "Install package if not already installed?" I would want this to count for updates too I think as I would want to control that too.
The use case is in a CI-CD pipeline, where the pipeline can be used to provision start to state, but for somethings only do once. An example would be I have a package that provisions a fhir package or search parameter in my own way, but doesnt do it again when somebody merges operational code and the pipeline fires again, it would not attempt to load the fhir package again.

A simple production that enables FHIR transaction bundles to be loaded into InterSystems® FHIR® Server via Box and Dropbox. Using the included MFT Connection Components and a 14 liner Custom Business Process, this production will process your transaction bundles to FHIR Resources for immediate consumption with Harry Potter like wizardry. Great for Hackathons, Research and FHIR® Cocktail parties.
![]()
Put the InterSystems FHIR Server to work at the HL7 FHIR Connectathon in Baltimore last weekend, posting bundles, getting all RESTy with resources, and interrogating the Vulcan Implementation Guide We straddled the Real World Data (RWD) and Schedule of Activity (SoA) projects for Vulcan IG folks moving the ball forward connecting clinical research and healthcare data.
Was at an HL7 Connectathon over the weekend and got in a scramble that headed us in the direction of trying out Preview 4 for I4H and found that the USER namespace, and subsequent namespaces created do not have any mappings included with them.
2022.1.0.209.0 - Our Previous working version
.png)
2022.3.0I4HFHIR (Build 4093U) - Preview 4
Anybody else seeing this?
In most cases we provision with apis like:
zn "FHIRDB" Do ##class(HS.FHIRServer.Installer).InstallNamespace()
Im playing whack a mole importing an IG (which is a fairly typical exercise with fhir packages) through FHIR packages, and getting at some parts I cant seem to work around with some store errors...
Im getting MAXSTRING on `hl7.terminology.r4`:
Saving hl7.terminology.r4@3.1.0
Load Resources: hl7.terminology.r4@3.1.0
Resource Used in Multiple Packages: http://terminology.hl7.org/CodeSystem/dicom-audit-lifecycle|20100826(hl7.fhir.r4.core@4.0.1,hl7.terminology.r4@3.1.0)
Set sc=rsrc.%Save() Throw:('sc) ##class(%Exception.StatusException).ThrowIfInt
^
errupt(sc)
<THROW>zaddPackageResources+74^HS.FHIRMeta.Load.NpmLoader.1 *%Exception.SystemException <MAXSTRING> %SaveData+28^HS.FHIRMeta.Storage.Rsrc.1 |
How to include IRIS Data into your Google Big Query Data Warehouse and in your Data Studio data explorations. In this article we will be using Google Cloud Dataflow to connect to our InterSystems Cloud SQL Service and build a job to persist the results of an IRIS query in Big Query on an interval. If you were lucky enough to get access to Cloud SQL at Global Summit 2022 as mentioned in "InterSystems IRIS: What's New, What's Next", it makes the example a snap, but you can pull this off with any publicly or vpc accessible listener you have provisioned instead. |
Wanted to have a FHIR Story in the back pocket to share with the participants on a dead simple series of calls against the FHIR Server for anybody in the mindset of emitting metrics from a device to FHIR.

Presentation:
https://docs.google.com/presentation/d/1AY8_P7qEZe5b_3DVJGqWnVlBbNubQdk…
Postman Collection:
https://www.postman.com/brighstreetgroup/workspace/mit-grand-hack-2022/…
Upgraded IRIS/Connect to 2022.1 and /api/atelier no longer works through a Web/CSPGateway. Also upgraded the Web/CSPGateway to version WebGateway-2022.1.0.152.0 on Ubuntu and HTTPD Server version: Apache/2.4.29 (Ubuntu) with no luck as well.
It doesnt seem to matter if I add /api/atelier or /api/monitor to the enabled applications list, these routes do not make it back to the instance, however /csp, /csp/sys still does.
Am I missing a step in this upgrade process to serve these apps through Web/CSPGateway in the new kit version?
We have an implementation with a bunch of users, and a bunch of namespaces, both of which are added and removed frequently, and the users have restrictive perms in the namespaces (lets just say, not %All)... and the users are utilizing the VSCODE extension for development.
Per the instructions and the user experience, we need to run:
GRANT EXECUTE ON %Library.RoutineMgr_StudioOpenDialog TO ${user}For ... each Namespace, and additionally %SYS for Web Apps.
If anybody could give me some insight on creating the %All Namespace programmatically I would appreciate it. There are quite a few posts I found that reference its creation using the UI, but I cant seem to get passed some validations with any form of the below:
Set Properties("Globals")="%DBDEFAULT"
//Set Properties("Library")="IRISLIB"
Set Properties("Routines")="%DBDEFAULT"
//Set Properties("SysGlobals")="IRISSYS"
//Set Properties("SysRoutines")="IRISSYS"
Set Properties("TempGlobals")="IRISTEMP"
Set tSC=##class(Config.Namespaces).Create("%All",.Properties)The documentation for Config.
 Want a commercial grade FHIR® Implementation included in your micro service ecosystem and barely have enough time to fill out your Health plan elections?
Want a commercial grade FHIR® Implementation included in your micro service ecosystem and barely have enough time to fill out your Health plan elections?
Here is a quick way to invite the InterSystems® FHIR®Accelerator Service to your Kubernetes Microservice party for immediate use. The solution uses Nginx proxy ninja moves to get the job done. Though rustic and bound to create some technical arguments, I am pretty happy with the results until this community tells me otherwise, so FHIR® away as they say but it would be great if you heard me out first.
Deploying InterSystems HealthShare code, supporting lookups and artifacts like ssl certs, keys etc is relatively straight forward using Gitlab Runners. Not only does this approach enable managing the code base and deploying with git type workflows, but it also lends to a speedy recovery and repeatable environments for some implementations.
We are ridiculously good at mastering data. The data is clean, multi-sourced, related and we only publish it with resulting levels of decay that guarantee the data is current. We chose the HL7 Reference Information Model (RIM) to land the data, and enable exchange of the data through Fast Healthcare Interoperability Resources (FHIR®).
We are also a high performing, full stack team, and like to keep our operational resources on task, so managing the underlying infrastructure to host the FHIR® data repository for purposes of ingestion and consumption is not in the cards for us.

Table of Contents
Hello Newman
So given the STAR method on how to introduce Newman with this effort, here it goes.
SITUATION
We are facing a Production implementation of a FHIRIS® Resource Server, fronted with a robust API Manager, Web Gateways for speed and availability, though not entirely relevant, the implementation is on Public Cloud, namely, Amazon Web Services.
If you are looking for a slick way to integrate your IRIS solution in the Amazon Web Services ecosystem, server less application, or boto3 powered python script, using the IRIS Python Native API could be the way to go. You don't have to build out to far with a production implementation until you'll need to reach out and get something or set something in IRIS to make your application do its awesome sauce, so hopefully you will find value in this article and build something that matters or doesn't matter at all to anybody else but you as that is equally important.

Im usually pretty good at ComplexMaps and implemented a couple, but I have one that is stumping me on how I can implement it. My problem is I have no real "leading data" to key off of and need something else...
It goes a little bit like this:
D123456 THING1 THING2 THING3 THING4
D789101 THING1 THING2 THING3 THING4
T THINGX THINGZ
In looking at the above, I need two record maps, one for the "D" rows (repeating) , and one for the "T" row, which is basically the trailer.
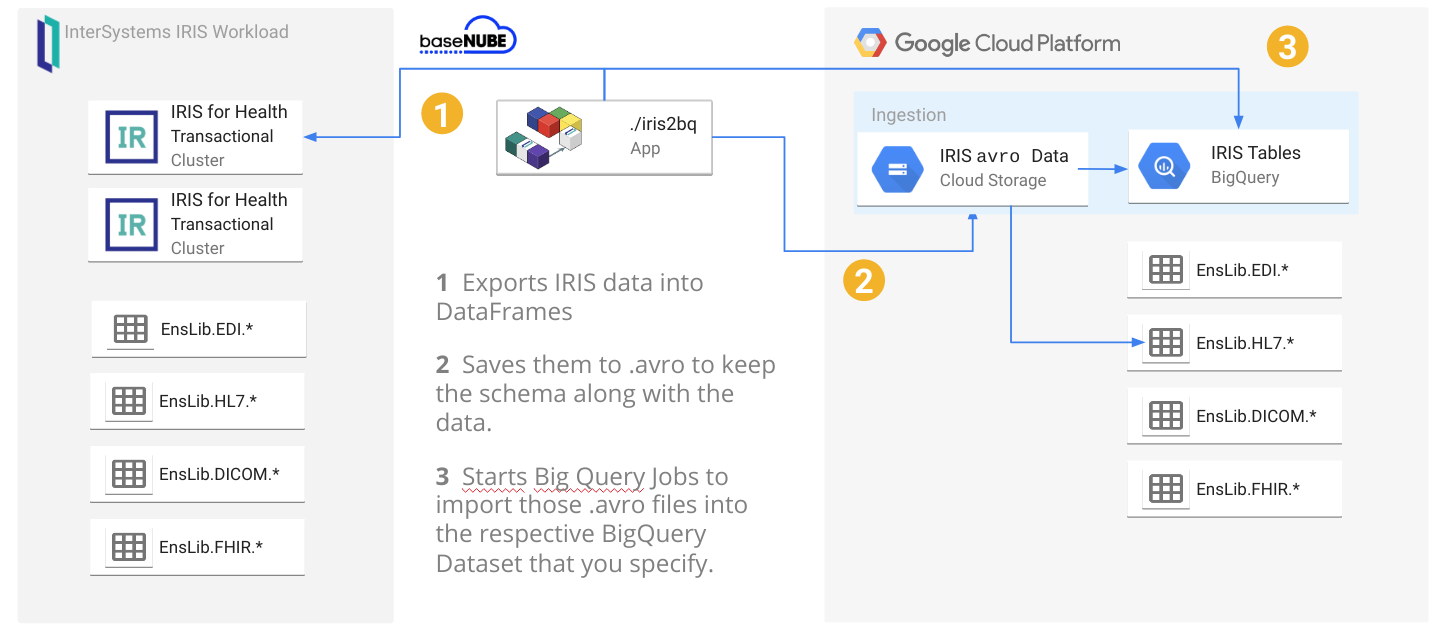
Loading your IRIS Data to your Google Cloud Big Query Data Warehouse and keeping it current can be a hassle with bulky Commercial Third Party Off The Shelf ETL platforms, but made dead simple using the iris2bq utility.
Let's say IRIS is contributing to workload for a Hospital system, routing DICOM images, ingesting HL7 messages, posting FHIR resources, or pushing CCDA's to next provider in a transition of care. Natively, IRIS persists these objects in various stages of the pipeline via the nature of the business processes and anything you included along the way. Lets send that up to Google Big Query to augment and compliment the rest of our Data Warehouse data and ETL (Extract Transform Load) or ELT (Extract Load Transform) to our hearts desire.
A reference architecture diagram may be worth a thousand words, but 3 bullet points may work out a little bit better:
- It exports the data from IRIS into DataFrames
- It saves them into GCS as
.avroto keep the schema along the data: this will avoid to specify/create the BigQuery table schema beforehands. - It starts BigQuery jobs to import those
.avrointo the respective BigQuery tables you specify.
Hello,
Has anybody successfully taken a recordmap business service to business operation integration and converted it into a Batch pipeline? I am trying to wrap my head around the documentation (https://cedocs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=EGDV_recmap_batch) and cant seem to get this to the finish line, what I end up with is publishing a batch record with exactly one record in it in real-time while when I really want to excersise the RollOver limit of about 50 records. I have no requirement for fancy headers or trailers, just multiple records.
Hello,
I am pretty stuck here and would appreciate any help or advice on an approach to this...
I have a single claim file, ingested that has 7 claims inside of it, I am pulling each claim out based on a qualifier, then want to remove all of the others and do something with the one that is left over.
My problem is I cant seem to figure out how to Remove the Claims programatically...
ClassMethod PCRemoveClaim(pTargetDocument As EnsLib.EDI.X12.Document, tCount As %Numeric) As %Status
{
Set tStatus = $$$OK
Try {
Set tStatus =
Hello,
Looking for some help on how I actually set the properties to enable tracing for %Net.SSH.Session ?
The doc is here:
https://docs.intersystems.com/latest/csp/documatic/%25CSP.Documatic.cls…
The values look bitwise in their defaultness and I cant seem to figure out how to enable it in my object (or if I am going about this wrong altogether). I am troubleshooting an elusive ssh error: unable to exchange encryption keys in a catch at the moment.
Would appreciate a clue if anybody has experience with it... thank you.
-Ron