IRIS Tables in dbt (Data Build Tool) with Python

Summary
A Quick start to include InterSystems IRIS Tables in Data Build Tool using Python.
It uses the sqlalchemy plugin with sqlalchemy-iris which enables the iris strategy for duckdb as a source for a dbt project.
EDIT: If you stumbled here on Google Geuse for "iris dbt", your best bet is to checkout dbt-iris for the native adapter implementation that follows dbt guidelines.
Im out of town for the Python meetup in Cambridge, but will submit to the InterSystems Python Programming Contest starting in September. Sucks I will miss it, wanted to connect with Thomas Dyer and see how close I got, but this is my virtual hail to the event through the community.
It is a quick start at best, for those perusing it, and even for myself to build upon in the upcoming months.
Disclaimers
I am unsure this is solution is the best path to accomplish things, but it is a tested path.
I am not a dbt expert, but use dbt-core in cicd pipelines and its apparent in bash history on a daily basis, so I walk around like I eventually will be.
Props
Made possible by SQLAlchemy-iris by Dmitry Maslennikov and a follow up post by Heloisa Paiva to express in a few lines how great it is.
Also, duckdb is fun software, wicked fast, and a data lake for your /tmp folder. Ducks are cool, Geese are not.
Setup
- Deploy IRIS Cloud SQL
- Pythons
- Github
- dbt Configuration
- Validate Setup
So we used InterSystems IRIS Cloud SQL through the Early Access Program to demonstrate things, it provisioned super fast and anything to avoid local docker these days makes for a happy brogrammer.
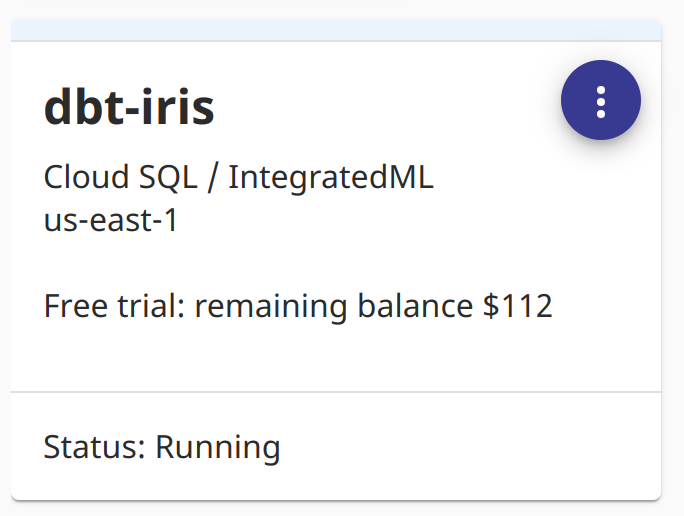
Looks like I got a roll of 112 ones left on my trial.
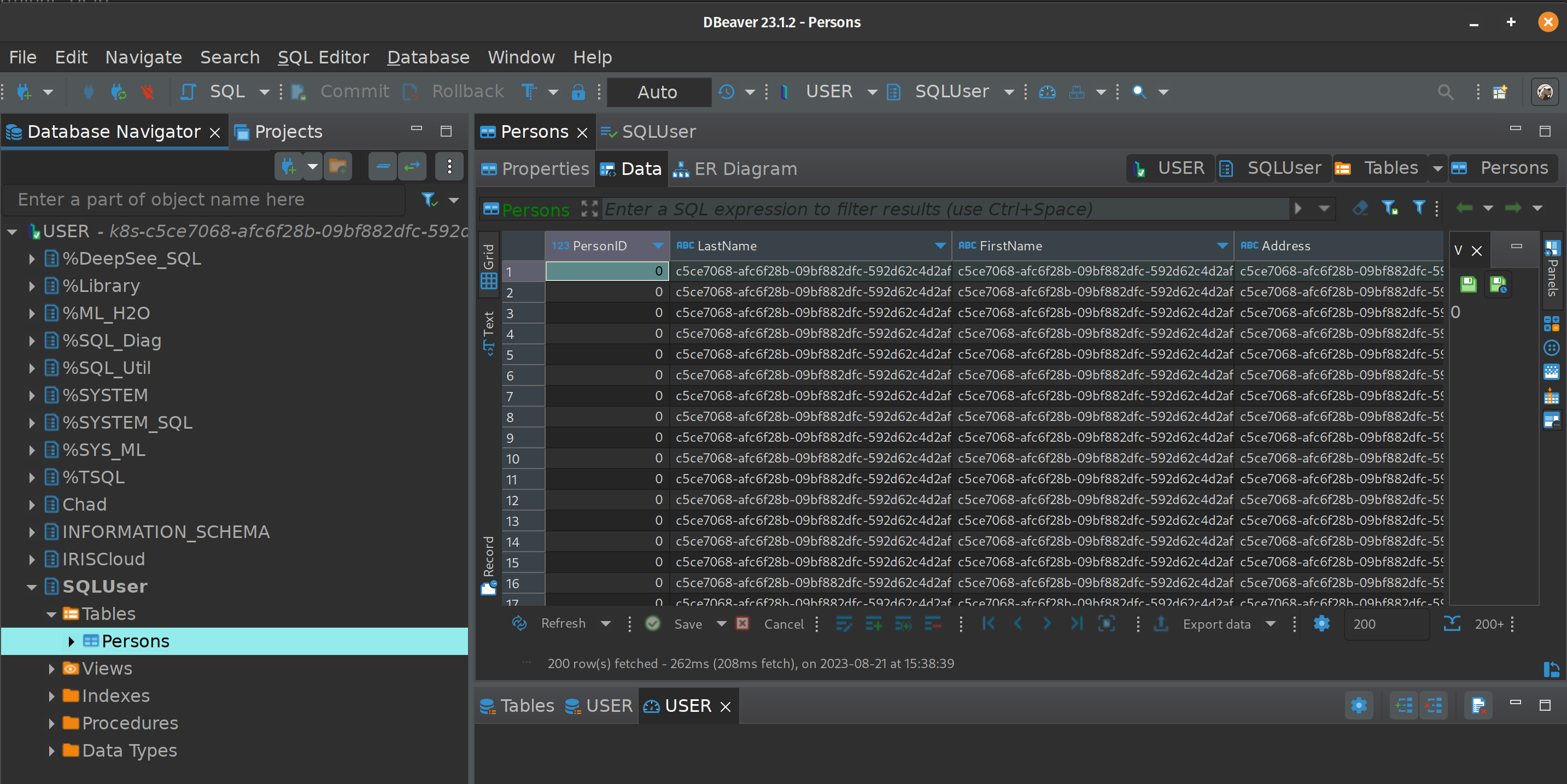
For purposes of the tables referenced in the below, I used DBeaver to create a Table "Persons" in the "SQLUser" schema and loaded it up with a bunch of worthless data.
Pythons
Install the following python stuff, I am running python3.8, and everything seems to work fine.
pip install dbt-core
pip install dbt-duckdb
pip install sqlalchemy-iris
Github
Optional, but not really if you are serious about things.
https://github.com/sween/dbt-duckdb-iris
dbt Configuration
Inside the git repository folder:
dbt init iris_project
Setup your profile, if you are familiar with .aws credentials for your system, this is similar, but for the secrets connecting to your sources.
In ~/.dbt/profiles.yml
Construct your sqlalchemy URI from you connectivity details in IRIS SQL, and populate it like so:
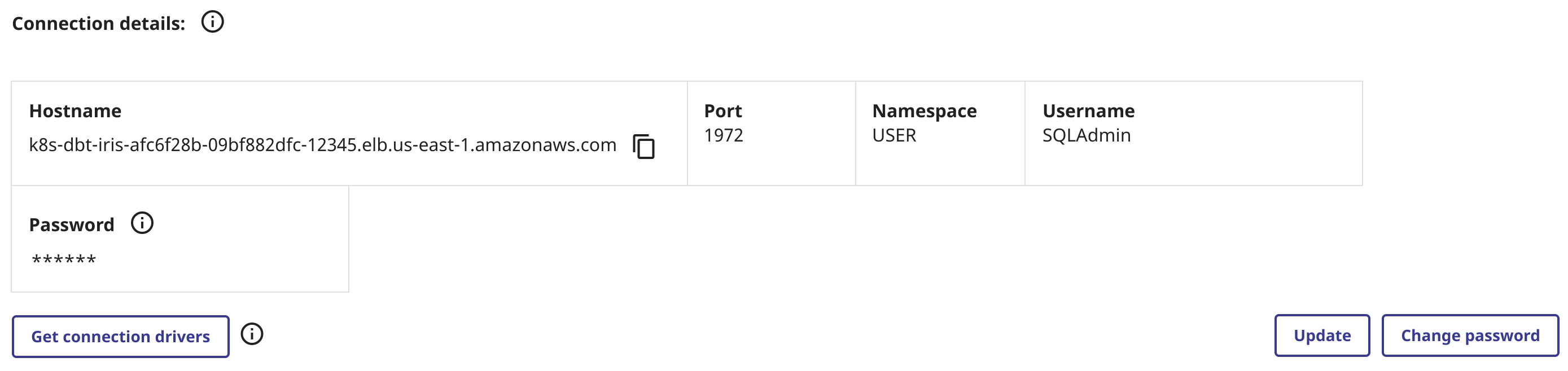
dbt_iris_profile:
target: dev
outputs:
dev:
type: duckdb
database: dbt
schema: dev
path: /tmp/dbt.duckdb
plugins:
- module: sqlalchemy
alias: sql
config:
connection_url: "iris://SQLAdmin:PineapplePercussions@k8s-dbt-iris-afc6f28b-09bf882dfc-12345.elb.us-east-1.amazonaws.com:1972/USER"
Modify the dbt_project.yml in the root of the dbt project.
name: 'iris_project'
version: '1.0.0'
config-version: 2
# This setting points to the "profile" we built from previous step.
profile: 'dbt_iris_profile'
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
clean-targets:
- "target"
- "dbt_packages"
models:
iris_project:
example:
+materialized: view
vars:
db_name: sql
Two more files to go, lets declare our models\schema.yml first:
version: 2
models:
- name: my_first_dbt_model
description: "A starter dbt model"
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_null
- name: my_second_dbt_model
description: "A starter dbt model"
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_null
sources:
- name: dbt_iris_source
database: dbt
schema: SQLUser
tables:
- name: Persons
identifier: Persons
config:
plugin: sql
save_mode: overwrite
query: "SELECT * FROM SQLUser.Persons"
And last but not least, a Python model in models/Persons.py
def model(dbt, session):
dbt.config(materialized="table")
persons_df = dbt.source("dbt_iris_source", "Persons")
return persons_df
dbt Shampoo
Now let's test and see if we can reach IRIS out there in us-east-1 of sorts.
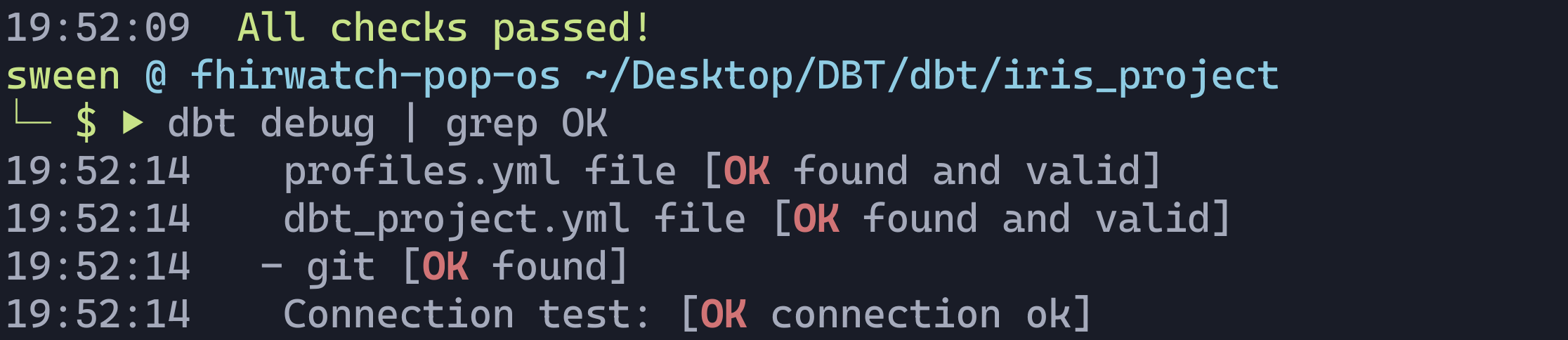
dbt debug
If all goes well, and we are able to connect to IRIS Sql Cloud, you should see something like the following:
Next up, is to actually run the project.
dbt run
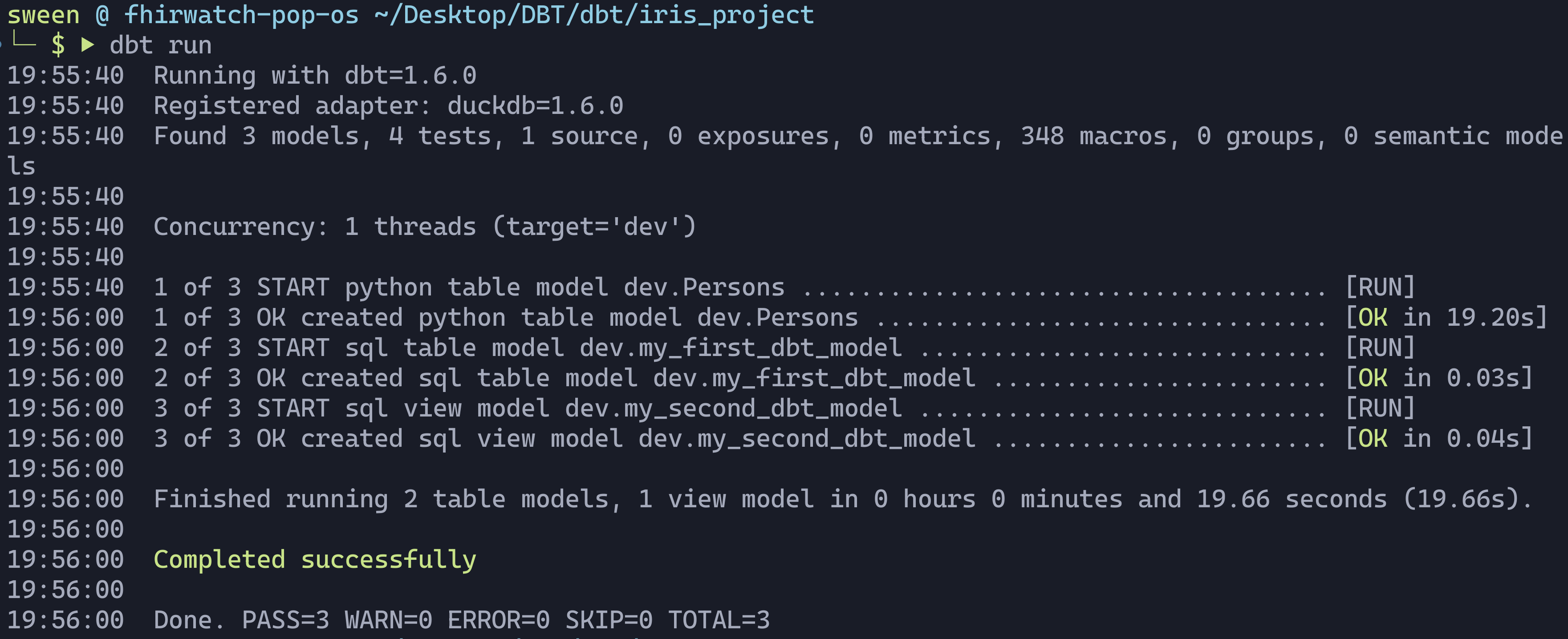
Lets generate the clown suit and take a look at our work.
dbt generate docs
dbt serve docs
On http://0.0.0.0:8080, you'll see the auto generated docs.
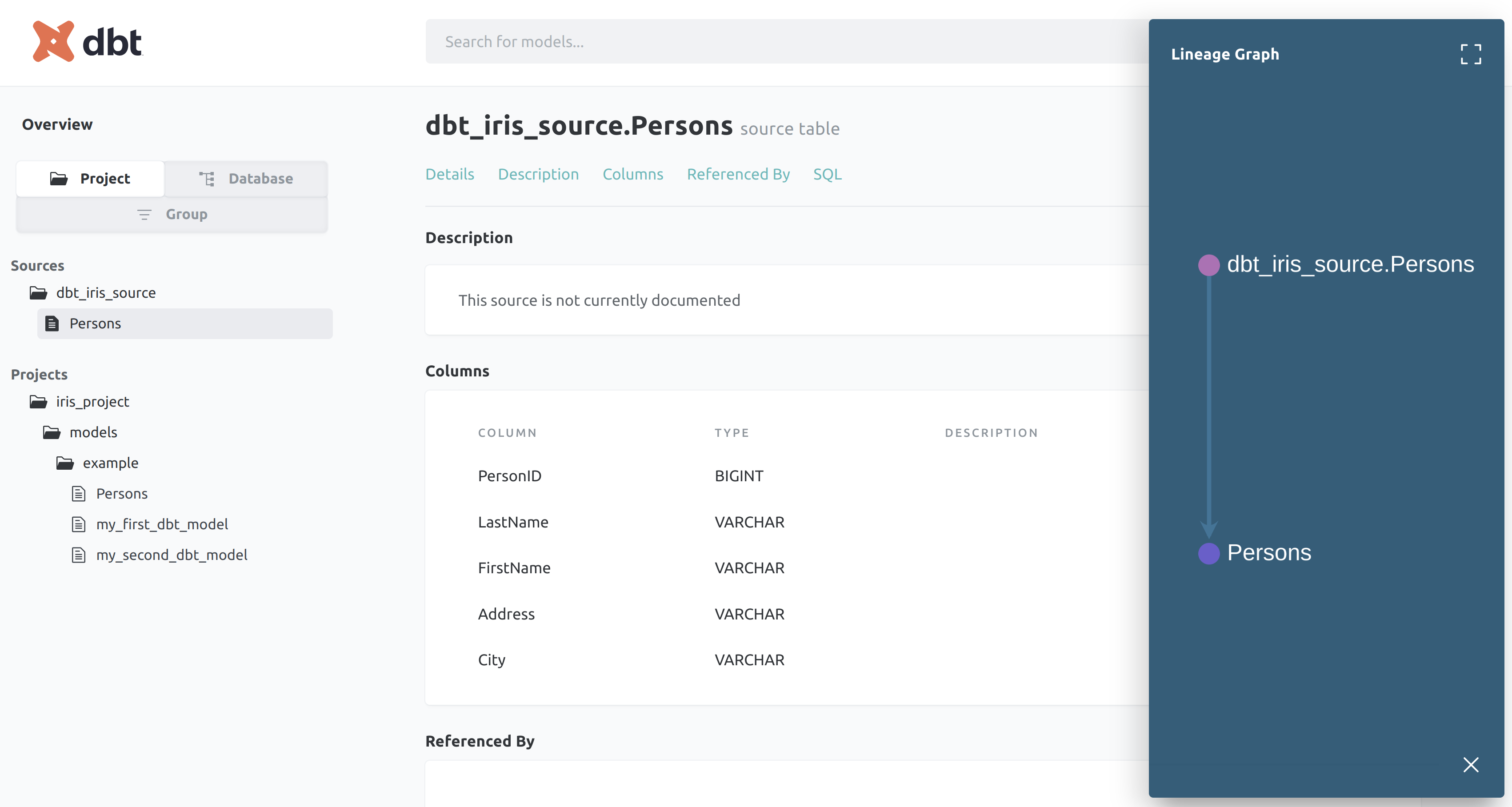
BOOM!!!!
Need some proof we connected to IRIS Sql Cloud and pulled down the Persons data?
Fire up the duckdb cli and query the dev.Persons table.
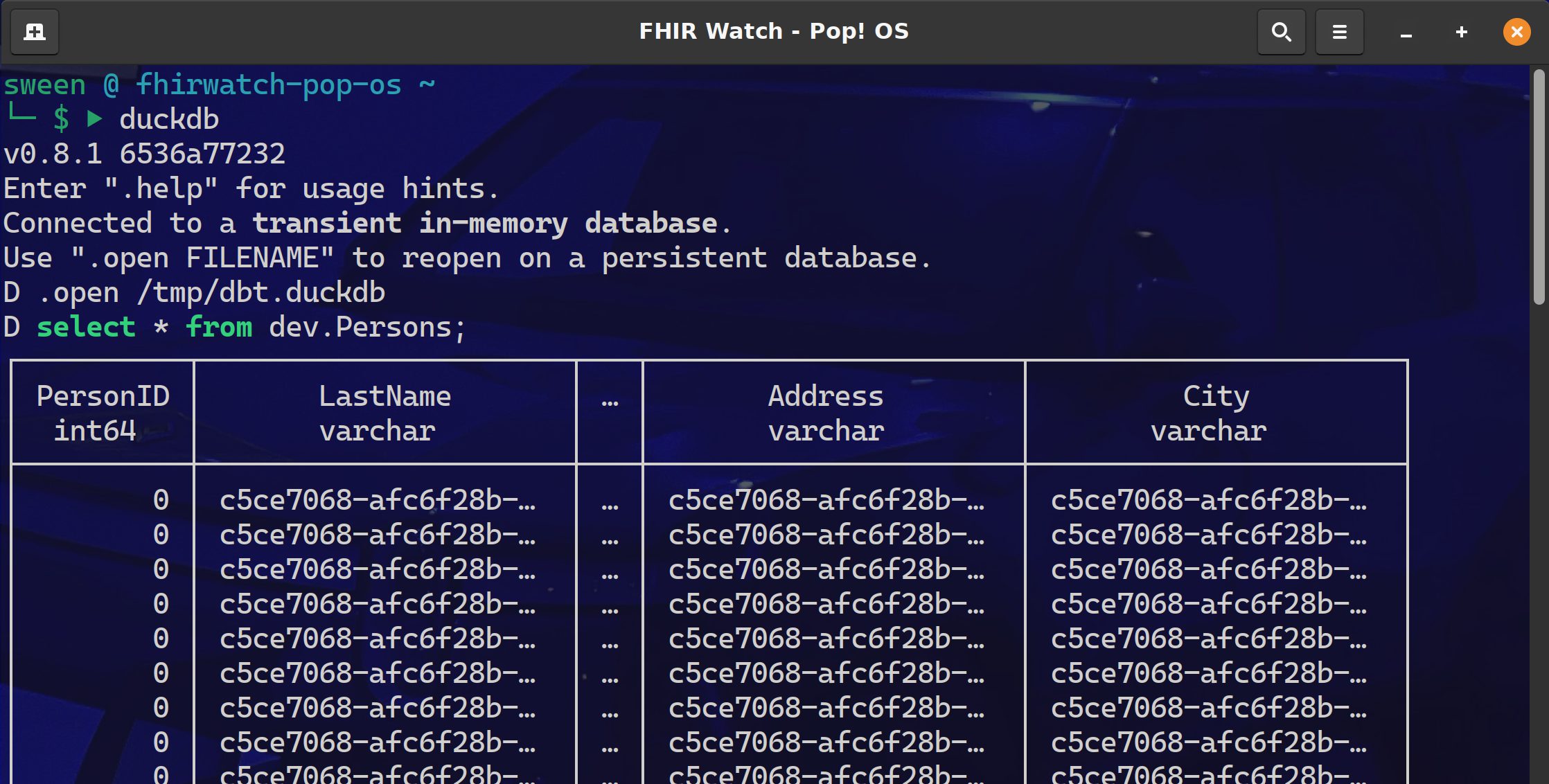
dbt
I am currently down with dbt (yeah you know me) using dbt-core to about 25% of its full potential and pretty much all in and most likely headed to dbt cloud. After a project that implemented Single Table DynamoDB, with a transform to BigQuery, it became apparent that there MUST be a better way to:
-
Share the project Github was not enough, there needed to be more ways to share the tribal knowledge and just not show up that day for somebody else to check it out and run.
dbtshines here withdbtshampoo,dbt run && dbt testin pipelines. -
Changes and Tribal Knowledge Source control gave us the code lineage, but
dbtkept the tribal knowledge right there along side of it, so changes and additions could be made without fear of breaking things. -
Testing My experience with some data projects is they get handled with the testing rigor of teams that build web apps and it is not a fit. Though the target data powers the UI (where the testing occurred), it only surfaced a fraction of the data complexity and raised a ton of bugs from the datawarehouse side of the project.
Very Helpful Stuff:
127.0.0.1
Comments
Ron, that’s nice that you discovered dbt, I’ve implemented support for IRIS, directly without sqlalchemy
quite some time ago, have a look https://github.com/caretdev/dbt-iris
and we had a session on last Summit, about using dbt in a MLonFHIR project
Thats really good work, even follows the adapter guidelines. Pointing the community your way before preceding down the post.
Looks like my process for pre-post searches to look for duplicate content needs a re-think:
https://community.intersystems.com/smartsearch?search=dbt
https://openexchange.intersystems.com/?search=dbt&sort=r
These were goose eggs, so I proceeded down the path... however glad I played with duckdb and the plugins anyway.